Larrabee CPU 코어와 Pentium 코어 비교
Intel은 새로운 명령 "Larrabee NI (New Instructions)"의 첫 번째 구현인 CPU 아키텍처 "Larrabee (라라비)"는 심플한 IA-32 (x86) 계 CPU 코어를 기반으로 개발했다. 이미 알려진대로, Intel은 Larrabee CPU 코어를 Pentium (P5)을 출발점으로 개발했다고 한다. Intel이 SIGGRAPH, Intel Developer Forum (IDF), Hotchips 등에서 공개한 Larrabee 아키텍처 차트를 보면, Pentium을 베이스로 한 것을 잘알 수 있다.
아래 그림은 Larrabee CPU 코어를 Pentium과 비교한 차트이다. 그림에서 파란색 부분은 Pentium에서 유래한 유닛 군, 녹색 부분은 Larrabee로 새롭게 추가되거나 확장된 유닛 군이다. 최대의 포인트는 Larrabee NI의 벡터 명령에 대응하는 벡터 유닛과 벡터 레지스터가 추가 된 것. 사실 스칼라 유닛 측에도 벡터 로드 / 스토어 명령어 및 캐시 제어 명령 등의 Larrabee NI의 몇 가지 새로운 명령이 추가되었다.
스칼라 레지스터도 멀티 스레딩 지원을 위해 4배로 확장되고 L1 데이터 캐쉬와 L1 명령 캐쉬도 각각 멀티 스레딩을 위해 4배의 크기가 되었다. 레지스터 갯수도 멀티 스레딩을 위해 확장된 것이다. 또한 스레드 Dispatcher가 L1 명령 캐쉬 앞에 추가되었다. Pentium에서는 온칩에 없던 L2 캐시가 내장되고 FSB가 아닌 CPU 코어의 커뮤니케이션을 위한 링 스톱이 추가되었다.
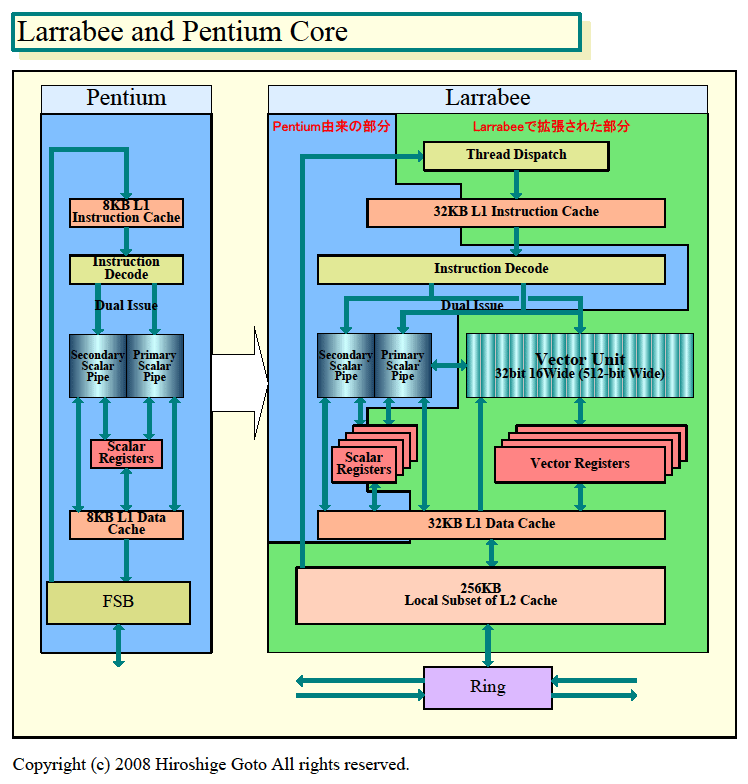
Larrabee와 Pentium 코어의 비교
Pentium을 계승하는 Larrabee의 기본 구조
이렇게 보면, Larrabee CPU 코어는 형태는 크게 바뀌어 있지만, 골격은 Pentium을 계승하고 있는 것을 알수 있다. 예를 들어, CPU 아키텍처의 근간인 명령 발행 구조는 Pentium의 2명령 발행 In-Order 실행을 계승하고 있다.
