거대화 되는 Intel의 GPU 코어
Intel은 "Skylake"에서 CPU 코어를 확장했다. Skylake의 다이를, 동일한 14nm 공정의 "Broadwell"과 비교하면, CPU 코어 자체의 크기는 Skylake에서 상당히 커지고 있는 것을 충분히 알 수 있다. 그러나 Skylake 세대에서도, CPU의 다이상에 큰 면적을 갖는 것은 GPU 코어다.
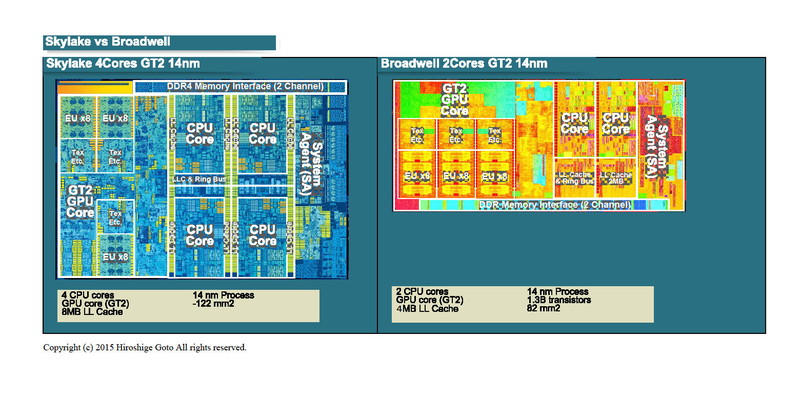
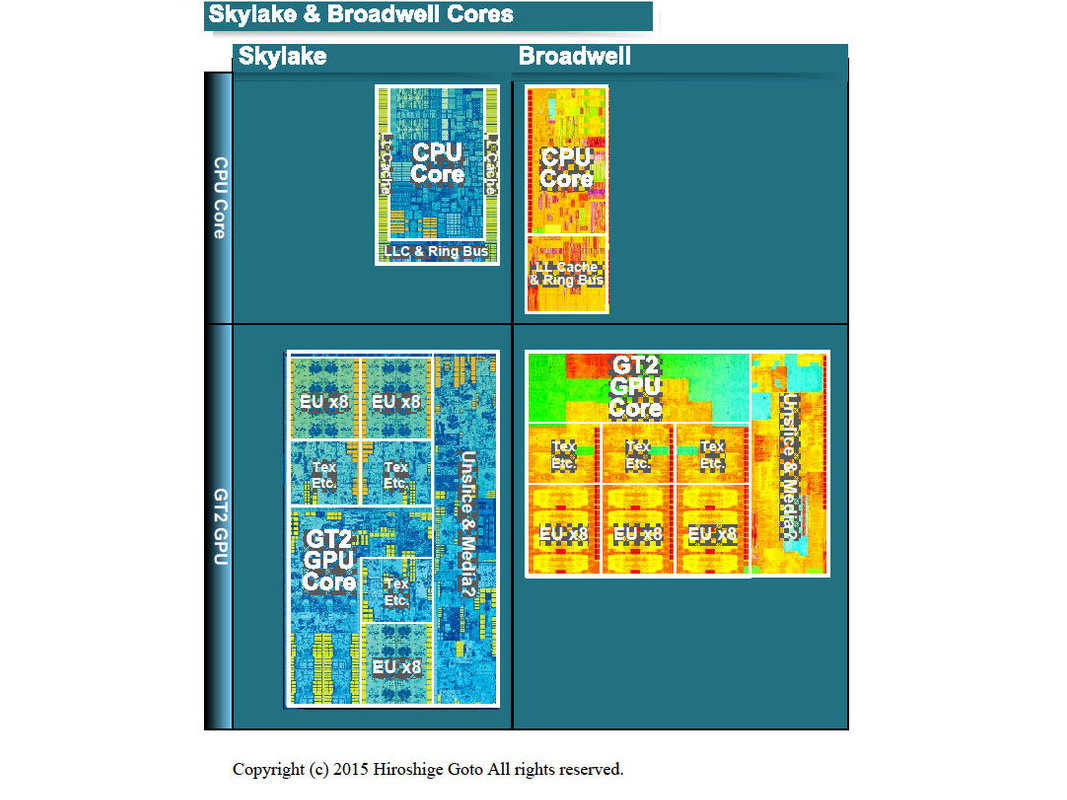
왼쪽은 4 + 2 (4 CPU 코어 + GT2 GPU 코어)의 Skylake 다이.
