GT2 구성이 기본이 되는 Intel 그래픽
Intel은 Skylak 세대에서 GPU 코어의 기본적인 부분을 확장했다. 그렇긴 하지만, Skylake GPU 코어 자체의 구성은 Broadwell GPU 코어와 아주 비슷하다. GPU 코어 전체에서 공유하는 "언 슬라이스 (Un-Slice) "와 미디어 엔진군과 GPU 코어의 안에서 확장으로 병렬화 하는 "슬라이스 (Slice) "가 있다. GPU 코어의 연산 코어 "EU (execution unit)"는 내부에 합계 8개의 32-bit 단정밀도 부동 소수점 적화산 유닛을 갖추고 있다. EU는 32-bit 단정밀도 4-way의 벡터 유닛이 2개 구성되어 있는 것으로 보인다 (1EU = 8 x 2 (FMA) = 8Flops. EU 수 x 16Flops x GPU 클럭 = GPU Peak Flops) . EU는 여기에 8개씩 세트로 "서브 슬라이스 (Sub-Slice)"를 구성한다. 서브 슬라이스에는 8개의 EU 외에 텍스처 페치 & 필터링 유닛 "Texture Sampler / Media Sampler"과 L1 / L2 캐시가 부속되어 있다. 서브 슬라이스는 3개로 한세트가 되어 "슬라이스 (Slice)"를 구성한다. 슬라이스에는 서브 슬라이스 외에, 픽셀 백엔드나 L3 캐시 등이 부속된다.
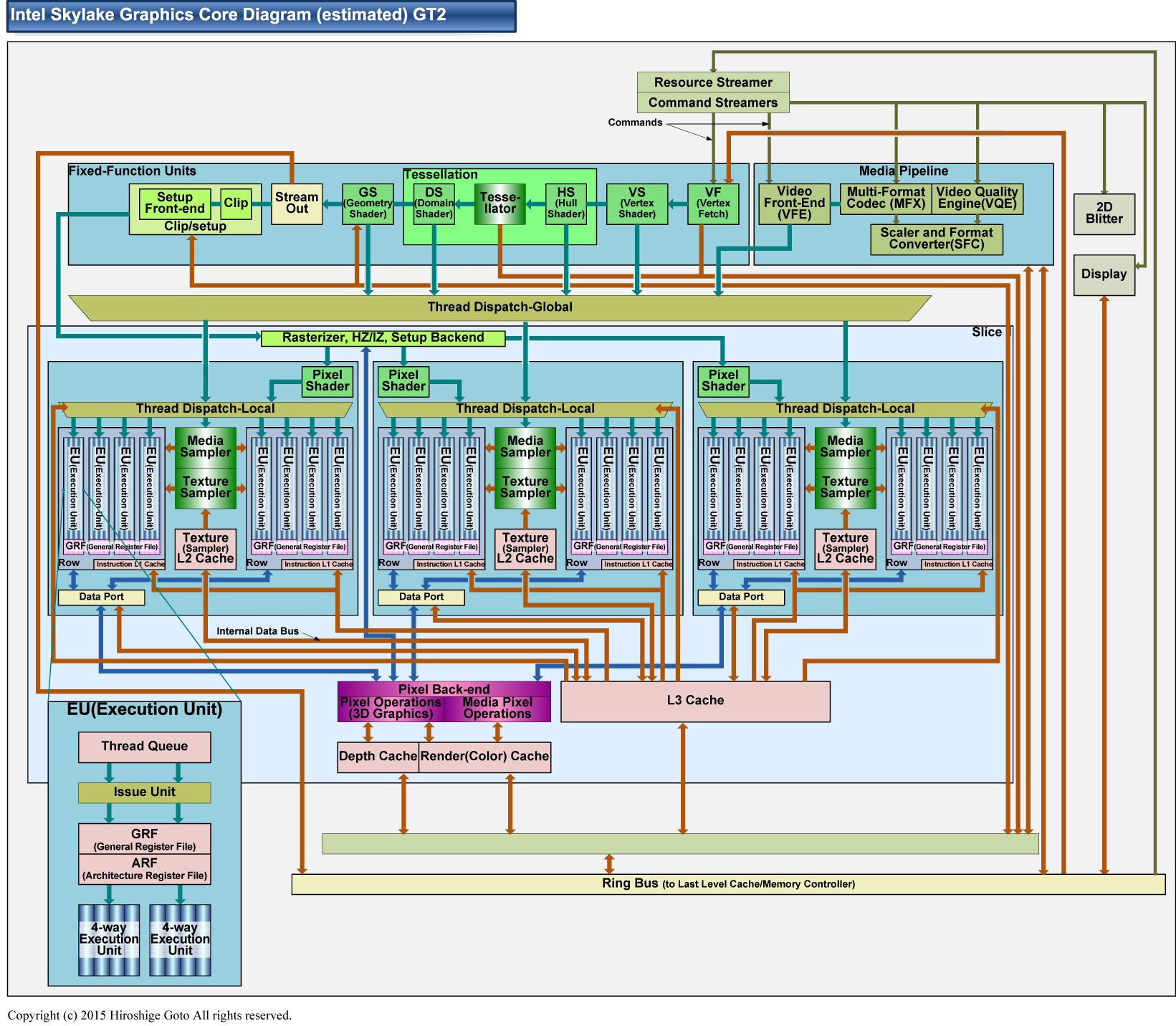