Larrabee는 실행 파이프 라인 자체는 스칼라 유닛이 2개에 벡터 유닛이 1개로 총 3 파이프가 있다. 그러나 동시에 발행할 수 있는 명령은 Larrabee에도 여전히 2 명령으로, 벡터 유닛은 1명령 / 사이클 처리량이다. 스칼라 명령은 2명령을 병렬 실행할 수 있지만 벡터 명령은 아니다.
"동시에 실행할 수 있는 명령어는 2 명령어로 벡터 유닛은 1명령 밖에 실행할 수 없다. 그러나 벡터 유닛이 벡터 연산 명령을 실행하는 것과 병행하여, 스칼라 유닛이 벡터 로드 명령을 실행한다. 따라서 벡터 연산 때도 실제로는 2 명령어를 거의 실행하는 형태가 될 것 "이라고 Intel에서 Larrabee 아키텍처의 개발을 담당하는 Larry Seiler 씨 (Senior Principal Engineer - Graphics System Architect, Intel)는 설명한다.
벡터 유닛에 명령 발행 포트는 스칼라 유닛의 명령 발행 포트와 공유되어 있다고 한다. 2개의 스칼라 유닛 중 한쪽은 풀 세트로, 다른 하나는 하위 세트로 되어 있다. 일반적으로 생각하면, 풀 세트의 주 스칼라 파이프와 벡터 유닛을 병렬로 동작 할 수 있도록 명령 발행 포트를 배치 할 것이다. 따라서 벡터 유닛과 보조 스칼라 파이프 명령 발행 포트는 공유되어 있다고 추측된다. 그러나 HotChips의 설명 그림에서는 주 및 보조 명령 발행 포트는 벡터 유닛 측에 뻗어있는 것처럼 그려져 있었다. 따라서 그림에서는 두 개의 포트가 각각 벡터 유닛과 명령 발행 포트를 공유하는 형태로 그리고 있다.
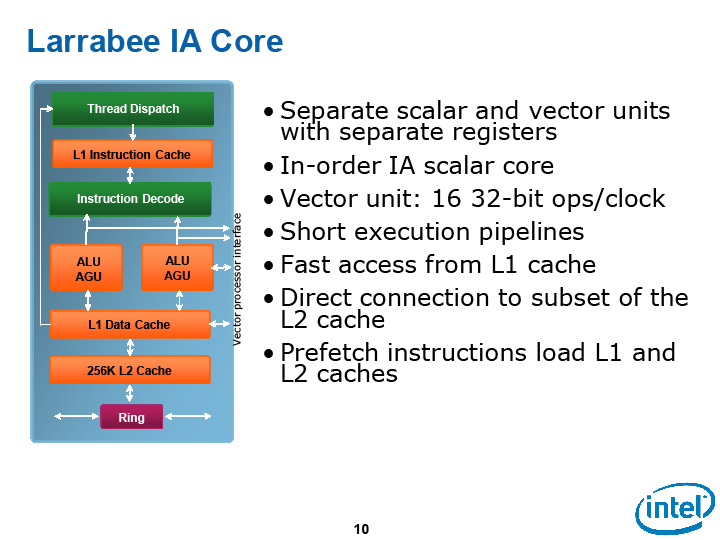
Larrabee CPU 코어
SSE와 다른 Larrabee의 벡터 유닛
스칼라 유닛은 기존의 Pentium과 매우 유사하다. Pentium과 마찬가지로 파이프 라인 단수가 얕고, 트랜지스터 수가 적은 구성이라 한다. 또한 파이프 라인은 Pentium와 마찬가지로 듀얼로 구성되어 있다. 따라서 최대 2 개의 스칼라 명령을 동시에 실행할 수있다.
그러나 2개의 파이프는 같은 것이 아니라 주 파이프 및 보조 파이프로 역할 분담을 한다. 주 파이프는 Larrabee 스칼라 명령을 모두 포함하는데 보조 파이프는 비교적 간단한 명령어만을 지원하는 일부가 된다. Larrabee의 벡터 로드 / 스토어 명령 등은 모두 파이프에 구현되어 있는것 같다.
