스칼라 명령에 적합한 아키텍처를 요구
AMD (구 ATI)의 "Radeon HD 2000 (R6xx)" 아키텍처와 NVIDIA의 "GeForce 8000 (G8x)" 아키텍처에는 근본적인 차이가 있다. 그것은 쉐이더 프로세서의 구성 및 제어이다. 같은 문제에 대해 두 회사가 내놓은 답변은 정반대의 접근이었다. 양사의 접근의 차이를 쉽게 도식화 한 것이 아래의 차트이다.

쉐이더 프로그램의 변화와 GPU의 대응의 차이
기존 GPU를 실행하는 코드는 1 명령으로 복수의 데이터에 동시에 동일한 작업을 하는 SIMD (Single Instruction, Multiple Data) 형 처리가 중심이었다. 명령의 다수가 SIMD 명령이므로 실행 유닛도 1 명령으로 여러 데이터를 처리하는 SIMD 형 유닛이 최적이었다.
하지만 GPU가 실행하는 코드에 스칼라 명령이 많아지면, SIMD 유닛은 낭비가 생겨 버린다. 예를 들어, 전형적인 4-way의 SIMD 유닛 (vec4)의 경우 4개의 연산 유닛이 1 세트가 된다. 따라서 스칼라 명령을 실행하면 사용되는 연산 유닛은 1개 뿐, 다른 3개의 연산 유닛은 아이들이 되어 버린다.
그래서 이전 세대의 GPU는 SIMD 유닛을 1-way 스칼라 유닛과 3-way SIMD 유닛으로 분리하는 등, MIMD (Multiple Instruction, Multiple Data) 형의 사용법도 할 수 있었다. 이 경우 두 명령을 동시에 수행 할 수 있으므로 보다 효율적으로 실행 유닛을 가동시킬 수 있다. 하지만 스칼라 명령이 연속 되는 코드가 되면 그래도 쉐이더 프로세서는 비효율적으로 되어 버린다.
이전에는 GPU가 실행하는 프로그램은 SIMD 중심 이었기 때문에, 이러한 아키텍쳐에서도 좋았다. 하지만 GPU의 실행 프로그램이 변화하고 있기 때문에 향후 GPU의 성능이 저하 해 버린다. 즉, 프로그램이 발전함에 따라 동일한 GPU에서도 실효 성능이 떨어질 가능성이 있다.
그것으로 GPU 벤더는 GPU의 쉐이더 프로세서를 SIMD 형의 처리에 최적화 된 SIMD 유닛없이 스칼라 형 명령에 적합한 스칼라 연산 유닛이 되도록 시도하기 시작했다. 그것이, DirectX 10 세대의 GPU에 공통된 특징이다. 그리고 AMD도 NVIDIA도 스칼라 화 한 연산 유닛을 어떻게 제어하는지 궁리를 했다.
명령 레벨의 병렬성을 가져온 R600
AMD의 R600은 쉐이더 프로세서인 "5-way 수퍼 스칼라 쉐이더 프로세서"안에 스칼라 연산 유닛인 "스트림 프로세싱 유닛"을 5개 탑재했다.
"5라는 유닛 수는 이전 세대의 버텍스 쉐이더 프로세서의 구성과 일치한다. 이전 세대에서는 Vec4 (4-way SIMD 유닛) 플러스 1 (스칼라 유닛)이었다. R600에도 같은 편성을를 유지하게 했다.하지만 이번에는 Vec4 포맷이 아닌 완전히 독립적인 슈퍼 스칼라 구성했다.
각 어레이 (쉐이더 프로세서)는 5종류의 완전히 분리 된 연산 유닛 (ALU) 및 분기 단위, 레지스터 파일로 구성된다. 각 연산 유닛은 각각 독립적인 슈퍼 스칼라 방식으로 동작한다"라고 R600의 아키텍트인 Eric Demers 씨 (Senior Architect, AMD Graphics Products Group)는 설명한다.
R600의 쉐이더 프로세서 안의 연산 유닛은 모두 동일한 스레드 중 별도 명령을 병렬로 실행할 수 있다. 분리 된 스칼라 연산 유닛이 되어, 각각 개별 레지스터에 대해 별도의 오퍼레이션이 가능하다. 예를 들어, 연산 유닛 A가 명령 A를 레지스터 A에 대해 연산 유닛 B가 명령 B를 레지스터 B에 대해 각각 실행 할 수 있다. 즉, Intel과 AMD의 CPU와 같이 개별 유닛이 개별적으로 작동 할 수 있다. 더 CPU 하게 되었다 할 수 있다.
