
MicroProcessor Forum 2007 리포터
기간 : 5월 21일 ~ 23일 (현지 시간)
장소 : 미국 캘리포니아 주 새너제이
DoubleTree Hotel
Microprocessor Forum (MPF)은 미 In-Stat가 개최하는 프로세서 관련 컨퍼런스 이벤트다. 작년 (2006년)까지 봄과 가을 2회 개최에서 봄은 임베디드 계, 가을은 범용 프로세서 계열로 나뉘어 있었지만 올해부터는 연 1회 개최되며, 두 분야를 동시에 처리하도록 되었다.
이번 컨퍼런스 프로그램을 대충 개관하면 첫날이 범용 CPU와 임베디드 계의 Automotive 관련 프로세서, 2일째 미디어 계 및 임베디드 통신 계열 프로세서 등을 다룬다.
Intel이 Penryn 등의 개요를 보고
우선 Intel의 Mark Bohr 씨의 "The New Era of Scaling for Energy Efficient Processors"라는 제목의 기조 강연을 했다. 그 내용은 4월 베이징에서 개최된 IDF에서 Bohr 씨의 연설과 거의 겹치는 것이었다.
첫 번째 세션인 "Advances in Computer Technology"를 담당한 것은 Intel의 Mark Bohr 씨 이하의 3가지 주제에 대해 연설이 진행됐다.
(1) 45nm Next-Generation Intel Core Microarchitecture (Penryn)
(2) Beyond Multicore : The Dawning of Era of Tera
(3) Reinventing Multicore Cache & Memory : Architecture, Performance and QoS
(2)는 지난해 ISSCC에서 발표된 "Teraflops Research Processor "의 반복이다.
(1)에서 이번에 새롭게 Penryn (울프데일, 요크필드)의 디바이더 대한 정보가 공개되었다. 이미 뉴스 등은 "Radix-16 divider"가 탑재되어 나눗셈이 고속화 된 것이 보도되고 있다. 이번 컨퍼런스에서는 그 개요가 공개되었다.

첫날 첫 번째 기조 강연을 한 Intel Senior Fellow, Technology and Manufactureing Group Director, Process Architecture and integration의 Mark Bohr 씨

Penryn의 아키텍처에 대해 설명하는 Steve fischer 씨 (Senior Principal Engineer)

매니 코어 시대의 캐시 및 메모리에 대해 이야기 한 것은 Ravi Lyer (Principal Research Scientist) 씨
고속화를 실현하는 Radix-16 Divider란?
나눗셈을 행하는 회로 (제산기 : Divider)의 구현 방법에는 여러 가지 종류가 있지만 주로 사용되는 것으로는 "감산 시프트","곱셈 형"등이 있다. 전자는 각 수의 계산을 수행 할 때 시프트 처리와 가감산 조합으로 처리를 행하는 것이고, 후자는 곱셈을 사용하는 방법이다.
Radix-16 Divider는 그 구조에서 "감산 시프트 형"으로 분류되는 것으로 보인다. 이 경우, 빠른 가감 처리를 행할 필요가 있다. 나눗셈은 나눠지는 수 (비제수) 속에 나눈 수가 몇개 포함되어 있는가 하는 것이다. 예를 들어 10 ÷ 2의 몫은
10 = 2 + 2 + 2 + 2 + 2
10 = 2 x 5
라는 것에서 5가 구해지는 것이다. 이처럼 나눗셈은 덧셈이나 곱셈을 반복해서 계산할 수 있다. 그러나 큰 숫자는 몫을 찾기가 어렵다. 따라서 인간이 행하는 필산처럼 나눗셈을 각 자리마다 처리한다. 이 때, 몇 비트 동시에 할 것인가에 계산 시간이 바뀐다. Radix-16 Divider는 한번에 2 진수로 4 자리 (4bit)를 계산하는 것이다. Radix-16은 "기수 16"이라는 뜻으로, 한 번에 4bit 처리하기 때문에 "기수 16"이라고 명명한다.