오른쪽은 2 + 2 (2 CPU 코어 + GT2 GPU 코어)의 Broadwell 다이
Intel도 AMD도 현재는 GPU 코어를 강화하는 길을 돌진하고 있다. Skylake 세대는 72 EU (execution unit) / 576 개의 적화산 유닛을 갖춘 거대한 GPU 코어 "GT4" 버전도 등장한다. Skylake 세대에서 마침내 Intel의 GPU 코어의 피크 연산 성능은 1TFLOPS를 넘어서게 된다. 아래는 각 세대 Intel 그래픽스의 최대 구성 코어의 연산 유닛 구성도다. Sandy Bridge 세대로 부터 5세대까지 Intel 그래픽스가 거대화 된 것을 알 수있다. (GT4의 클럭이 GT2와 같은 1.15Ghz 라면 1.324 Tflops, Xbox one GPU 1.310 Tflops)
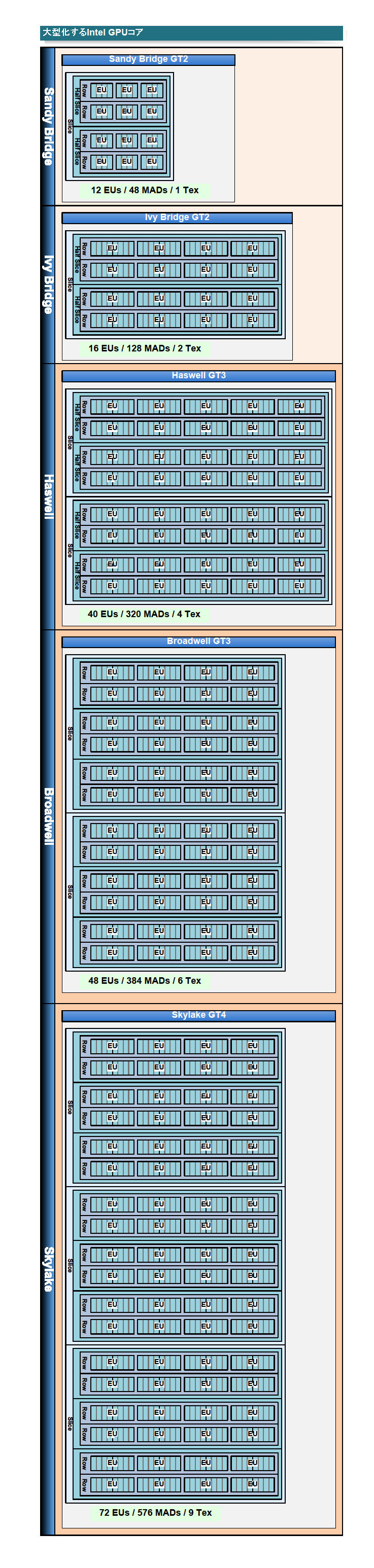
Intel 그래픽의 각 세대의 최대 구성 코어의 연산 유닛 수와 구성
Intel 그래픽의 각 세대의 최대 구성 코어의 연산 유닛 수와 구성
CPU 메이커가 GPU 코어를 크게하는 큰 이유는, 전력의 제약 속에서 성능을 올리지 않으면 안되기 때문이다. 원래 CPU 코어의 시리얼 실행 성능을 전력 효율이 좋게 끌어 올리는 것은 어렵다. 그러나 단순히 CPU 코어 수를 많게하면, 칩에서 동시에 온 할수 없는 다크 실리콘 영역이 커진다. 이런 문제를 해결하려면 CPU로 부터 오프로드 하는, 보다 성능과 전력 효율비가 좋은 코어를 탑재하는 것이다. 따라서 CPU 벤더는 GPU 코어의 강화에 노력하고 있다.
또 하나의 요인은 GPU 코어를 대형화 할 경우의 병목이 되는 메모리 대역 문제가 해결되고 있는 것이다. Intel은 메모리 대역을 소비하는 GPU 코어로 데이터를 공급하기 위해, Haswell 세대부터 eDRAM을 CPU 패키지에 짜넣어 대역폭 올렸다. Skylake는 이 솔루션을 확장한다. 여기에 더해 Intel은 JEDEC (반도체의 표준화 단체)에서의 광대역 메모리 규격 "HBM (High Bandwidth Memory)"의 책정에도 활동하고 있으며, 미래적으로 한층 광대역 메모리를 CPU에 연결하게 될 전망이다.