이전 기사의 Skylake GPU GT2 구성도에는 부족함이 있어, 이것이 완전판.
이상이 Skylake GPU 코어인 GT2의 구성이다. Intel 그래픽에서는 현재는 GT2 구성이 아키텍처적인 기본으로 되어있다. GT2 코어는 슬라이스가 1개의 구성이다. Skylake에서는 슬라이스가 2개가 되면 GT3, 슬라이스가 3개가 되면 GT4로, 확장성면에서는 심플하다. 반대로, GT1과 GT1.5는 스케일 다운 버전이다. 확장성에서의 Broadwell과 큰 차이는 72EU 구성의 GT4가 더해진 것이다. GT4에서는 적화산 유닛 수는 576개로 되고, 성능은 1TFLOPS를 넘는다. (GT4의 클럭이 GT2와 같은 1.15Ghz 라면 1.324 Tflops, Xbox one GPU 1.310 Tflops)
GT1과 GT1.5는 슬라이스 유닛내의 구성이 GT2 이상과 다르기 때문에, 연산과 텍스처의 비율이나 연산과 픽셀 필의 비율이 다르다. 실제로는, GT1과 GT1.5 모두 GT2 기능 해제판인 것으로 보인다. 아래의 그림속에서 GT1과 GT1.5의 구성은 편의적인 것으로, 실제로는 슬라이스에 속에서 어떤 구성으로 EU 등이 유효한 것인지 알수 없다. 참고로 일부 유닛을 무효화 하는 것으로, 결함이 있는 유닛을 배제시키기 때문에 GPU 코어의 수율은 오른다.