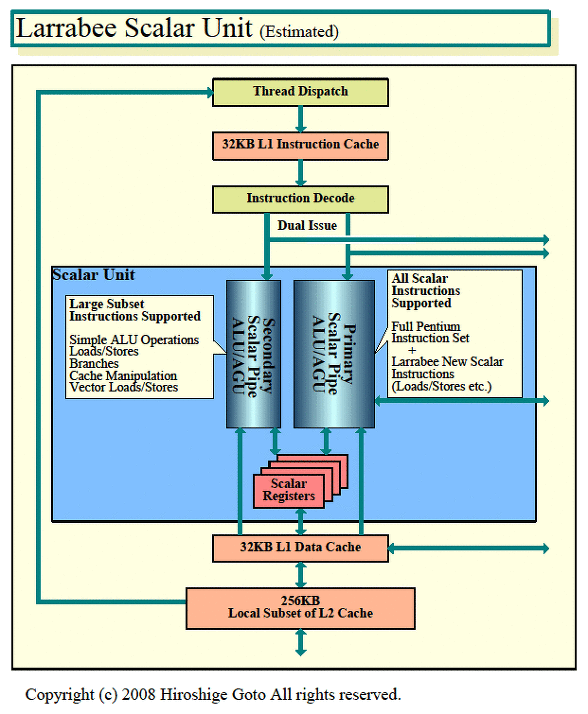
Larrabee의 스칼라 유닛
벡터 유닛의 차트는 Intel에서도 SIGGRAPH / IDF 때 슬라이드와 HotChips 때 슬라이드가 크게 달랐다. 왼쪽이 IDF 때, 오른쪽이 Hotchips 때이다. 두 슬라이드를 참조하면서 스칼라 유닛과 대조 할 수 있도록 임시로 만든 것이 아래의 그림이다.
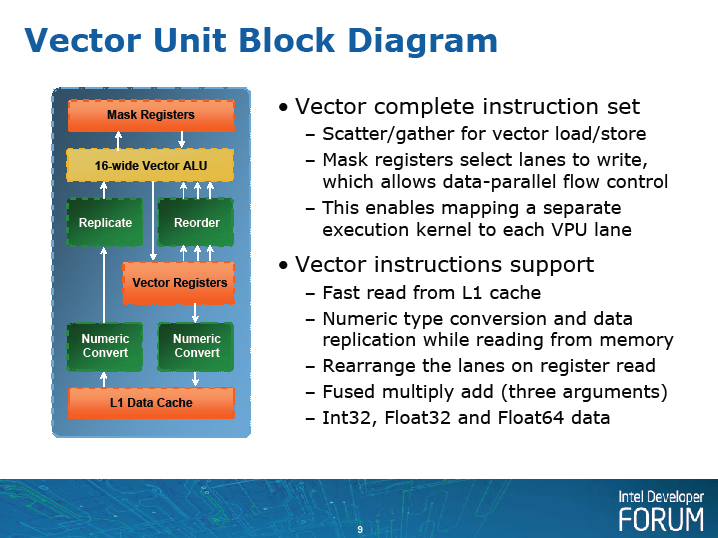
벡터 유닛의 차트 왼쪽이 IDF 때 (원문에는 두 그림이 좌우로 배치)
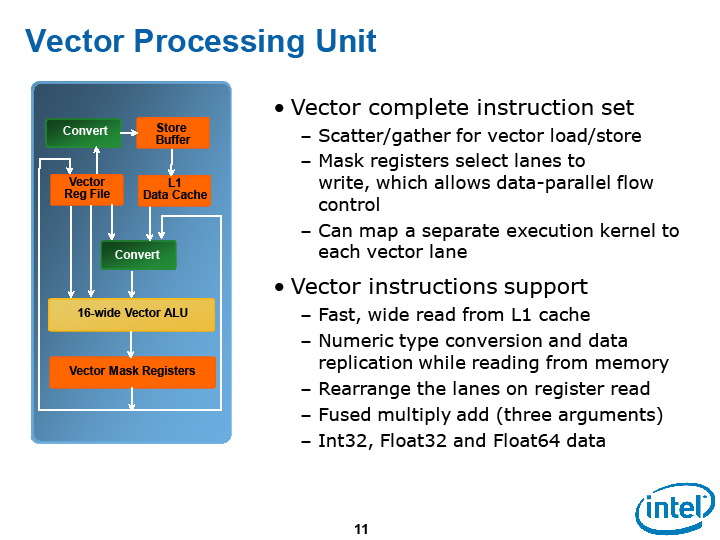
벡터 유닛의 차트. 오른쪽이 Hotchips 때 (원문에는 두 그림이 좌우로 배치)
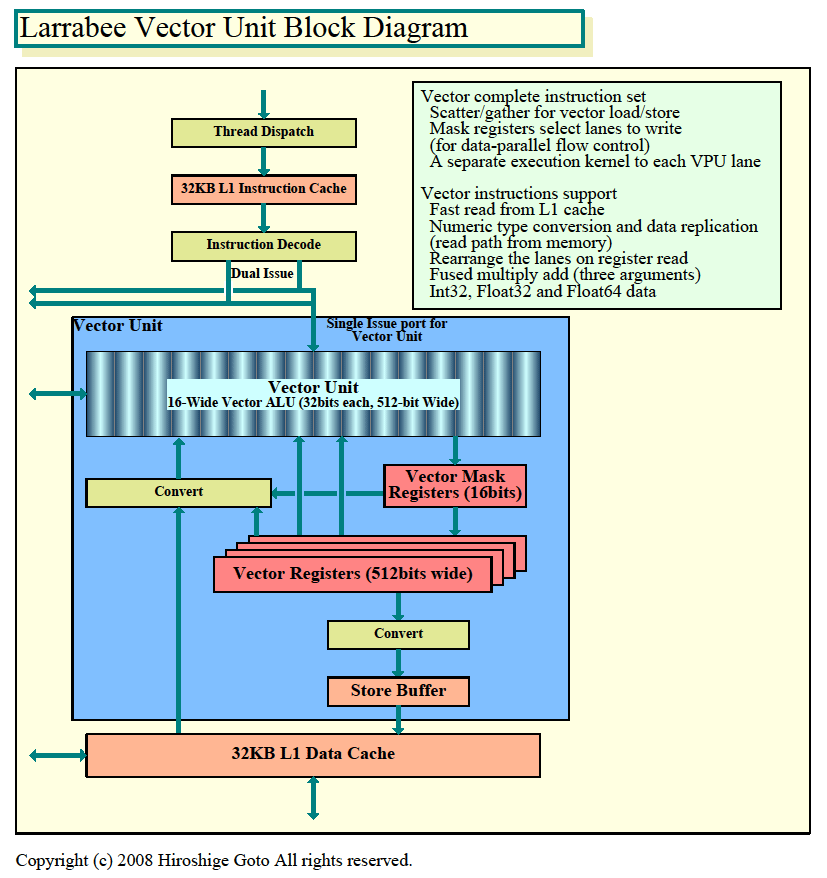
Larrabee 벡터 유닛의 다이어그램
Intel은 지금까지도 SSE 등 짧은 벡터 유닛을 CPU에 실장해 왔다. Larrabee의 벡터 유닛은 벡터장이 SSE의(128bit, AVX 256bit) 4배 버전이지만 근본적인 차이점도 많다. 특히 눈에 띄는 것은 마스크 레지스터를 갖추고 있는 것이다. 마스크 레지스터는 벡터 프로세서의 각 레인에 1bit 씩 대응하는 16-bit 폭의 레지스터이다. 이것이 중요한 역할을 하고 있다.
마스크 레지스터에서 벡터 조건 분기와 로드 / 스토어가 가능
Larrabee의 벡터 유닛은 벡터 조건 분기 명령을 실행한 경우, 마스크 레지스터에 따라 레지스터와 메모리에 기록을 레인 단위로 마스크 된다. 예를 들면, Larrabee의 16레인 중 레인 0은 벡터 레지스터에 기록하지만 레인 1은 기록하지 않는다 같은 제어가 있다. 512-bit 폭의 벡터 레지스터 (또는 메모리)는 16개의 32-bit 데이터 슬롯으로 구성되는데, 각 레인에 대응하는 32-bit의 데이터 슬롯 단위로 쓰기를 제어 할 수있다.