더 작아진 Skylake의 연산 유닛
GPU 유닛의 다이 영역을 보면, Broadwell GT2 보다도 Skylake GT2의 쪽이 13% 정도 크다. 같은 GT2의 GPU 코어도 Skylake 쪽이 비대화 되어 있다. 그런데 GPU 코어의 속살을 잘 보면, GPU의 프로세서 코어가 대형화되고 있는 것은 아니라는 것을 알 수 있다. 대형화되고 있는 것은 미디어 엔진 등의 부분의 쪽이 많아, 프로그래머블 프로세서로의 GPU 코어 부분은 대형화되어 있지 않다.
Skylake와 Broadwell의 CPU & GPU 유닛 다이 비교
Intel GPU 코어 속에서 연산 프로세서 레지스터 부분인 EU (execution unit)는 특징적인 패턴으로 다이에서 쉽게 식별 가능하다. GPU 코어에서 8개의 동일한 형태의 유닛이 나란히 있는 부분이 EU의 블록이다. EU 블록에 묶여있는 것이 텍스처 샘플러나 캐시 등의 블록인 것으로 추측된다.
Intel은 물리적인 설계 상에서도 각 유닛을 제대로 직사각형으로 설계해서 거의 동일한 물리 설계 블록을 복수 늘어 놓는 것으로, 슬라이스 구성을 늘릴 수 있도록 하고있다. Skylake GPU 코어속 EU를 포함 왼쪽 부분이 슬라이스라 추측된다. 오른쪽 긴 사각형이 언슬라이드계 유닛일 가능성이 높다.
명확하게 식별 가능한 8개의 EU 블록을 비교하면 Skylake와 Broadwell의 크기가 다른 것이 판명된다. Skylake의 EU는 Broadwell의 EU에 비해 84% 정도로 축소되어 있다. 기능적으로는 동등의 유닛이 이만큼 축소되는 것부터, Skylake는 아키텍처적으로 개량이 더해진 것이 보이고 있다. 실제 Intel은 Skylake에서 GPU 코어의 실행 모드에 근본적인 변경이 더해진 것을 설명하고 있다. 아키텍처를 실제로 체크하면 이 부분의 배경이 보인다.
Broadwell 세대와 그다지 다르지 않은 GPU 코어의 구성
Skylake GPU 코어의 3D 그래픽스 엔진 부분의 매크로 레벨에서의 마이크로 아키텍처는, 실은 Broadwell 세대와 그다지 다르지 않다. 전체 구성으로 보면, 특별히 Skylake 세대에서 진화되지 않았다고 오해 할 정도다. 그만큼 Broadwell와 Skylake의 GPU 코어 구성은 비슷하다. 그렇지만 후술하는 바와 같이, 그 내용은 크게 다르다.
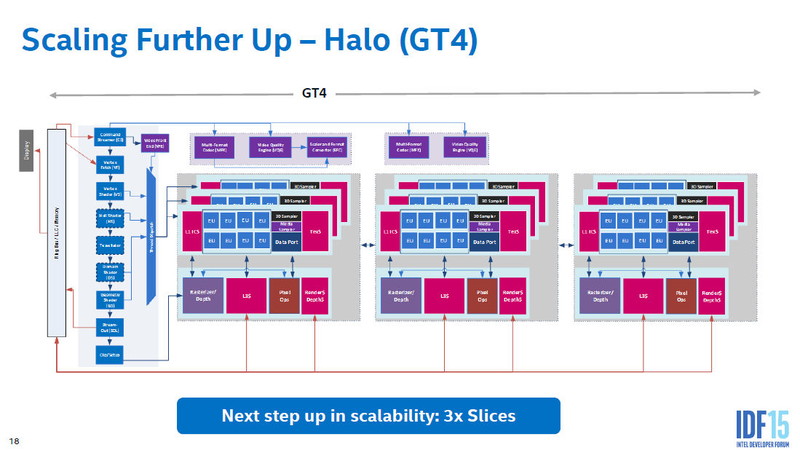
Intel은 GPU 코어를 블럭화 하고 있다. 우선 크게 나누면 GPU 코어 전체에서 공유하는 "언 슬라이스 (Un-Slice) "와 미디어 엔진 군, GPU 코어 속에서 확장 가능한 병렬화 한"슬라이스 (Slice)"로 크게 구분된다. 슬라이스 부분을 늘리는 것으로 GPU 코어의 규모를 대형화 가능한 구조로 되어있다.