기존의 Merom (콘로, 켄츠필드. 참고로 AMD는 스팀롤러에 와서야 Radix-8 디바이더)은 Radix-4, 즉 2bit 단위로 계산하는 디바이더가 사용되고 있었다. 이 때문에 Radix-16 Divider를 사용하면 2배 정도의 고속화로 처리된다.
자릿수가 늘어 나면 전체의 계산은 빨리 끝나지만 계산하는 회로가 복잡해진다. 따라서 일반적으로는 1 또는 2bit로 계산하는 회로가 사용되는 경우가 많다.

Penryn의 Radix-16 Divider는 4bit를 1클럭으로 처리하기 때문에 기존의 Radix-4 Divider 보다 두배의 성능을 갖는다.
베이징에서 개최된 IDF에서, Mobile Platforms Group의 General Manager 인 Mooly Eden 씨는 Penryn에서 왜 Radix-16 Divider를 구현했는가를 듣는 곳이었는데, 그 구현에 필요한 트랜지스터 수가 많아 이번 간신히 이를 구현 가능한 트랜지스터를 확보했기 때문이라는 대답이 돌아왔다. 즉, 지금까지는 이러한 개량을 하려해도 회로 규모가 너무 커서 곤란했던 것이다.
구체적으로는 Radix-16 Divider는 2 단계의 루프 구조로 되어 있고, 1회 루프로 4자리 (4bit) 부분 나눗셈을 행할 수있게 되었다.
중심이 되는 것은 Hybrid Addr라는 가산기다. 가산기에는 올림수(캐리)의 처리에 몇 가지 유형으로 분류된다. 가장 간단한 것은, 캐리를 고려하여 아래의 자리수부터 순서대로 가산을 하는 것으로, 캐리 운반 형 (Carry Propagation Adder : CPA)이다. 컴퓨터 등에서는 고속화 때문에 올림수 유무와 가산 처리를 별도로 행하는 캐리 룩 어헤드 형이 사용되는 경우도 많다.
그러나 반복 계산을 고려하면, 반드시 올림수 처리를 한번에 할 필요가 없고 나중에 해도 좋다. 이러한 것에는 캐리 보존형 (Carry Save Adder : CSA)이 있다.
Hybirid Adder로는 이러한 여러 유형의 가산기를 조합한 것을 가리킨다. Penryn에 채용된 것은, CPA / CSA를 조합한 가산기라고 한다.
이러한 구조를 가지고 있기 때문에, 나눗셈의 처리 시간은 계산하는 수에 따라 차이가 난다. 그러나 기존보다 자릿수가 증가하고 있기 때문에, Radix-16 Divider는 같은 수를 계산했을 때의 계산 시간 (클럭수)이 단축된다. 특히 최소 클럭수도 작아 Penryn에서는 최소 6주기 나누기가 가능하다고 한다.
Divider는 정수 연산과 부동 소수점 연산에서 사용되며, 이 때문에 SSE 명령이 고속화 된다. 특히 SSE 관련에서는 복잡한 계산이 많아, 나눗셈을 내부적으로 사용하기 때문에 고속화가 기대 된다. 이번 Radix-16 Divider는 제곱근풀이 (루트 계산)에 최적화 되어 있다고 한다. 루트 계산은 2차원, 3차원의 그래픽이나 물리 계산등에서 자주 이용되기 때문에 이것이 고속화되면 메리트는 크다.
Intel이 공개한 자료에 따르면, 배정밀도 부동 소수점 (64bit)과 확장 배정밀도 부동 소수점 (80bit)의 처리 시간이 거의 동일하기 때문에, 부동 소수점의 경우 확장 배정밀도로 계산을 하고, 거기에서 배정 밀도의 결과를 얻는 것 같다.