Intel GPU 코어 구성의 변화
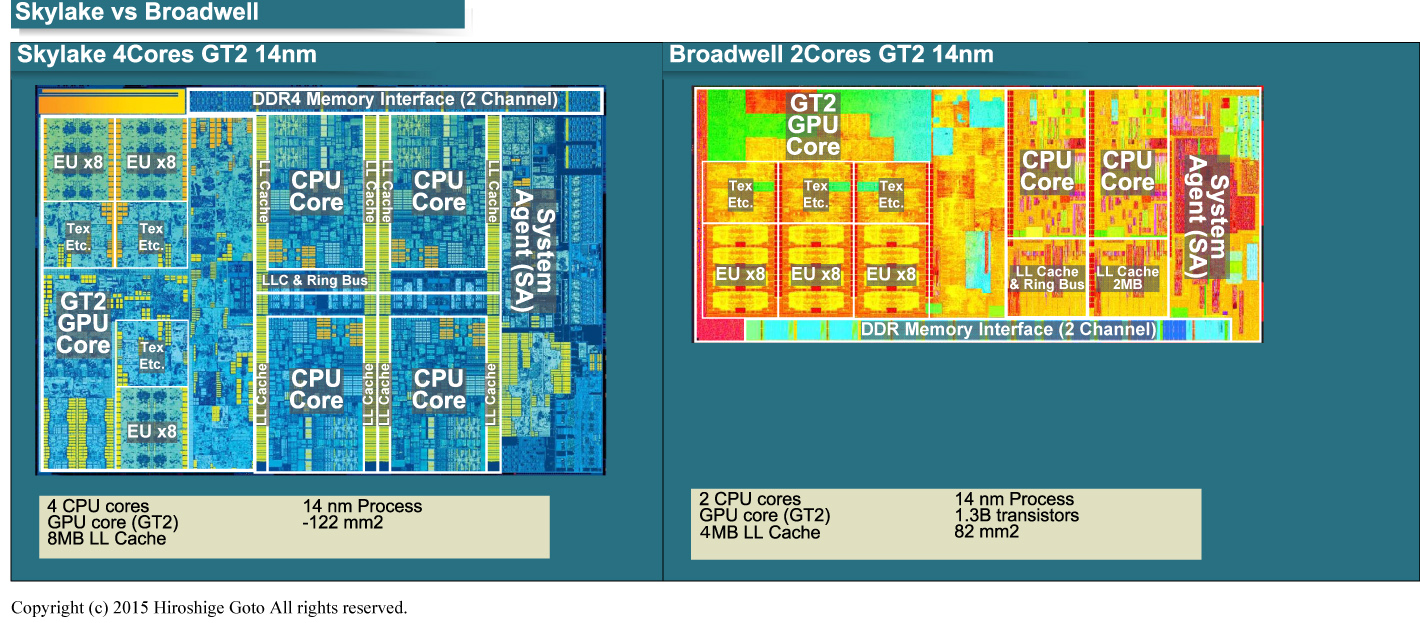
Skylake와 Broadwell의 다이 레이아웃
GPU 코어와 CPU 코어가 가상 주소 공간을 공유
Skylake GPU 코어에서는 실행 모델이 기존의 AOS / Packed 형 모델과 SOA / Scalar 형 모델 양쪽 지원에서, SOA / Scalar 형 (= SIMT : Single Instruction, Multiple Thread) 모델 만으로 바뀌었다. Intel 그래픽 아키텍처의 큰 특징이었던, 복잡한 실행 모델과 다양한 모드는 없어졌다. 현재 NVIDIA나 AMD의 GPU 코어와 비슷한, 더 간단한 모델의 GPU 코어가 되었다. NVIDIA나 AMD가 SOA / Scalar 형 아키텍처를 취한것은 스칼라형의 실행이 중요한 응용 프로그램이 존재하는 GPU 컴퓨팅에 초점을 맞추고 있기 때문이다. Intel도 어느정도 비슷한 이유로 실행 모델의 변경을 진행한 것으로 보인다.
Skylake GPU 코어에서는 실행 모델의 변경에 맞춰, CPU와 GPU의 통합이나 멀티 태스킹에 중요한 기능을 강화한다. 전체적으로, GPU 컴퓨팅을 위한 기능 강화가 눈에 띈다. 이러한 경향은 Broadwell 때부터 시작되어 Skylake에서는 그것이 가속된다.
