45nm 공정의 Intel PC 용 CPU와 LPIA를 비교
Intel은 내년 (2008년) 전반, 초 저소비 전력의 CPU "Silverthorne (실버쏜)"을 투입한다. 이것은 Intel의 휴대기기용 IA-32 계열 CPU "LPIA (Low Power Intel Architecture)"라인으로 신규 설계된 최초의 CPU가 된다.
이전 보고서 에서 설명했듯이, Silverthorne은 매우 작다. 다이 크기 (반도체 본체의 면적)는 약 26 제곱 mm로 추측된다 (한참후에 인텔이 ISSCC에서 직접 밝힌 크기가 25 제곱mm로 거의 정확한 추측). 같은 45nm 공정의 Core Microarchitecture (Core MA) CPU "Penryn 6M"은 107.6 제곱 mm인 것으로, 듀얼 코어의 Core MA의 4 분의 1 정도의 다이 크기가 된다. 아래는 Intel의 슬라이드 Penryn 6M과 Silverthorne을, 동 스케일이 되도록 수정한 것이다.

IDF에서 보인 Penryn과 Silverthorne의 슬라이드의 정확한 비율판
이 슬라이드를 베이스로, 양 CPU 다이를 큰 블록 단위로 분해해서 비교해 보면, Silverthorne의 비밀이 보인다.
Penryn과 Silverthorne에서 거의 같은 크기의 I / O
먼저 Penryn의 I / O 블록에 대해서는 다이 상의 위치는 명확하게 알고 있다. Penryn에서는 CPU 코어의 왼쪽, 위 슬라이드의 다이 사진 상에서는 다이의 위 가장자리에 "I / O 어드레스"의 PHY가 위치한다. 그 반대 측면, CPU 코어의 오른쪽, 위의 슬라이드에서는 다이 아래 가장자리에 "I / O 데이터"의 PHY가 있다. 2개의 I / O 영역의 띠가 CPU의 양 측면에 위치한다.
I / O PHY 블록은 신호선의 인출을 위해 다이의 가장자리에 배치 할 필요가 있다. 그리고 인터페이스 폭이 넓은 병렬 버스인 현재의 Intel CPU의 FSB (Front Side Bus)는 어느 정도의 가장자리가 필요하다. CPU의 경우 통상 4개의 가장자리의 어느정도를 I / O 영역에 쓰고, 그 외의 가장자리에서 전력선을 끌어들이는 구조를 채용한다.
Silverthorne의 다이를 보면, 이쪽에도 상하에 I / O 블록으로 보이는 띠가 있다. 이 크기를 측정해 보면, 꼭 Penryn 상하의 I / O PHY 블록과 같은 정도가 된다. Penryn도 Silverthorne도 같은 정도의 다이 면적을 I / O에 할애하는듯 보인다.
그렇지만, 이것은 이상한게 아니다. 두 CPU의 FSB (Front Side Bus)는 기본적으로 동일한 아키텍처기 때문이다. Silverthorne도 Pentium 4 이후의 FSB를 사용하고 있다. 이 I / O 블록을 보면 직사각형의 Silverthorne 다이 모양이 어떻게 정해졌는지 잘 판명된다.
CPU의 경우 제의 형태는 정사각형에 가깝게 것이 이론이다. 그것이 비해 Silverthorne는 이례적으로 종횡비가 큰 직사각형으로 되어있다. 이것은 직사각형 쪽이 동일한 다이 면적에서도 가장자리가 길어지기 때문이라고 추측된다. 직사각형이라면 패드를 위해 가장자리에 일정한 폭을 확보 할 필요가 있는 I / O 블록에 긴 가장자리 길이를 확보 할 수있다. 반대로, 실버쏜의 경우 전력 소비가 적기 때문에, 전력선 인입 부분은 적어진다.
참고로, 현재 제공되는 제 1 세대 LPIA "A100 / A110 (Stealey)"는 400MHz FSB지만 Silverthorne는 533MHz FSB로 된다고 말한다.

Silverthorne과 Penryn의 비교 : I / O
Silverthorne의 캐시 크기는 512KB
Penryn과 Silverthorne의 L2 캐시는 크기에 큰 차이가 있다. Penryn 6M는 6MB의 공유 캐시 SRAM을 탑재하고 있다. 캐시 SRAM 어레이는 Penryn 전체의 3할 이상에 해당한다. 그에 반해 Silverthorne의 L2 캐시는 명확히 SRAM 어레이라고 판명되는 부분만 이라면, Penryn의 10 분의 1 정도의 크기로 보인다.