따라서 프로그램 안에 벡터 조건 분기가 있으면 벡터 유닛의 각 레인에서 각각 조건 판정에 의해 다른 분기 경로를 실행할 수 있다. "if-then-else"형의 컨트롤을 레인 단위로 실행할 수 있다. 레인 0은 조건이 성립하여 명령 경로 B로 분기하지만 데이터 1은 조건이 성립하지 않기 때문에 명령 경로 A를 그대로 실행하는 경우가 발생한다. 벡터 유닛은 조건 판정에 의해 마스크 레지스터 안의 각 레인에 대응하는 bit를 세운다. 마스크 레지스터에 의해 유효한 경로의 결과만을 레지스터에 기록 할 수 있도록 한다. 예를 들어, 레인 0은 마스크가 1이므로 명령 경로 A의 결과는 레지스터에 기록되지 않지만 명령 경로 B의 결과는 기록되는 식이다. 따라서 16레인 각각 다른 명령 경로를 실행할 수 있다. 또한 마스크 레지스터가 16레인 모두 0 또는 1의 경우는 한쪽의 명령 경로만 실행되고 필요없는 명령어 경로는 생략된다.
이러한 구조를 가진 Larrabee의 벡터 유닛의 각 레인은 NVIDIA 아키텍쳐에서 말하는 스칼라 프로세서 "SP (Streaming Processor)"의 역할을 하고 있다. NVIDIA의 GeForce 8800/GeForce GTX 200 (G80/GT200) 계 아키텍쳐의 경우 각 프로세서 클러스터 "Streaming Multiprocessor (SM)"가 각각 8 개의 스칼라 프로세서를 내장한다. 8개의 스칼라 프로세서는 벡터로 제어되며, 같은 명령을 실행하는 구조다. 그래서 NVIDIA 아키텍쳐는 벡터 조건 분기가 가능한 8레인 벡터 유닛을 내장한 프로세서라고 표현할 수도있다. 이 점에서 Larrabee와 G80/GT200은 매우 유사하다.
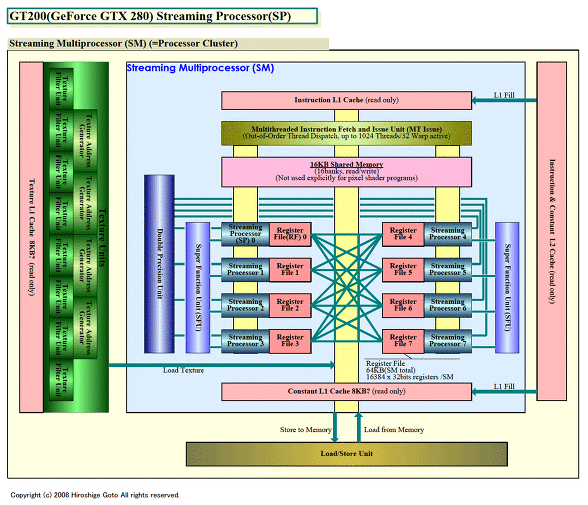
GT200의 Streaming Processor
또한 벡터로드 / 스토어 에도 마스크 레지스터는 사용된다. 예를 들어 ,16-wide의 벡터 레지스터의 각 데이터 블록 대한 데이터의 로드 때 로드되는 데이터 요소를 마스크에 의해 선택할 수 있다.
기존의 Intel의 벡터 유닛인 SSE 유닛은 벡터의 각 레인이 다른 명령 경로를 수행 할 수 없었다. 따라서 엄밀하게 같은 명령을 실행하는 데이터를 팩화 할 필요가 있었다. 예를 들면, 그래픽이라면 RBGA 4 색상 요소를 팩 4-wide 벡터 등에 한정되어 있었다.