또 하나의 고속화의 포인트는 Super Shuffle Engine이다. SSE 등의 SIMD 형의 명령은 연속 된 메모리 영역에 여러 데이터를 배치하고 한 덩어리로 처리한다. 이 때, 계산에 따라, 계산 도중에 bit 위치를 바꾸는 등의 처리가 필요하다. Penryn은 이러한 처리를 1 사이클로 하기 위해, 128bit의 두가지의 수치 중에 있는 bit의 선택이나 교체 등이 가능한 Super Shuffle Engine을 장착하고 있다. 이에 따라 명령의 최단 실행 시간이 단축 된다.
IA-32는, 메모리 내의 수치를 xmm 레지스터로 전송하는 명령어가 두 종류 있다. 하나는 메모리 내의 수치가 16 바이트 경계에 나란히 있는 것을 전제로 하는 movaps와 그렇지 않은 것을 허용하는 movups 명령이다. moveaps 명령은 데이터가 16 바이트 경계에 있는 것이 전제가 되기 때문에 고속이지만, 정렬이 바르지 않은 주소를 지정하면 에러가 되어 버린다. 반대로 movups에서는 정렬은 임의이지만, 그만큼 실행 시간이 늦어진다. 이 때 Penryn에서는 Super Shuffle Engine에 의해 movups 명령이 고속화 된다고 한다.
매니코어 시대의 캐시와 메모리
대단히 많은 코어가 이용 가능한 시스템으로, 어떻게 코어의 가동률을 향상시킬 것인가는 크게 두 가지 방법이 있다. 하나는 아주 많은 스레드를 사용하는 응용 프로그램을 동작시키는 방법이 있다. 그러나 어떤 응용 프로그램에서도 다수의 스레드가 필요한 것은 아니며, 스레드를 많이 생성하는 알고리즘을 채용해 응용 프로그램을 개발할 필요가 있다.
또 다른 방법은 다수의 가상 머신을 작동시키는 방법이다. 각 가상 머신 내에서 실행되는 운영 체제와 응용 프로그램은 기존의 싱글 ~ 쿼드 코어 정도의 시스템을 상정한 것으로 상관 없다. 더 많은 가상 머신을 동시에 동작 시키는 것으로, 코어의 효율적인 운영이 가능하게 된다.
이러한 상황을 생각하면, 메모리나 캐시의 구조에 대해 다시 생각하지 않으면,라는 것이 마지막 세션인 "Reinventing Multicore Cache & Memory : Architecture, Performance and QoS"의 테마이다.
이야기는 다수의 스레드가 동작하는 단일 환경의 경우와 다수의 가상 머신이 동작하는 환경을 나누어 진행했다. 먼저 다수의 스레드가 동작하는 환경의 경우, 계층화 된 캐시에 문제가 생긴다고 한다. L1 ~ L3 등의 계층화 된 캐시의 경우, 2차 캐시에 저장되어 있는 데이터를 3차 캐시에도 두느냐 여부로 3 종류로 분류된다. 하나는 2차 캐시에 놓인 데이터도 그대로 3 차 캐시에 유지하는 "Inclusive", 다른 하나는 2차 캐시에 놓인 데이터는 3차 캐시에 유지하지 않으나 데이터 세트로는 2차 캐시에 들어 가지 않는 것을 3차 캐시에 유지해 두는 "Non-Incusive"이다. 마지막 하나는 필요한 데이터 세트를 모두 2차 캐시에 두고, 불필요 하게 될 때까지 3차 캐시로 옮기지 않는 "Exclusive"이다.
각각 캐시 메모리의 이용 효율, 다른 프로세서에서 스눕 (데이터의 동일성을 확보하기 위해 캐시 상태를 서로 확인하는 것), 데이터 다시 쓰기 처리나, 3차 캐시가 2차 캐시 측의 변경을 조사하는 처리 (Backinvalidations)에서 장점, 단점이 있다.
다수의 스레드가 동작한다는 것은, 다수의 데이터 세트가 동시에 이용되는 것이기 때문에 캐시의 이용 효율을 높일 필요가 있으며, 또한 스눕 처리나 다시 쓰기 작업을 쉽게 수행 할 수 없으면 안된다.