여기에서 Silverthorne의 L2 캐시는 512KB로 추측 가능하다. 단순 계산으로의 사이즈보다 조금 크지만, 1MB 분의 캐시 SRAM이 있다고는 보이지 않는다. Silverthorne의 L2 캐시가 512KB 라고 하면, 제 1 세대 LPIA인 "A100 / A110 (Stealey)'와 같은 양, 6MB의 듀얼 코어 Penryn의 12 분의 1이 된다. Core MA와는 L2 캐시의 양은 상당한 차이가 있다.
그러나 L2 캐시의 양은 성능에 선형으로 반영되지 않는다. 통상 일정량을 초과하면 캐시의 효과는 포화되기 시작한다. 특히 Silverthorne 노리는 시장처럼, 비교적 작은 응용 프로그램이 주체에, 병렬로 실행하는 소프트웨어도 한정되는 경우, 캐시의 양이 적더라도 영향은 낮다고 추측된다. (데스크탑 처럼 무거운 소프트를 돌리는 시장이 아니니)
캐시는 트랜지스터 수가 많기 때문에, 누설 전류 (Leakage)가 많다. 통상 CPU 총 소비 전력에서 캐시의 전력이 차지하는 비중은 크지 않지만, 누설 전류만을 보면 캐시의 비율은 높다. 휴대 기기를 노린다면 캐쉬량을 억제하는 것은 의미가 있다.

Silverthorne과 Penryn의 비교 : 캐시
CPU 코어는 Core MA의 절반 크기
Silverthorne과 Penryn의 비교에서 가장 흥미로운 것은 CPU 코어의 크기다. 아래 그림의 CPU 코어 부분의 좌측이 Penryn의 CPU 코어의 1 개분. 오른쪽이 Silverthorne의 CPU 코어와 추측되는 부분. 단순 비교에서는 Silverthorne 쪽이 절반 강도 정도의 면적에 보인다.
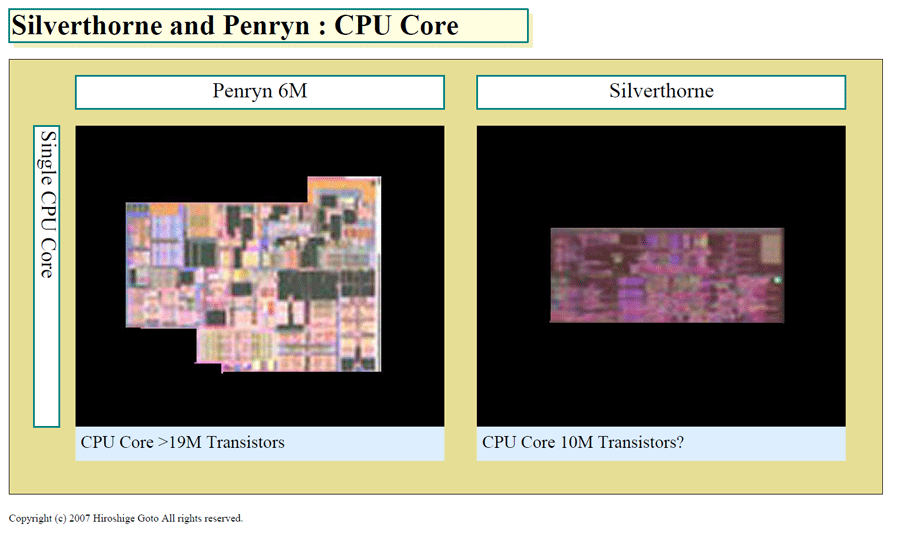
Silverthorne과 Penryn의 비교 : CPU 코어
참고로, 65nm 버전의 Core MA 인 "Core 2 Duo (Merom : 메롬)의 CPU 실행 코어 1 개의 트랜지스터 수는 19M (1,900만). 이것은 Hotchips과 ISSCC (IEEE International Solid-State Circuits Conference) 에서 발표 숫자다. 실은, Core MA도 CPU 코어는 꽤 트랜지스터 수를 억제한 컴팩트 설계로 되어있다.