그러나 Larrabee 의 벡터 유닛의 경우는 그럴 필요가 없다. 분기를 포함한 보다 폭 넓은 프로그램에 적용 할 수 있다. "루프 벡터 라이제이션에 적용 할 수 있기 때문에 C로 작성된 일반 루프 코드에도 16배 빨라진다. 프로그래머 측이 의식하지 않아도 고속화 가능하다" 라고 게임 프로그래머로 유명한 Tim Sweeney 씨 (팀 스위니 CEO, Founder, Epic Games )는 말한다.
시리얼 코드 안의 루프를 컴파일러 수준에서 전개하고 벡터화해 벡터 유닛에 할당하여 16배의 고속화가 가능하게 된다고 한다. Sweeney 씨는 이러한 장점을 가진 Larrabee의 벡터 유닛 등은 기존의 SSE 타입의 벡터 유닛과 다른 것으로 "New Vectors"라고 부르고 있다.
동적으로 레인의 재구성이 가능한 아키텍처
New Vectors는 최신 GPU와 Larrabee가 포함되지만, 양자간에 큰 차이가 있다. NVIDIA와 AMD (구 ATI)의 GPU 아키텍처는 벡터 스케줄링 등의 제어의 대부분은 하드웨어에서 수행하고 있는 반면, Larrabee는 전체 소프트웨어에서 행하고 있다. 따라서 조건 분기의 효율화로 몇 가지 트릭을 사용할 수 있는 가능성이 있다. Intel도 그 가능성을 시사하고 있다.
벡터 프로세서의 약점은 컨트롤 흐름의 효율이다. 분기를 실행하는 경우에는 분기 경로 A와 분기 경로 B를 모두 실행해야 하므로 명령 단계 수가 증가된다. 따라서 조건 분기 명령으로 처리하는 컴퓨테이션의 입도 "분기 입도 (Branch Granularity)"가 작으면 작을수록 효율적이다. 반면 분기 입도를 크게하면 프로세서가 복잡해져, 벡터 유닛의 단순성의 이점이 없어져 버린다. 프로세서 하드의 효율성과 컨트롤 흐름의 효율성은 주고 받는(트레이드 오프) 관계에 있다.
현재 NVIDIA 아키텍쳐 분기 입도가 32가 된다. 8개의 스칼라 프로세서가 4 사이클에 걸쳐 같은 명령을 실행하기 때문이다. Intel의 Larrabee의 경우는 벡터 폭이 16way이므로 분기 입도는 16이 될 것이다. 그러나, Intel에 따르면, 실제로는 명령 실행 지연 시간을 은폐하기 위해 4 사이클 같은 명령을 실행하도록 소프트웨어 스레딩 제어를 하는 경우가 있다고 한다.(이 경우 각 레인의 레지스터 갯수도 1 / 4 크기가 된다고 생각된다). 이 경우 입도는 64로 되고, Intel 쪽이 입도가 커진다.
그러나 G80/GT200이 완전히 하드웨어 벡터 제어를 행하는 것에 비해 Larrabee는 완전히 소프트웨어로 처리하고 있다. 또한 벡터 레지스터의 각 레인을 셔플 할 수 있는 기구도 갖추고 있다. 따라서 Larrabee의 아키텍처상 분기 입도를 작게하는 동적 제어를 행하는 것이 가능하다고 추측된다.
예를 들어, 각 16 레인의 복수의 블록 (Intel 용어는 Fiber) 중에서, 경로 A로 분기되는 레인을 모은 블록과 경로 B에 분기하는 레인을 모은 블록을 동적으로 재구성한다. 새롭게 편성된 블록은 각각 경로 A를 실행하는 것과 경로 B만을 실행하는 것이된다. 그래서 새로운 블록에서 각 분기 경로만 실행하면 분기 입도에 얽매이지 않는 효율적인 제어 흐름이 가능해진다.