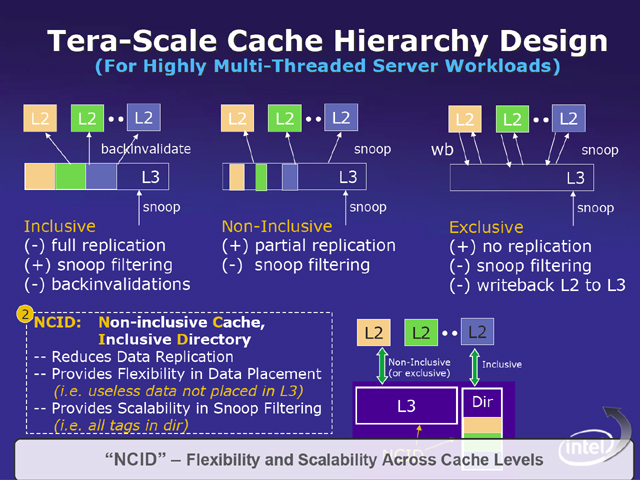
다수의 스레드가 동시에 실행될 때 효율적인 캐시 방식으로 NCID (Non-inclusive Cache, Inclusive Directory)가 연구 중이라고 한다
이러한 상황에 대해 Intel이 연구하고 있는 것이 NCID (Non-inclusive Cache, Inclusive Directory)이다. 이것은 캐시하는 데이터는 Non-Inclusive로 하지만, 캐시 데이터와 실제 메모리의 대응을 기억 Directory는 3차 캐시 측에서 공유하는 것. 이것에 의해 2차 캐시에 포함된 데이터는 3차 캐시에 기억되지 않기 때문에 이용 효율이 오르며, 외부에서의 스눕에 대해서는 3차 캐시 측의 디렉토리를 사용해서 스눕 필터 대응이 가능하게 된다.
복수의 가상 머신을 작동시키는 경우, 물리적인 CPU 코어와 스레드의 관계가 성립되지 않게된다. 쓰레드가 보는 것은 가상화 된 프로세서이다. 따라서 기존 OS가 관리하던 응용 프로그램의 동작 유형과 프로세서의 대응이 곤란하게 된다. 그렇게 되면, 예를 들어, 캐시가 대부분 유효하게 쓸 수 없는 스트리밍 데이터 처리를 하는 쓰레드와 일반 스레드가 동일한 프로세서에서 작동 할 가능성이 있다. 그외 여러 스레드가 데이터 공유에, 각각이 다른 프로세서 패키지에서 실행될 가능성이 있다. 이 경우 캐시가 유효하게 이용 될 수 없다.
그래서 응용 프로그램에 대해서 QoS 라는 개념을 도입하고, 이것을 바탕으로 자원 할당 (캐시 및 프로세서 할당)을 제어 하자는 것이 Intel의 연구이다. 즉, 실행되는 스레드가 어떤 종류인지 (어떤 할당을 요구하고 있는지)를 가상 머신 매니저 등에 전달 경로를 만들고, 또한 스레드의 동작 패턴을 하드웨어로 모니터한다. 전체를 관리하는 가상 머신 매니저 등의 소프트웨어 측은 응용 프로그램으로의 요구와 동작 모니터로의 정보를 바탕으로 할당을 제어하는 것이다.
구체적인 방법의 하나로서 QoS에 대응한 캐시라는 것이 컨퍼런스에서 제시됐다. 이것은 응용 프로그램의 우선권 등 부터 캐시를 공유하는 각 코어에서 이용하는 캐시 영역을 제어 하자는 것이다. 가상 머신 측에 QoS를 지정하는 레지스터를 두고, 응용 프로그램을 실행하는 코어는 그것을 보고 이용하는 캐시를 가감한다. 이렇게 하는 것으로 우선권이 높은 응용 프로그램에는 많은 캐시를 할당되고, 그렇지 않은 응용 프로그램에는 캐시 사용량을 제한하는 것이 가능하게 된다.