45nm의 Penryn에서는, Radix-16과 처럼 트랜지스터를 먹는 확장이 더해졌기 때문에, Merom보다 트랜지스터 수는 많아질 것이다. 그러나 그럼에도 20M (2,000만)을 크게 초과 한다고는 생각되지 않는다. CPU 코어의 외관상의 레이아웃이 극적으로 변하듯이 보이지 않기 때문이다. Silverthorne의 CPU 코어가 Penryn의 절반 가량으로, Penryn의 코어가 20M 정도라고 하면, 단순 비교에서는 Silverthorne의 CPU 코어는 10M (1,000만) 트랜지스터 정도의 규모라는 추측이 가능하다.
Silverthorne를 10M 트랜지스터로 가정해서, 과거의 x86 CPU 코어와 비교하면 L2 캐시가 없는 Pentium III (Katmai : 카트마이)가 9.5M (950만)으로 가깝다. 즉, Silverthorne는 P6 마이크로 아키텍처 (Pentium Pro)에 SSE 확장판을 더한 정도 규모의 CPU 코어라는 것이다. CPU 코어으로는 Core MA과 비교하면 1 세대분 작다. Merom과 명령 세트 호환 (SSE3까지 구현) CPU를 만들기에는 꽤 궁핍한 트랜지스터 수 처럼 보인다.
CPU 설계의 이론에서는 논리적인 Silverthorne의 설계
Silverthorne의 작은 CPU 코어는 무엇을 의미하는가.
CPU 설계의 유명한 경험법칙에, 동일한 공정 기술에서 싱글 코어 CPU의 다이 크기 (= 트랜지스터 개수)를 2 ~ 3배 늘려도 정수 연산 성능은 그 제곱근 (약 1.4 ~ 1.7 배) 정도 밖에 늘지 않는다는 것이 있다. Intel이 "폴락의 법칙 (Pollack 's Rule)"라고 부르는 법칙 (Law 가 아닌 Rule)이지만, Intel이 명명한 이전부터 CPU 업계에는 알려져 있었다.
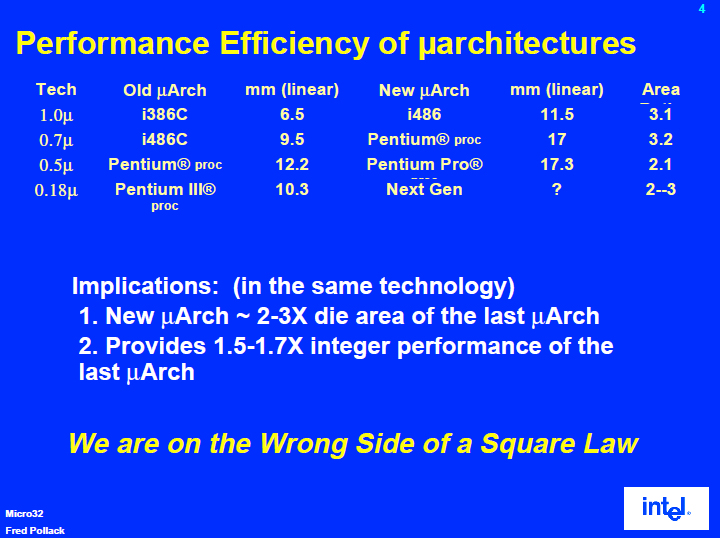
마이크로 아키텍처의 성능 효율
이 경험법칙의 포인트는 소비 전력이다. 트랜지스터 수를 두 배로하면 소비 전력은 이론상 두배로 된다. 2 배의 전력으로 1.4 배의 성능 업이 되면, 소비 전력 당 성능은 70%로 떨어지고 만다. PC용 CPU 코어는 이러한 비효율적인 성능 향상을 계속해 왔다. 즉, 성능을 위해 효율 (성능 / 소비 전력, 성능 / 트랜지스터)을 희생해 온 것이다.
따라서 CPU 코어의 전력 효율을 올리는 방법은, 이론상은 비교적 간단하다. CPU 진화를 반대로 돌려서, 진화마다 늘려 온 기능을 덜어, CPU 코어를 심플하게 하면 된다.
Intel이 Silverthorne에서 행한 것은 바로 이것이다. Penryn의 2 분의 1 규모의 CPU 코어의 Silverthorne는, 폴락의 법칙에서의 이론치에서는 정수 연산 성능은 0.7 배로 내려 간다. 그러나 CPU 코어 부분의 소비 전력은 절반인 0.5 배로 내려 간다. 따라서 성능 / 소비 전력과 성능 / 다이는 1.4 배로 오르게 된다.