다만 AMD는 실행 유닛을 작동시키는 명령의 형식에 VLIW (Very Long Instruction Word) 방식을 채용했다. VLIW는 긴 명령어 안에 복수의 명령을 넣을 수 있다. 명령을 컴파일 할 때 병렬로 실행 할 수 있는 여러 명령어를 추출해 1 개의 VLIW 명령어의 안에 넣는다. 프로세서 측에서는 VLIW 명령 중에서 개개의 명령을 꺼내 복수의 연산 유닛으로 병렬로 실행한다. 1 개의 VLIW 명령에 포함된 명령은 모두 컴파일러에서 병렬 실행이 가능하다는 것이 검증되고있 다. 따라서 프로세서 측에서는 의존성 체크를 해서 명령을 병렬화로 바꿀 필요가 없다. 프로세서를 심플하게 할 수있다.
그림에 따라 설명하면 GPU에서 실행하는 명령 스트림 중에서 컴파일러가 의존성이없는 명령어를 추출한다. 예를 들어, 명령 A에 이어지는 명령 B, 명령 C, 명령 D, 명령 E가 각각 의존성이 없는 경우에는 A / B / C / D / E 5 명령을 동시에 실행할 수 있다. 그러면 컴파일러가 명령 A, B, C, D를 1 개의 VLIW 명령 안에 넣는다. 실행시에는 쉐이더 프로세서 안에 스칼라 실행 유닛 군이 VLIW 안의 각 명령을 개별적으로 실행한다. 그림의 경우는 스칼라 연산 유닛 A가 VLIW 안의 명령 A를 연산 유닛 B가 명령 B를 실행한다.

R600의 개요
스레드 수준의 병렬성에 초점을 맞춘 G80
NVIDIA의 G8x 아키텍쳐는 R6xx 와는 반대적이다. G8x에서도 연산 유닛을 SIMD 는 아닌 스칼라로 구성하고 있다. 각 스칼라 연산 유닛이 각각 개별 데이터 아이템에 대해 명령을 실행할 수 있다. 픽셀 프로세싱을 예로 들면, G8x에서는 스칼라 연산 유닛 각각을 다른 픽셀에 대해 처리를 행 할 수 있다. 예를 들어, 연산 유닛 A가 픽셀 A를 처리하고 연산 유닛 B가 픽셀 B를 이라는 구성이다.
하지만 G8x 아키텍쳐의 경우 1개의 쉐이더 클러스터 (Streaming Multiprocessor : SM) 안의 8개의 스칼라 연산 유닛은 동일한 클럭 사이클에 동일한 명령만 실행이 가능하다. 즉, 사이클 0 에는 연산 유닛 A가 명령 A를, 픽셀 A에 대해 연산 유닛 B가, 명령 A를 픽셀 B에 대해 실행한다. 연산 유닛 자체는 스칼라 구성으로 독립 동작이 가능하지만, 명령 실행의 구조 자체는 쉐이더 클러스터인 SM 전체로 보면 SIMD 발행되고 있다. SIMD 발행이지만, 각 연산 유닛의 처리 자체는 다른 데이터 아이템에 따르기 때문에 병렬로 된다. 명령 레벨의 병렬성이 아니라 "스레드 수준 병렬성 (TLP : Thread-Level Parallelism)"에 보다 근접한 아키텍처다.
다만 실제로는 NVIDIA의 G8x 계의 연산 프로세서는 일반적인 부동 소수점 적화산유닛 외에 더 복잡한 연산을 행하는 슈퍼 펑션 유닛이 있다. 이것은 4개의 적화산 유닛간에 공유 리소스에서 다른 명령을 실행할 수 있는 구조로 되어 있다. 그러나 적화산(MAD)은 싱글 파이프로 되어 있다.

G80의 개요
R600과 G80은 각각의 장점과 단점이 있다
AMD와 NVIDIA의 각각의 방식은 각각의 장점과 단점이있다. AMD 방식에서는 하나의 스레드의 명령 스트림에서 복수의 명령을 병렬로 실행할 수 있다. 이른바 "명령 레벨의 병렬성 (ILP : Instruction-Level Parallelism)"이 높다. 따라서 슈퍼 스칼라 CPU와 마찬가지로 스칼라 명령 중심의 코드 에서도 비교적 낮은 주파수에서 높은 스레드 성능을 실현할 수 있다.