GPU 코어를 블록화
Intel GPU의 연산 코어 "EU (execution unit)"는, 내부에 합계 8개의 32-bit 단정밀도 부동 소수점 적화산 유닛을 가지고 있다. Broadwell 세대까지는 32-bit 단정밀도의 4-way 유닛이 2 개 구성되어 있었다. 이 기본은 Skylake에서도 변하지 않은 것 같다. Intel GPU의 EU는 원래는 4-way 단정도 적화산 유닛과 슈퍼 펑션 유닛의 구성으로, 슈퍼 펑션 유닛이 4-way의 적화산 유닛으로도 사용할 수 있다는 경위가 있다 .
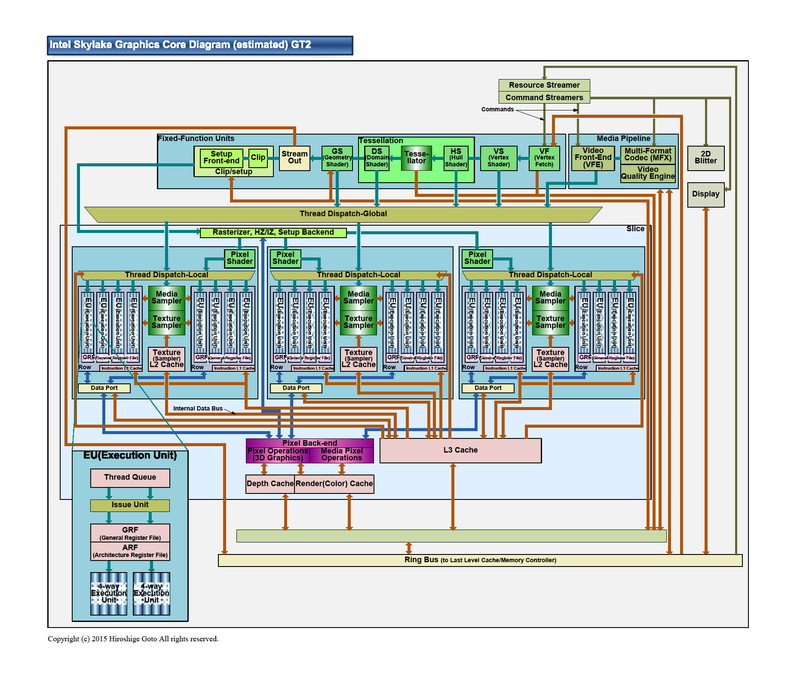
Skylake에서 기본인 GT2 구성의 GPU 코어
8개의 연산 유닛을 갖춘 EU는, 그 위에 8개씩 세트로 서브 슬라이스를 구성하고 있다. 슬라이스에는 8개의 EU 외에 텍스처 페치 & 필터링 유닛 "Texture Sampler / Media Sampler"와 L1 / L2 캐시가 부속되어 있다. 말하자면 서브 슬라이스가 미니 프로세서인 구조로 있다. EU와 텍스쳐 유닛의 비율은 8 대 1로 되어 있어, 이것은 Skylake의 GT2 / GT3 / GT4 코어에서 공통으로 되어 있다. 즉, 연산과 텍스처의 비율은 GPU의 규모에 관계없이 고정되어 있다.
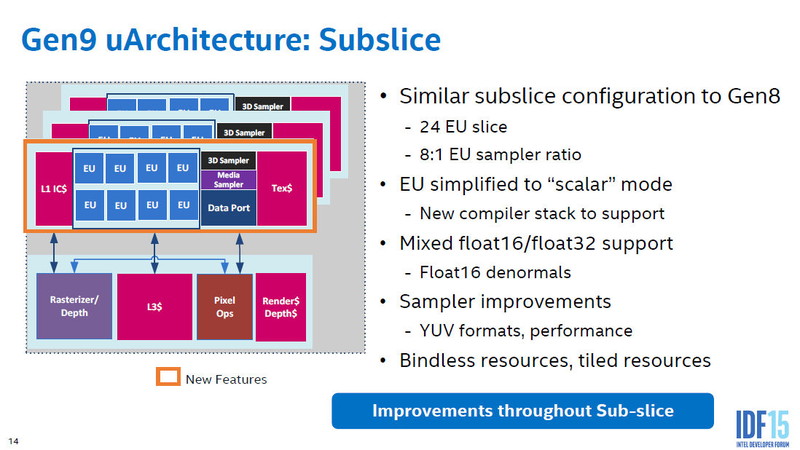
서브 슬라이스 구성
슬라이스 단위로 확장하는 모듈러 아키텍처
서브 슬라이스는 3개로 한 세트가 되어 슬라이스를 구성한다. 슬라이스는 서브 슬라이스 외에, 픽셀 백엔드나 L3 캐시 등이 부속된다. 이들은 슬라이스 커먼이라 부른다. GPU 하류의 처리에 필요한 블록을 모두 정리한 것이 슬라이스다.