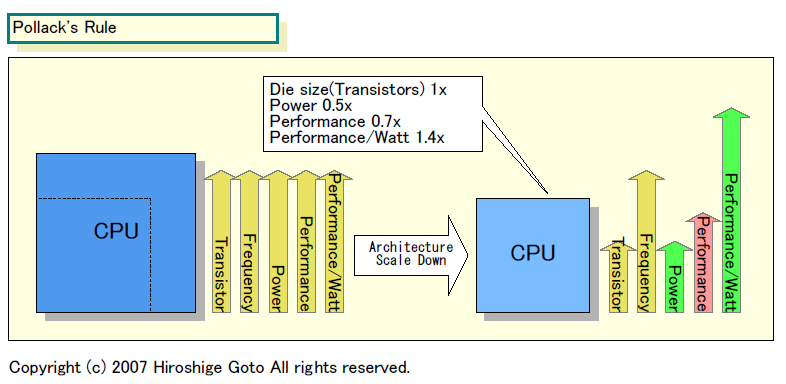
폴락의 법칙
소비 전력은 절반으로 성능 수준은 70%로
다만 CPU 코어만을 비교한 것으로는 정확하다고는 말할 수 없다. L2 캐시 시스템이나 I / O를 포함한 전체 CPU를, 같은 싱글 코어 CPU와 비교하지 않으면 안된다. Penryn에는 원래 싱글 코어의 Penryn-2M의 프로젝트가 있다. 싱글 코어에 2MB L2 캐시 버전으로 Penryn-L이라고도 불린다. 이 코어가 제품화 되는지 어떤지는 알 수 없지만, 설계상의 다이 크기는 판명되어 있다. 1년 전 계획의 다이 크기는 58 제곱 mm지만, Penryn 코어는 프리실리콘의 단계보다 몇 % 커지고 있었기에, 실제로는 60 제곱 mm 정도가 된다고 추정된다.
그에 비해서 Silverthorne의 다이는 30 제곱 mm를 훨씬 밑돈다. 그러나 대략으로는 2 분의 1이라고 말해도 괜찮다. 그러면 CPU 코어 단독을 비교한 경우와 폴락의 법칙의 효과는 거의 같다고 추측된다. 이렇게 가정하면, Silverthorne의 성능의 이론치는 다음처럼 된다.
3W TDP시의 Penryn-2M의 성능에 비해서 1.5W TDP의 Silverthorne의 정수 성능은 0.7 배. 같은 LPIA끼리 비교한다면 현재의 LPIA 계 코어인 Dothan 코어보다 Penryn 쪽이 성능이 1.x 배인 것을 가미할 필요가 있다. 또 LPIA Dothan은 L2 캐시도 512KB로 억제되어있다. 단순하게 말해서 3W의 LPIA Dothan 512KB 비해서, 1.5W의 Silverthorne는 적당히 가까운 성능 범위를 달성 가능하다고 생각해도 좋을 것이다.
물론 이것은 이론상의 얘기지만, CPU 설계는 마술이 아닌, 물리 법칙에 지배된다. 1 명령을 실행하기 위해, 필요한 로직이나 전력은 어느정도 정해져 있다. 따라서 대략적으로 말하면, 이 비교가 합당할 것이다. 그러면 Silverthorne에서는 구체적으로 어떤 사양을 도입, 어떤 아키텍처를 취하는 것인가. 다음에는 그것을 리포트 하자.