그 반면 각 명령어 사이의 의존성을 체크하고 병렬로 바꾸는 명령 스케줄링이 필요하다. Intel과 AMD의 CPU는 하드웨어로 의존성을 체크하여 병렬 실행할 수 있지만 그 방식은 프로세서 복잡화 시키기 때문에 GPU에서는 채용하기 어렵다. AMD는 GPU에서는 소프트웨어로 병렬로 바꾸는, VLIW 방식을 선택했다.
문제는 컴파일러가 해비 워크에 이르게 된다. 실시간 컴파일러가 명령의 의존성을 체크하고 병렬로 바꿔, VLIW 안에 팩해야 한다. 이것은 직렬 태스크로 무거운 처리이다. 또한 훌륭히 팩 하지 못해, 의존성이 있는 명령이 계속되는 경우에는 이론치의 피크 성능을 끌어낼수 없는 걱정이 있다.
그에 비해 NVIDIA 방식에서는 명령 레벨의 병렬성에 초점을 하지 않는다. 따라서 명령간에 의존성이 있는 스칼라 코드를 빠르게 실행할 수 있다. 또한 컴파일러 워크는 종래의 GPU 처럼 매우 편하다.
그러나 그 반면, G80의 접근의 경우 많은 스레드를 제어 할 필요가 있다. 각 스칼라 유닛이 각각 다른 픽셀을 처리하기 위해 G8x 아키텍쳐에서는 작은 단위로 쉐이더 클러스터를 짤 필요가 있다. 실제로 NVIDIA는 8 개의 스트리밍 프로세서로 클러스터로 있는 "Streaming Multiprocessor (SM)" 을 구성하고 있다. 클러스터의 입도가 작아지기 때문에 스레드 수가 증가한다. 예를 들어, R600은 특정 클럭 때에 실행하는 스레드는 4 스레드이지만, G80 경우 16 스레드가 된다. 따라서 스레드 제어가 더 복잡해진다.
GPU 에서는 반드시 불리는 아닌 VLIW
R600 안고있는 장애물은 Transmeta의 VLIW 형 CPU "Crusoe" 나 "Efficeon"에 가깝다. Transmeta 아키텍처 에서는 x86의 직렬 명령어 스트림을 병렬 VLIW 명령 형식으로 실시간 컴파일 했다. 이 방식은 Transmeta CPU가 PC 시장에서 사라졌기 때문에 이미지가 나쁘다.
하지만 GPU의 특성을 생각하면 VLIW로 컴파일은 반드시 나쁜 아이디어는 아니다. CPU의 경우, 경우에 따라서는 스파게티 처럼 된 복잡하고 장대한 명령어 스트림을 병렬화 해야 한다. 또한 싱글 스레드 성능이 중요하고 짧은 지연 시간이 요구되기 때문에 실시간으로 최적화 해 나갈 필요가 있다.
그것에 비해, GPU는 그래픽에서도, 비 그래픽에서도 비교적 짧은 프로그램에서 방대한 데이터에 대한 처리를 행하는 경우가 많다. 따라서 명령 스케줄에 어느 정도 시간을 들여 최적화 된 VLIW 코드에서 단번에 많은 데이터를 처리하는 등 스타일 것이 이치에 이른다. 또한 실행 파이프가 방대한 작업을 해내고 있는 동안 명령 예약 할 수 있다. 명령 스케줄링이 필요없는 SIMD 명령어가 많을 경우에는 더욱 오버 헤드가 줄어든다.
또한 CPU 측의 진보도 R600을 돕는다. CPU는 점점 멀티 코어화를 추진하고 있으며, CPU의 연산 리소스도 증가하고 있다. VLIW 명령으로의 스케줄링의 용도인 직렬 작업은 CPU의 숙련된 작업이다. 드라이버가 무거워져도, 멀티 코어화 된 CPU에는 그에 응할 수 있는 여유가 있다.
쉐이더 코어 전체의 구성이 크게 다른 R600과 G80
이러한 설계 사상의 차이로 부터 R600과 G80에서는 쉐이더 코어 어레이 구성이 전혀 다르다. R600 방식에서는 셰이더의 스칼라 연산 유닛은 5 유닛으로 쉐이더 프로세서를 구성하고 있다. 이 쉐이더 프로세서 안에서는, 명령은 VLIW 의해 슈퍼 스칼라로 발행된다.

R600/G80 쉐이더 구성
그리고 쉐이더 프로세서는 16 개씩 쉐이더 클러스터 "SIMD 어레이"를 구성하고 있다. SIMD 어레이에서 각 쉐이더 프로세서에 대해 VLIW 명령이 SIMD 발행된다. 즉, 같은 VLIW 명령이 16개의 유닛에 대해서 발행 된다. 1개의 SIMD 어레이 안의 16개의 쉐이더 프로세서는 다른 VLIW 명령을 실행 할 수 없다. 동시에 같은 VLIW 명령을 실행한다. R600의 경우는 이 쉐이더 클러스터 SIMD 어레이가 4개 탑재되어 있다. 즉, 4 스레드가 동시에 달리는 구조로 되어 있다.