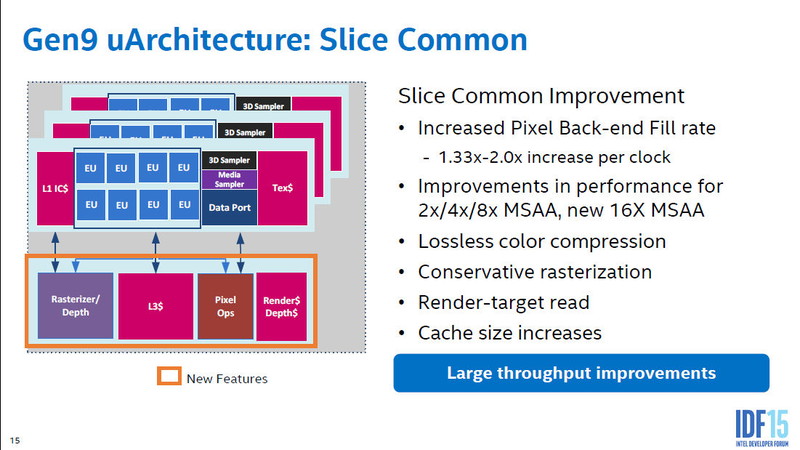
Skylake 세대 슬라이스 공통
Skylake에서 슬라이스의 픽셀 출력은 8pixel / clk 이라, 각 클럭마다 8개의 픽셀 쓰기가 가능하다. 슬라이스의 EU 수는 정해져 있기 때문에, 연산에 대한 픽셀 출력의 비율도 고정되어있다. 픽셀 백엔드의 필 레이트는 Broadwell 세대와 비교하면 1.33 배 ~ 2 배 개선 되었다고 Intel은 설명했다.
슬라이스는 GPU 처리속, 연산, 텍스처, 픽셀 백엔드를 담당한다. 이러한 처리는 슬라이스의 확장으로 늘리는 것이 가능한 아키텍처로 되어 있다. 그에 비해 GPU를 제어하는 명령 프로세서나 지오메트리 / 래스터라이즈의 고정 기능 유닛은, 언슬라이스로 슬라이스에서 독립되어 있다. 이러한 언슬라이스 유닛은 GPU 전체에서 공유한다.
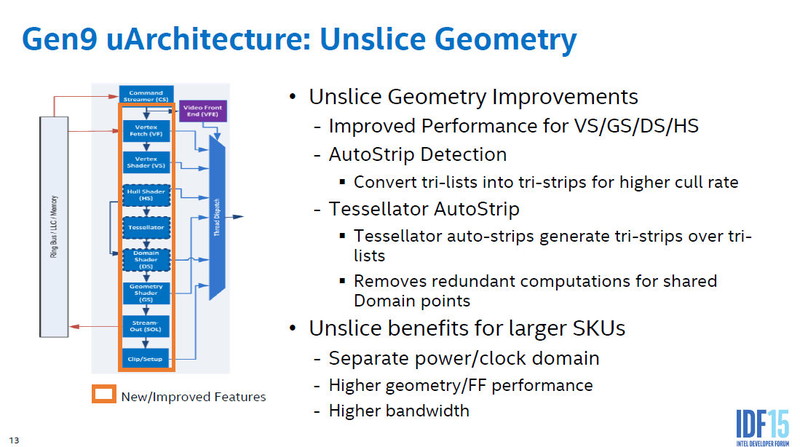
Skylake GPU 언슬라이스
NVIDIA와 AMD의 외장 GPU는, Intel의 언슬라이스에 해당하는 지오메트리 파이프 등의 고정 기능 유닛도 복수 가진다. NVIDIA나 AMD의 지오메트리 고정 기능 유닛은 Intel의 슬라이스에 해당하는 GPU 유닛에 부속되어 있다. 지오메트리 처리의 확장성을 추구했기 때문이다. Intel GPU는 현재로서는 이러한 아키텍처는 취하지 않아, 즉 지오메트리가 병목이 되지 않다고 보고 있는 것 같다.