Intel은 Broadwell 세대 GPU 코어부터 "공유 가상 주소 공간 (Shared Virtual Address Space)"을 구현했다. Haswell까지의 GPU 코어는, CPU 코어와는 분리 된 메모리 주소 공간을 가지고 있었다. 그러나 Broadwell부터는 GPU 코어와 CPU 코어 군이 같은 공유 메모리 주소 공간을 공유 가능해졌다. GPU와 CPU 쌍방의 MMU (Memory Management Unit)를 동기화하고 있다고 추측된다. 그것에 의해 CPU 코어와 GPU 코어 사이에서 주소 포인터로 데이터의 교환 공유가 가능하다. 데이터 전송이나 동기화가 불필요하기 때문에 GPU 프로그래밍이 용이해 진다.
Intel은 그 이전에도 소프트웨어 제어의 공유 가상 메모리 (SVM : Shared Virtual Memory)를 도입했다. 그러나 Broadwell부터 구현한 것은 하드웨어 제어 공유 가상 메모리이다. 소프트웨어 제어의 입도 큰 (페이지 기반) SVM과 달리, Broadwell에서는 캐시 라인 단위의 입도 작은 SVM을 지원한다. 이를 위해 GPU 캐시에 대한 하드웨어 기반의 캐쉬 coherency도 Broadwell 세대부터 지원했다.
GPU 코어의 캐쉬 coherency를 개선
기존의 CPU에서는 보통 내장 GPU 코어의 캐시 메모리에 대해서는, CPU 코어 측에서 스눕이 가능하지 않는 것이 일반적이다. 캐쉬 coherency (일관성)는 단방향의 I / O 코히런시로, 보통은 GPU 코어 측에서 CPU 코어 측의 캐시 스눕만(감시로 데이터 삭제등 일관성 구축) 구현되어있다. 따라서 캐시 일관성을 취하기 위해, GPU 측의 캐시를 플러시하고, GPU 측 캐싱을 스킵하는 등의 특수한 운영이 필요했다.