TDP 저하의 변천
2007년 4월 26일 기사
(다른 모든 글도 그렇지만, 이 글처럼 이론적인 배경으로 설명하는 것은 그런 방향성을 봐야 합니다. 실제로는 설계나, 공정등의 변수가 있기 때문이죠. 물론 그럼에도 불구하고 이렇게 설명할 수 밖에 없구요. 모든 걸 다 추론할 수도 없죠. 이건 누가 글을 써도 그렇게 될 수 밖에 없겠죠. 세부적으로 따질 것들은 다른 글을 통해서 그 부분만을 다시 말하던가 해야 할테구요. 아무튼 확실한건 정확한 %로 되지는 않더라도 전체적인 방향성은 그 방향이 맞다는 겁니다. 모든걸 다 무시하고 외계인 기술로 역으로 가기는 힘들다 이게 핵심 입니다. 또 이런 기사나, 개인의 생각이나, 추측이란 것은 아주 다양한 근거를 토대로만 이뤄져야 합니다. 근거가 없는 막연한 생각이나(특히나 무슨 정황이니, 정황이 사실과 다른 경우는 아주 많고, 정황으로 판단 할수도 없죠.), 단순 근거로 추측하는 것은 추측이 아닌 상상이 됩니다. 시청자들이 TV 미스터리 관련, 무슨 수사 관련 프로그램을 보면서 근거는 없고(증거), 정황 짜맞추기 수사를 보고 욕을 하게 되는, 그 욕을 먹는 사람의 행동을 각자 스스로가 하게 되는 거죠 (살인의 추억 초반 형사 송강호 같은 경우나). 모든 근거가 없고, 모든 상황을 알 수 없으니까 추측을 하는거지만, 그 추측에는 반드시 아주 아주 다양한 근거가 있어야 합니다. 수사도 어렵고 알수도 없는 정치하고 이런 쪽은 다르죠.)
[고전 2001.01.11] Intel의 0.13μm 공정 P860/P1260에서 CPU는 어떻게 바뀌나
[고전 2001.01.17] 10GHz CPU를 실현하는 Intel 0.03μm 트랜지스터 기술
[고전 2001.02.06] 2010년 CPU 전력은 600W?
[고전 2001.02.07] 인텔 폴락의 법칙이 등장 Intel 겔싱어 CTO의 ISSCC 강연
[고전 2001.02.08] Intel은 멀티 쓰레드 CPU로 향한다. Intel 겔싱어 CTO ISSCC강연
[고전 2004.11.05] 폴락의 법칙을 깨뜨리기 위한 멀티 코어
[고전 2004.12.24] 폴락의 법칙에 찢어지고 취소된 테하스(Tejas)
[분석정보] 심플 코어로 향하는 차세대 CPU 아키텍처
[분석정보] 결정된 헤테로지니어스 멀티코어에 대한 기류
[분석정보] CeBIT에서 보는 UMPC의 현재와 미래
[분석정보] Intel, 45nm공정의 차기 CPU Penryn 자세히 공개
[분석정보] 고기능 고성능 + 에너지 절약 저비용을 양립시키는 Intel의 대처
[분석정보] IDF 2007 Penryn 벤치마킹 세션 리포트
[분석정보] 전면 개량이 아닌 부분 개량에 머문 Penryn
[분석정보] 모바일 절전 기능을 강화한 펜린 (Penryn)
[분석정보] 임베디드 시장에 IA 침투를 목표로 하는 Intel
[분석정보] 고속화를 가져오는 Radix-16 Divider와 shuffle Engine
[아키텍처] 정수 연산 성능을 희생해서 효율성을 거둔 AMD의 "Bulldozer"
[분석정보] 인텔의 스칼라 CPU + 라라비의 이기종 CPU 비전
[정보분석] IDF 2011 Justin Rattner 기조연설 매니코어 시대가 다가옴 1/2부
[분석정보] 또 하나의 초저소비 전력 CPU Silverthorne
[분석정보] Intel이 드디어 Silverthorne과 Tukwila의 개요를 발표
[분석정보] 20년 후인 지금도 곳곳에서 살아남은 펜티엄 아키텍처
[분석정보] CPU와 메모리의 속도 차이를 해소하는 캐시의 기초지식
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] 고속화를 가져오는 Radix-16 Divider와 shuffle Engine (0) | 2007.05.24 |
|---|---|
| [분석정보] 크게 다른 Radeon HD 2000과 GeForce 8000의 아키텍처 (0) | 2007.05.18 |
| [분석정보] NVIDIA, Radeon HD 2000의 사양에 이의 (0) | 2007.05.15 |
| [분석정보] 임베디드 시장에 IA 침투를 목표로 하는 Intel (0) | 2007.05.07 |
| [분석정보] 또 하나의 초저소비 전력 CPU Silverthorne (0) | 2007.04.25 |
| [분석정보] 모바일 절전 기능을 강화한 펜린 (Penryn) (0) | 2007.04.23 |
| [분석정보] AMD "Barcelona"는 가장 빠른 Xeon 보다 50% 고속 (0) | 2007.04.23 |
| [분석정보] 전면 개량이 아닌 부분 개량에 머문 Penryn (0) | 2007.04.20 |