GPU 전체에서 공유하는 유닛에는, 언슬라이스의 지오메트리 유닛 외에 미디어 처리 유닛이 있다. 비디오 코덱 "Multi-Format Codec (MFX)"이나 비디오 퀄리티 처리"Video Quality Engine (VQE) "스케일러 & 포맷 변환기"Scaler and Format Converter (SFC)"등이다. 또 디스플레이 엔진이 시스템 에이전트 측에 구비되어 있다.
여기까지를 보면, Skylake GPU 코어의 기본 부분은 Broadwell 세대와 바뀌지 않은 것으로 보인다. 그러나 실제로는 소프트웨어 실행 모델의 관점에서 Skylake는 크게 바뀌었다.
벡터 프로세서의 2종류 실행 모델
기존의 Intel 그래픽스의 큰 특징은, 2종류의 다른 실행 모델을 실행할 수 있었다. 그러나 Skylake의 GPU 코어에서는, 스칼라 형 1종류의 실행 모델로 집약된다. 실행 모델은 GPU 프로세서의 근간으로, Skylake GPU 코어에서는, 근간의 실행 아키텍처가 변경된 것이다.
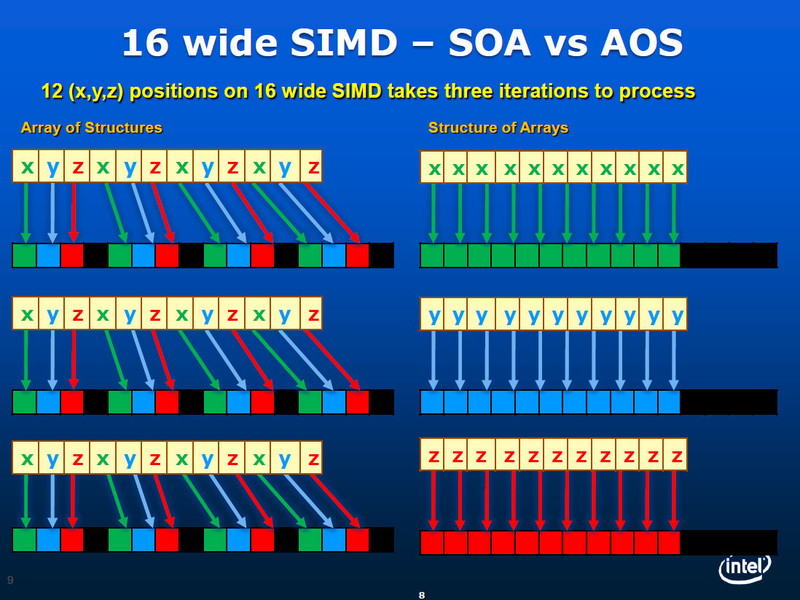
GPU는 벡터 프로세서이지만, 그 실행 모델은 크게 나눠 두 종류가 있다. 하나는 "Array of Structures (AOS)" 또는 "팩크드 (Packed)"라 부르는 방식. 또 하나는 "Structure of Arrays (SOA)"또는 "스칼라 (Scalar)"라 부르는 방식이다.
AOS / Packed 형에서는 데이터를 일정한 입도로 팩 하는 형태로 처리한다. SOA / Scalar 형에서는 마치 직렬 처리를 복수 묶은 형태로 처리한다. Intel CPU가 내장한 기존의 짧은 벡터 유닛 SSE / AVX는, 기본적으로 AOS / Packed 형의 실행 모델이다. 그에 비해 현재 NVIDIA나 AMD의 GPU는 SOA / Scalar 형의 실행 모델에 특화되어 있다.

16 개의 연산 유닛을 AOS와 SOA의 각각의 실행 모델에서 동작 시켰을 경우의 예
전통적인 GPU는 기존의 SSE / AVX와 같은, AOS / Packed 형 모델이었지만, NVIDIA가 GeForce 8800 (G80)에서 SOA / Scalar 형 모델로 바꾼 것을 시작으로, 이후로 SOA / Scalar 형으로 변해갔다. AMD는 GCN (Graphics Core Next)에서 이행 SOA / Scalar 형으로 바꾸고, Imagination Technologies는 PowerVR Series6 (Rogue)에서 SOA / Scalar 형으로 바꿨다.