그 반면, Intel은 Broadwell 세대부터 CPU와 GPU 간의 하드웨어 기반의 쌍방향 캐쉬 coherency를 도입했다. CPU 측과 GPU 측의 양방에서 서로의 캐시를 스눕 가능하다. 따라서 Intel 아키텍처에서 GPU 코어는, 마치 CPU 코어의 하나처럼, 캐쉬 coherency를 유지한채로 메모리의 공유가 가능해졌다.
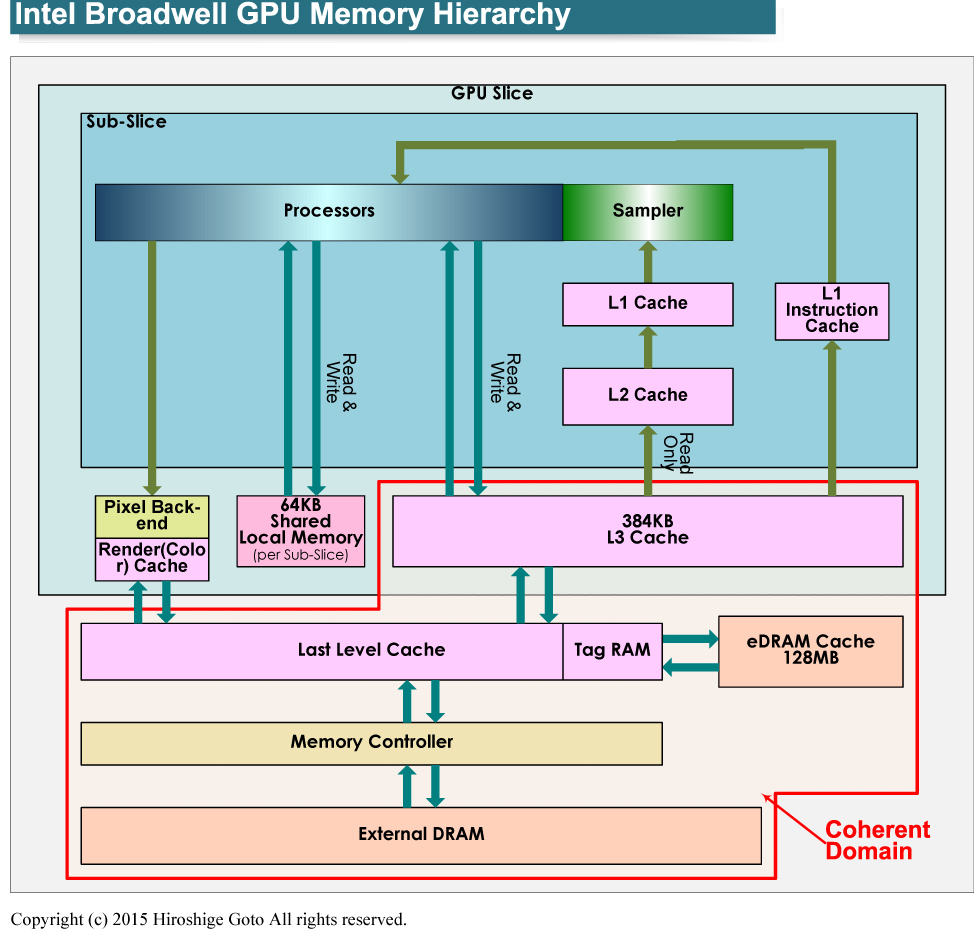
Broadwell GPU 코어의 메모리 계층
구체적으로는 Broadwell GPU 코어에서, Graphics Technology Interface (GTI)와 각 슬라이스에 포함된 L3 캐시가 "전역 일관성 메모리 (Globally Coherent Memory)"도메인으로 확장되었다. 글로벌리 코히런시 메모리로에 대한 CPU 코어에서 읽기와 쓰기는 GPU L3 캐시에 메모리 스누핑이 처리된다.
GPU 코어에서의 읽기와 쓰기도 마찬가지로 캐시 스누핑에서 일관성이 유지된다. 스누핑 프로토콜은 Intel의 I / O 가상화 기술 "Intel VT-d"를 준수한다. GPU 측의 메모리 계층에서 각 슬라이스 속의 샘플러에 부속된 L1 / L2 데이터 캐시는 일관성은 유지되지 않는다. 그러나 샘플러 속의 캐시는 읽기 전용이기에 문제는 생기지 않는다.
Skylake GPU 코어의 메모리 계층과 일관성의 구조는, Broadwell 세대와 상당히 비슷하다고 추측된다. 다만 Skylake GPU 코어는 캐쉬 coherency가 강화되었다. Intel은 지금까지의 캐쉬 coherency는 성능상의 비용이 있었지만, Skylake에서는 코히런시의 성능이 향상되어, 비용이 절감됐다고 설명했다. 또 GPU 코어 측의 슬라이스에 내장된 L3 캐시도 증량 됐다고 한다.