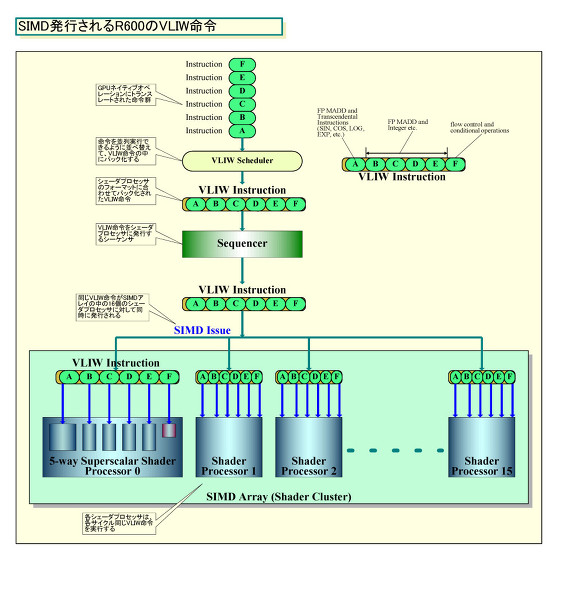
SIMD 발행되는 R600의 VLIW 명령
G80은 원래 종래와 같은 쉐이더 프로세서의 구조는 분해되어 버렸다. 쉐이더 클러스터에 해당하는 Streaming Multiprocessor (SM) 안에 8개의 연산 유닛인 스트리밍 프로세서가 있다. 각 연산 유닛이 쉐이더 프로세서 같은 이미지다. 그리고 8개의 유닛에 대해 명령 유닛이 명령을 SIMD 발행한다. R600과 달리 각 유닛은 개별 명령을 달리게 할수 없다. 같은 명령을 단계별로 실행 해 간다.
G80의 경우 이 클러스터 Streaming Multiprocessor이 2개로, 1개의 보다 큰 클러스터 "TPC (Texture Processor Cluster) '를 구성하고 있다. G80 전체에서는 TPC가 8개 가지고 있다. 각 Streaming Multiprocessor에 포함되는 프로세서 코어가 8개인 것은, 분기 입도를 작게 유지 때문이다.
쉐이더 프로세서에서 실행 레이턴시를 은폐하기 위해 여러 데이터 아이템에 대한 작업을 연속적으로 행한다. 8개의 프로세서가 각각 4 픽셀에 대한 명령을 4 사이클에 걸쳐 실행하면 32 픽셀 입도가 된다. 입도를 32까지 유지하려면, 8 프로세서 구성으로 되어 버린다. 따라서 동시에 제어해야한다 스레드 수가 늘어난다.
이렇게 살펴보면 G80과 R600은 각각의 설계 사상을 추구한 결과 필연적으로 태어난 아키텍처라는 것을 알 수 있다.
2007년 5월 18일 기사 입니다.
[분석정보] NVIDIA, Radeon HD 2000의 사양에 이의
[분석정보] Larrabee에 쫓기는 NVIDIA가 GT200에게 입힌 GPGPU용 확장
[분석정보] 지포스 GTX 280 배정밀도 부동 소수점 연산
[정보분석] 엔비디아 세계 최다 트렌지스터 칩 GK 110 공개
[분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA
[분석정보] Sandy Bridge와 Bulldozer 세대의 CPU 아키텍처
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] AMD가 2009년의 CPU 코어와 통합 CPU의 개요를 발표 (0) | 2007.07.27 |
|---|---|
| [분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA (0) | 2007.06.18 |
| [분석정보] 인텔이 추진하는 32코어 CPU Larrabee (0) | 2007.06.11 |
| [분석정보] 고속화를 가져오는 Radix-16 Divider와 shuffle Engine (0) | 2007.05.24 |
| [분석정보] NVIDIA, Radeon HD 2000의 사양에 이의 (0) | 2007.05.15 |
| [분석정보] 임베디드 시장에 IA 침투를 목표로 하는 Intel (0) | 2007.05.07 |
| [분석정보] 초저소비 전력을 달성한 Silverthorne의 비밀 (0) | 2007.04.26 |
| [분석정보] 또 하나의 초저소비 전력 CPU Silverthorne (0) | 2007.04.25 |