AOS / Packed 형 모델과, SOA / Scalar 형 모델에는 각각 장점과 단점이 있다. 대략적으로 말하면, 데이터가 3 ~ 4개 등 정해진 수의 팩으로 되는 경우는, AOS / Packed 형이 효율이 좋다. 그러나 데이터 유형이 다양한 경우는 SOA / Scalar 형 쪽이 유연한 대응이 쉽다. 따라서 다양한 유형의 데이터를 다루는 GPU 컴퓨팅에서는 SOA / Scalar 형 쪽이 유리하다. 다만 16-bit나 8-bit 같은, 더 작은 데이터를 다루는 경우는, AOS / Packed 형 유닛을 분할하는 쪽이 효율을 높이기 쉽다.
Skylake에서 근본부터 바꾼 실행 모델
실행 모델의 전환은 GPU 아키텍처의 근간 변경이다. 통상 AOS / Packed 형 모델의 프로세서는 SOA / Scalar 형 모델을 지원하지 않는다. 그 반대로, SOA / Scalar 형 모델의 프로세서는 기본적으로 AOS / Packed 형 모델을 지원하지 않는다. 따라서 어떤 실행 모델을 취하나는, 벡터 프로세서 아키텍처의 큰 차이가 된다.
그런데 Intel은 달랐다. Intel GPU는 지금까지 AOS / Packed 모델과 SOA / Scalar 형 모델 양방을 지원했다. 이것은 GPU로서는 이례적인 아키텍처로, Intel 그래픽의 큰 특징 이었다. 참고로 마찬가지로 AOS / Packed 형과 SOA / Scalar 형의 양 모델을 지원하는 프로세서로, Intel의 Larrabee 프로젝트가 있었다. Intel은 AOS / Packed 와 SOA / Scalar의 양방을 지원하는 것을 중시했던 것으로 보인다.
Larrabee의 AOS와 SOA의 설명 슬라이드
그러나 Skylake에서는 이 아키텍처가 근본부터 바뀌었다. Skylake 그래픽스의 실행 모델에 관해서 IDF에서 다음과 같이 설명했다.
"기존의 EU는 짧은 벡터 모드 (AOS / Packed 형)와 순수 스칼라 (SOA / Scalar 형) 모드 양방을 지원했다. 2계통의 모드에서 SIMD4x2, SIMD1x8, SIMD1x16, SIMD1x32 등 다양한 포맷이 있었다. 그래픽스 코어의 처리 중, 지오메트리 프로세싱은 짧은 벡터 모드를 사용하고 있었다. 픽셀 프로세싱과 GPGPU는 순수 스칼라 모드를 사용했다. 몇 미디어 프로세싱도 스칼라 모드였다. 그러나 Skylake 부터는, 전체에 대해서 항상 스칼라 모드를 사용하게 되었다. 따라서 컴파일러 스택도 Skylake에서 전부 바꿔 만들었다."
SIMD4x2 라는 것은, 4-way의 AOS / Packed 형의 실행 모델에서, 4개의 요소를 팩화하고 동시에 처리하는 것으로, 4-way 팩 2개를 한 덩어리로 실행한다. SSE에 닮은 실행 모델로 바꿔 말하는 것도 가능하다. SIMD1x8이나 SIMD1x16는 SOA / Scalar 형의 실행 모델로 1개의 요소를 Scalar 형으로 실행하고, 그것을 8개 또는 16개씩 묶는 것이다. 현재의 PC 용 GPU의 주류 모드이다.
Intel 그래픽스는 이처럼 AOS / Packed 형과 SOA / Scalar 형의 2가지의 실행 모델로, 각각 복수의 실행 포맷을 가지고 각각 필요한 처리 사이클도 다르고, 벡터 폭도 다르다는 복잡한 구조였다. Skylake에서는 이 실행 모델이 근본적으로 바뀌고, NVIDIA나 AMD의 GPU와 비슷한 SOA / Scalar 형 뿐이 되었다.
실행 모델을 바꾸는 중요한 요소는 무엇인가? Intel은 간소화와 효율화를 달성하는 것이라 설명한다. 기존에는 Intel 그래픽스의 하드웨어도 두 실행 모델에 대응하는 내부 아키텍처를 취했다. 이것은 GPU 하드를 복잡하게 할뿐만 아니라 드라이버도 복잡화 시켰다고 보인다. Skylake에서의, SOA / Scalar 형만로의 전환은 Intel GPU 코어의 제어나 소프트웨어 층의 단순화를 가져온 것이다. 그렇게 생각하면 Skylake에서 EU 블록이 축소 된 이유도 보인다.