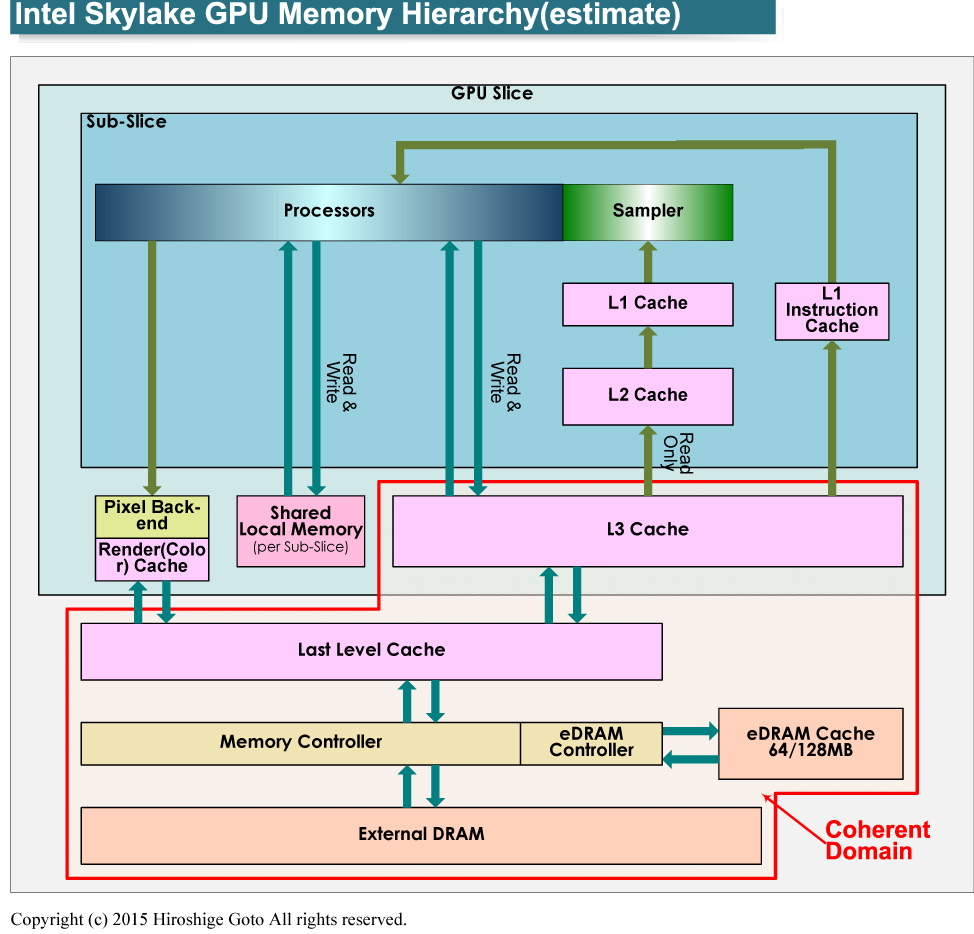
Skylake의 GPU 코어의 메모리 계층 추측
(Last Level Cache = CPU의 L3 캐시, L3 Cache = GPU L3 캐시
CPU쪽은 인텔에서 LLC라고 하기 때문에)
메모리 계층에는 이밖에 eDRAM 캐시로서의 제어 방식이 크게 바뀌었는데, 이것은 미래의 Intel CPU의 메모리 계층 전체의 개혁과 연결된 것으로 보인다.
GPU를 CPU처럼 유연하게 반응하는 Preemption
캐쉬 코히런시 이상으로 큰 변화는 선점이다. GPU 선점의 목적은 한마디로 말하면 CPU의 멀티 태스킹 / 가상화 지원에 가까운 것이다. 선점형 멀티 태스크 스케줄링에서는 OS가 프로그램을 교대로 전환 실행하는 것으로, 응답성이 좋아 원활한 처리를 실현 가능하다. 따라서 리치 CPU는 실행중인 프로그램을 일시 중지하고, 다른 프로그램을 실행하는 선점을 지원하고있다. 그것에 비해 기존의 GPU는, 1 화면의 렌더링이나 1커널의 실행을 끝낼때 까지는 다른 프로그램을 실행하는 것이 가능하지 않았다.
현재의 GPU는 이 선점 기능을 충실히 하는 것이 중요한 테마가 되었다. GPU에서 비 그래픽 어플리케이션에서도 유연하고 원활한 처리를 실현하기 위해서도, 컴퓨트에서의 가상화 지원을 위해서다. AMD는 현재 스레드의 실행 중에도 태스크를 전환하는 입도 작은 선점을 하드웨어로 지원하고있다. NVIDIA도 같은 선점을 내년 (2016년)의 Pascal 세대에서 구현할 예정이다.