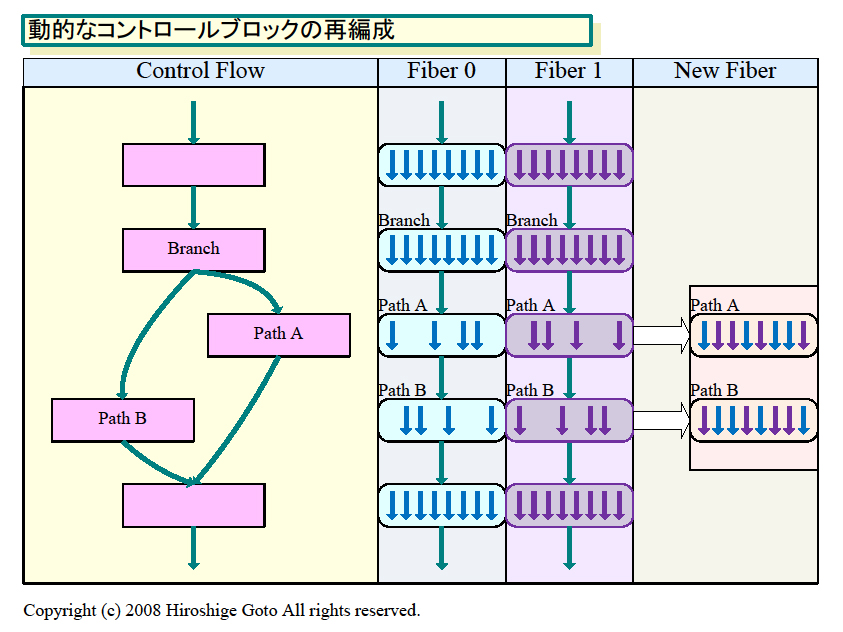
벡터 분기 조건
컨트롤 흐름의 효율화가 벡터 프로세서 포인트
이러한 벡터 프로세서의 제어 흐름의 효율성에 대한 연구는 많이 진행되고 있다. 예를 들어, 작년(2007년) 프로세서 아키텍처 컨퍼런스 "Micro40" 에서는, "Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow" 라는 제목으로 Wilson WL Fung 씨 (University of British Columbia)가 강연을 했다. 위의 그림은 그는 프레젠테이션을 기준으로 한 것이다.
GPU 벤더도 이러한 제어에 대한 연구를 하고 있다. AMD (구 ATI)의 R700 시리즈의 쉐이더 아키텍트인 Michael Mantor 씨 (Fellow Architect, AMD)는 다음과 같이 설명한다.
"그래픽에서는 분기 입도는 64쯤이 충분한 입도라고 생각해 (R6xx/R7xx를) 설계했다. 그러나 분기의 효율성의 문제는 범용 컴퓨팅에서는 중요한 경우도 있는 것으로 이해 한다. 분기의 효율을 올리는 수법은 몇 가지 연구되고 있으며, 우리도 이전부터 검토하고있 다. 분기 블록을 동적으로 재편성 하는 것이 가장 효율적 이지만 복잡한 과제도 많고, 가장 먼 지점 (미래)에 있을 것이라고 생각한다."
비 그래픽 애플리케이션에서는 분기 입도가 효율성의 중요한 문제가 되는 경우가 발생할 가능성이 있다. 각 레인의 분기 경로가 자주 나뉘는 복잡한 분기 트리의 프로그램이 나올 수 있기 때문이다. 따라서 보다 범용적인 방향으로 진행되면 벡터 프로세서의 분기 효율은 중요해져 간다. GPU도, 범용성도 강화하기 위해 컨트롤 흐름의 효율 개선을 진행시켜 나갈 필요가 있다.
이 점에서 Larrabee 아키텍처의 경우의 장점은 응용 애플리케이션에 의해 제어를 동적으로 바꿀 수 있다는 점이다. 유연하게 블럭 포메이션 및 제어를 변경할 수 있다. 예를 들어, 그래픽처럼 분기 입도가 큰 문제가 되지 않는 경우는 큰 입도로 실행. 범용적인 애플리케이션에서 입도가 문제가 되는 경우에만 분기 경로에서 블럭의 재조합 같은 특수한 제어를 할 수 있다.
이러한 유연성과 가능성을 가지는 것이 소프트웨어 제어 스케줄링을 행하는 Larrabee 형 아키텍처의 장점이라고 생각된다.
2008년 10월 31일 기사 입니다.