SOA / Scalar 형의 실행 모델은, 통상 GPU 컴퓨팅과 같은 이용에 적합하다고 말한다. AOS / Packed 형은 기존의 GPU나 미디어 프로세서를 끌던 모델이다. 이번 Skylake GPU 코어의 개혁은 GPU 코어를 보다 범용적인 GPU 컴퓨팅에 적합한 설계에 바꿨다고 말할 수 있다.
2015년 10월 22일 기사
![]() The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
[분석정보] GPU 컴퓨팅 기능을 강화한 Skylake의 GPU
[분석정보] Skylake 아키텍처의 수수께끼 2 - 5명령 디코더와 6명령 uOP캐시
[벤치리뷰] 탐스 게임용 VGA 등급 2015년 10월
[분석정보] Intel의 새 메모리 3D XPoint가 DIMM으로 투입되는 배경
[분석정보] 인텔의 차세대 마이크로 아키텍처 스카이레이크
[분석정보] Skylake의 SpeedShift로 P스테이트의 소비 전력 삭감을 실현
[분석정보] 인텔 데스크탑 eDRAM 버전을 포함한 브로드웰 패밀리 설명
[분석정보] Haswell 절전 기능의 열쇠 "FIVR" 과 그 이후
[분석정보] IDF 13 IDF에서 Intel이 14nm 공정 세대 Broadwell 을 공개
[분석정보] 인텔 GDC에서 라라비 명령 세트의 개요를 공개
[분석정보] Larrabee는 SIMD와 MIMD의 균형 - Intel CTO가 말한다
[분석정보] 크게 다른 Radeon HD 2000과 GeForce 8000의 아키텍처
[분석정보] 광대역 메모리의 채용을 가능하게 하는 Intel의 새 패키징 기술 EMIB
[분석정보] 테라 바이트 대역의 차세대 메모리 HBM이 2015년에 등장
[분석정보] DDR4는 어떻게되나? 인텔의 메모리 전략을 예측
[분석정보] JEDEC이 "DDR4"와 TSV를 사용 "3DS" 메모리 기술의 개요를 밝힌다.
[분석정보] Intel의 메모리 로드맵에 DDR4가 없는 이유
[분석정보] 2015년 컴퓨터 플랫폼 IDF Spring 2005
[분석정보] Intel의 eDRAM 칩은 128 뱅크 구성에 읽기, 쓰기, 리프레시를 병렬
[분석정보] 하스웰의 고성능 그래픽의 열쇠 Intel 제조 eDRAM의 상세
[분석정보] 정체를 보인 Haswell의 eDRAM 솔루션
[아키텍처] Intel의 차기 CPU 하스웰(Haswell) eDRAM의 수수께끼
[분석정보] 메모리가 큰 벽이 되는 AMD의 퓨전 (FUSION) 프로세서
[분석정보] IBM이 기술의 집대성 괴물 CPU Power8 발표
[분석정보] NVIDIA의 ARM 코어 Denver 등이 Hot Chips에서 발표
[분석정보] Intel의 CPU "Haswell"용 DRAM 기술
[분석정보] AMD의 신 GPU 아키텍처 "Graphics Core Next"의 비밀
[정보분석] CPU와 GPU의 메모리 공간을 통일하는 AMD의 hUMA 아키텍처
[분석정보] AMD의 차세대 APU Kaveri (카베리)는 아키텍처의 전환점
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] 인텔 HPC 시스템 Scalable System Framework 소개 (0) | 2015.12.11 |
|---|---|
| [분석정보] 오픈이며 안전하고 확장 가능한 인텔의 IoT 플랫폼 (0) | 2015.11.18 |
| [분석정보] TOP500 슈퍼컴퓨터 순위 2015년 11월 (0) | 2015.11.17 |
| [분석정보] GPU 컴퓨팅 기능을 강화한 Skylake의 GPU (0) | 2015.11.05 |
| [분석정보] Skylake 아키텍처의 수수께끼 2 - 5명령 디코더와 6명령 uOP캐시 (0) | 2015.10.07 |
| [분석정보] Intel의 개발 책임자에게 듣는, Skylake 개발 비화 (0) | 2015.09.07 |
| [분석정보] Intel의 새 메모리 3D XPoint가 DIMM으로 투입되는 배경 (0) | 2015.08.25 |
| [분석정보] 클라이언트에서 서버까지 토털 솔루션을 제공하는 Intel의 IoT (0) | 2015.08.24 |