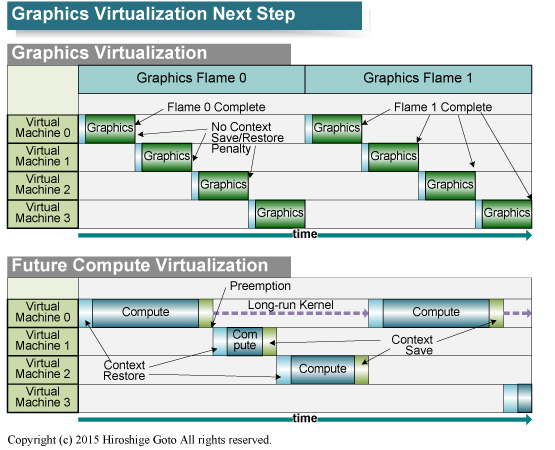
그래픽 가상화
Intel은 Broadwell 세대에서 태스크 스위치를 지원했지만, 그래픽은 오브젝트 (트라이앵글 등) 단위로, 컴퓨트는 스레드 그룹 단위로 태스크를 전환하는 것이 가능했다고 한다. 즉 선점의 입도가 컸다. 그러나 Skylake 에서는 컴퓨팅 워크로드에 대해서, 스레드의 도중에도 태스크 전환이 가능한 기능을 지원한다. Skylake 선점에서 입도를 작게한 것으로, 태스크의 전환까지의 레이턴시가 짧아져, 응답성이 오른다고 한다.

작업 전환 레이턴시
이것은 스케줄러가 태스크 전환을 요청에서 전환까지의 레이턴시를 보인다. 쓰레드 그룹 단위의 스위칭의 경우는, 스레드 그룹 전체의 처리를 끝낼 필요가 있기 때문에, 전환까지 끼어들 태스크가 기다리게 된다. 그에 비해 미드 스레드 선점은 스레드 도중에 전환되기 때문에, 레이턴시는 최단이 된다.
그렇지만, 미드 스레드 선점을 실현하기 위해서는, 실행중인 스레드의 레지스터 내용을 일단 메모리에 대피시키고, 다른 스레드를 실행, 그 후 원래의 스레드를 복귀시킬 때에는 메모리에서 레지스터 내용을 다시 읽지 않으면 안된다. GPU의 경우는 레지스터 파일이 CPU보다 크기 때문에, 컨텍스트의 세이브 / 리스토어가 CPU 보다 무겁다. 미드 스레드의 레이턴시는 콘텍스트의 세이브 / 리스토어의 레이턴시를 반영하고 있는 것으로 추측된다.
Intel은 미세입도로 응답성이 높은 선점은, 특히 2가지 큰 장점이 있다고 설명한다. 하나는 미션 크리티컬 워크로드의 응답성 개선, 다른 하나는 낮은 TDP (Thermal Design Power : 열 설계 전력) 제품의 사용자 체험을 개선. Skylake의 U 시리즈나 Y 시리즈와 같은 TDP 범위가 낮은 제품은 GPU 동작 속도가 느리지만, 미드 스레드의 태스크 전환이 되는 것으로, 혜택이 크다고 말한다.
구체적으로는 U나 Y 시리즈에서도 수백 μs (마이크로 초)의 낮은 레이턴시로 선점을 행할 수있게 되었다. 따라서 터치스크린 프로세싱의 GPU 오프로드를, 높은 응답성으로 가능하다고 한다. 태블릿 등의 폼팩터 사용자 체험을 쾌적하게 하는 것이 가능하다고 Intel은 설명한다.
이러한, Skylake GPU의 눈에 띄지 않지만 중요한 확장을 보면, 실행 모델의 일원화와 함께, Intel이 GPU 코어를 GPU 컴퓨팅을 향해서 확장하고 있는 것을 잘 알게된다. 그래픽 처리 기능도 확장하고 있지만, 컴퓨팅의 확장은 보다 근원적인 큰 확장이 많다. 늘어난 GPU 코어의 자원을 그래픽 이외의 기능으로 사용해 가려고 하는 Intel의 방침이 엿보인다.