[분석정보] 매니코어 프로세서로 손바닥 슈퍼 컴퓨터를 실현
[분석정보] 4만 8000개의 제온파이로 중국 톈허2 세계에서 가장 빠른 슈퍼 컴퓨터
[분석정보] TOP500 슈퍼컴퓨터 순위 2013년 6월
[제품뉴스] Intel Xeon Phi 새로운 폼 팩터 채용 포함 5모델 추가
[정보분석] 인텔 60코어 매니코어 "Xeon Phi" 정식발표
[분석정보] 인텔 슈퍼컴퓨터용 가속기 Xeon Phi 5110P 발표
[분석정보] Intel, HPC 전용 보조 프로세서 Xeon Phi 2013년 1월부터 일반용으로 출시
[분석정보] IDF 2012에서 주목한 한가지, 매니 코어 "Knights Corner"
[정보분석] 엔비디아 세계 최다 트렌지스터 칩 GK 110 공개
[정보분석] IDF 2011 Justin Rattner 기조연설 매니코어 시대가 다가옴 1/2부
[정보분석] IDF 2011 Justin Rattner 기조연설 매니코어 시대가 다가옴 2/2부
[정보분석] 같은 무렵에 시작된 Nehalem과 Larrabee와 Atom
[분석정보] Intel은 Larrabee 계획과 아키텍처를 어떻게 바꾸나?
[분석정보] 다시 처음부터 시작된 라라비 무엇이 문제였나?
[분석정보] 라라비 (Larrabee)의 비장의 카드 공유 가상 메모리
[분석정보] 인텔의 스칼라 CPU + 라라비의 이기종 CPU 비전
[분석정보] Larrabee는 SIMD와 MIMD의 균형 - Intel CTO가 말한다.
[정보분석](암달의 법칙) 2010년대 100 코어 CPU 시대를 향해서 달리는 CPU 제조사
[분석정보] GDC 2009 드디어 소프트 개발자 정보도 나온 "Larrabee"
[분석정보] 인텔 GDC에서 라라비 명령 세트의 개요를 공개
[정보분석] Intel 힐스보로가 개발하는 CPU 아키텍처의 방향성
[정보분석] 팀스위니 미래의 게임 개발 기술. 소프트웨어 렌더링으로 회귀
[분석정보] 정식 발표된 라라비(Larrabee) 아키텍처
[아키텍처] 베일을 벗은 인텔 CPU & GPU 하이브리드 라라비(Larrabee)
[분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA
[정보분석] 암달의 법칙(Amdahl's law)을 둘러싼 Intel과 AMD의 싸움
[정보분석] 모든 CPU는 멀티 스레드로, 명확하게 된 CPU의 방향
[벤치리뷰] 인텔 제온 파이 5110P와 엔비디아 테슬라 K20 행렬 곱 실효 성능 비교
[벤치리뷰] N형 문제 프로그램의 인텔 제온 파이 이식 평가
[분석정보] Many-Core CPU로 향하는 Intel. CTO Gelsinger 인터뷰 1/2부
[분석정보] 5W 이하의 저전력 프로세서의 개발로 향하는 Intel
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [정보분석] Intel 힐스보로가 개발하는 CPU 아키텍처의 방향성 (0) | 2008.12.17 |
|---|---|
| [분석정보] AMD가 바라보는 x86시장 점유율 50%의 전략 (0) | 2008.12.10 |
| [분석정보] 반도체 제조사는 팹리스화로 진행 (0) | 2008.12.09 |
| [분석정보] Intel AMT를 사용해서, 원격으로 BIOS 제어나 OS 복구에 도전 (0) | 2008.12.04 |
| [분석정보] 2010년 이후의 Intel CPU가 보이는 Larrabee 신 명령 (0) | 2008.10.17 |
| [정보분석] 팀스위니 미래의 게임 개발 기술. 소프트웨어 렌더링으로 회귀 (0) | 2008.09.11 |
| [분석정보] IDF 2008에서 본 Intel의 가상화 대응 방안 (0) | 2008.09.05 |
| [분석정보] Atom의 절전 기술도 탑재한 Nehalem (0) | 2008.08.25 |