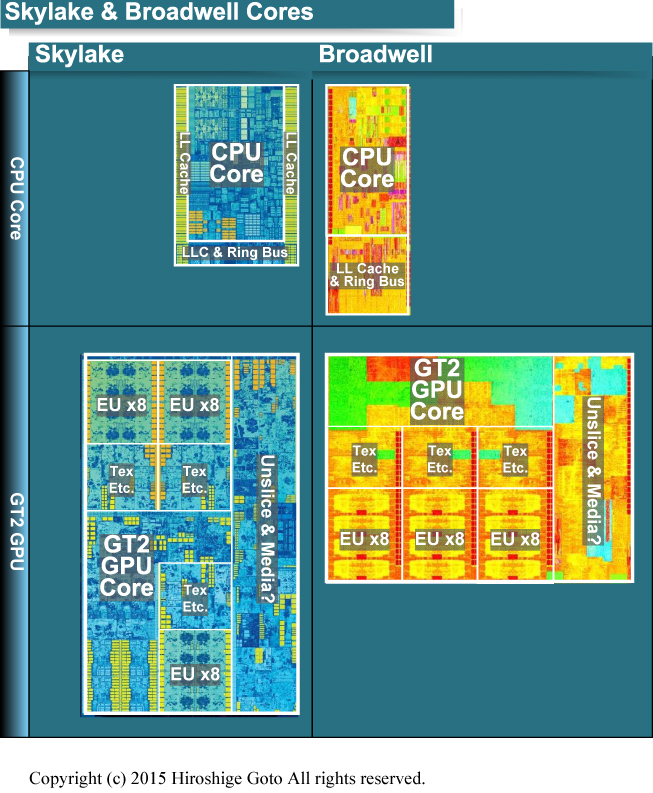
Broadwell과 Skylake의 CPU 코어와 GPU 코어의 비교
2015/11/05
![]() The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
[분석정보] 실행 모델을 변경한 Skylake의 GPU 코어, 보다 일반적인 GPU 컴퓨팅으로 향한 설계
[분석정보] Skylake 아키텍처의 수수께끼 2 - 5명령 디코더와 6명령 uOP캐시
[분석정보] 인텔의 차세대 마이크로 아키텍처 스카이레이크
[분석정보] Intel의 새 메모리 3D XPoint가 DIMM으로 투입되는 배경
[분석정보] Skylake의 SpeedShift로 P스테이트의 소비 전력 삭감을 실현
[벤치리뷰] 탐스 게임용 VGA 등급 2015년 10월
[분석정보] AMD의 신 GPU 아키텍처 "Graphics Core Next"의 비밀
[정보분석] CPU와 GPU의 메모리 공간을 통일하는 AMD의 hUMA 아키텍처
[분석정보] AMD의 차세대 APU Kaveri (카베리)는 아키텍처의 전환점
[분석정보] AMD Kaveri의 메모리 아키텍처와 향후의 APU 진화
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] Curie 출하 등 새로운 사업의 진전을 어필한 Intel 기조 강연 보고서 (0) | 2016.01.08 |
|---|---|
| [분석정보] 인텔 HPC 시스템 Scalable System Framework 소개 (0) | 2015.12.11 |
| [분석정보] 오픈이며 안전하고 확장 가능한 인텔의 IoT 플랫폼 (0) | 2015.11.18 |
| [분석정보] TOP500 슈퍼컴퓨터 순위 2015년 11월 (0) | 2015.11.17 |
| [분석정보] 실행 모델을 변경한 Skylake의 GPU 코어, 보다 일반적인 GPU 컴퓨팅으로 향한 설계 (0) | 2015.10.22 |
| [분석정보] Skylake 아키텍처의 수수께끼 2 - 5명령 디코더와 6명령 uOP캐시 (0) | 2015.10.07 |
| [분석정보] Intel의 개발 책임자에게 듣는, Skylake 개발 비화 (0) | 2015.09.07 |
| [분석정보] Intel의 새 메모리 3D XPoint가 DIMM으로 투입되는 배경 (0) | 2015.08.25 |