가상 머신이 다수 동작하는 환경에서는, 캐시를 공유하는 코어에서 캐시 사용법이나 요구가 다른 응용 프로그램이 작동 할 가능성이 있어,이 때 서로 방해가 일어나고, 캐시가 유효하게 쓰지 못한다는 문제가 일어날 가능성이 있다.

그 때문에 Intel은 응용 프로그램의 유형 등에 응한 자원 할당 요구와 응용 프로그램의 행동을 모니터한 정보를 종합해서 할당을 할 QoS (Quality of Service)의 개념을 도입해야 한다고 제안

구체적으로는 QoS에 대응하는 캐시 할당이 가능한 시스템을 제시했다. 응용 프로그램의 우선 순위도에 응해, 필요한 응용 프로그램 (스레드)에 대해서 이용 가능한 캐시의 양을 제한한다. 이렇게 하는 것으로, 우선 순위도가 낮아 대량의 데이터를 액세스하는 스레드가 캐시를 점유해 버려, 우선도 높은 스레드의 실행이 늦어지는 것을 방지하는 것이 가능하다. 이를 위해서는 하드웨어 측에 할당을 제어, 이용 상황을 모니터하기 위한 기구가 필요하다.
이러한 제안은 매니코어의 시스템이 등장했을 때, 그것을 어떻게 보내서 효율적으로 사용 하는가 하는 문제에 대한 해답이다. 즉, 복수의 가상 머신에 분할해서 그 중에서 기존형의 운영 체제나 응용 프로그램을 동작 시키거나, 컴파일러 등에 의해 자동적으로 다수의 스레드를 생성시켜서 그것을 실행하는 것으로, 매니 코어를 유효하게 쓰고 그 성능을 이끌어 내는 것이 가능하다.
그렇지만 한층 매니코어화가 진행되면 조만간은 응용 프로그램을 설계하는 단계에서 다수의 코어에 대응해야 한다. 가상 머신을 움직이려고 해서도 한계는 있어서, 그 안에는 재해 대책 등으로 지리적으로 떨어진 장소에 있는 물리적으로 다른 머신에서의 동작이 요구되는 것도 있기 때문이다.
오늘의 컨퍼런스에서도 이러한 매니코어에 대한 프로그래밍이나 설계 등을 어떻게 하는가 라는 질문, 지적이 있었지만, 아무도 아직 명쾌한 해답을 가지고 있지 않은 것 같다.
2007년 5월 24일 기사
[분석정보] IDF 2007 Penryn 벤치마킹 세션 리포트
[분석정보] Intel, 45nm공정의 차기 CPU Penryn 자세히 공개
[분석정보] 모바일 절전 기능을 강화한 펜린 (Penryn)
[분석정보] 래트너 CTO 기조 강연 보고서 차세대 데이터 센터 기술을 소개
[분석정보] Intel 48 코어 IA 프로세서를 개발
[분석정보] Intel 48코어 매니코어 연구 칩 기술 공개
[분석정보] Intel CTO 래트너 Tera-Scale Computing에 대해 설명
[분석정보] Intel CPU의 미래가 보이는 80코어 TFLOPS 칩
[분석정보] Many-Core CPU로 향하는 Intel. CTO Gelsinger 인터뷰 1/2부
[분석정보] 2015년 컴퓨터 플랫폼 IDF Spring 2005
[분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA
[분석정보](암달의 법칙) 2010년대 100 코어 CPU 시대를 향해서 달리는 CPU 제조사
[분석정보] TSX 대응으로 약 6배로 성능 향상된 Xeon E7 v3
[분석정보] 인텔 최대 18코어 Haswell-EP Xeon E5-2600 v3
[분석정보] AMD가 확장판 K10 코어 기반의 APU Llano 를 첫 공개
[분석정보] 인텔 데스크탑 eDRAM 버전을 포함한 브로드웰 패밀리 설명
[분석정보] 인텔 팬리스 PC를 위한 Core M 프로세서
[분석정보] 전면 개량이 아닌 부분 개량에 머문 Penryn
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [정보분석] Penryn의 1.5배 CPU 코어를 가지는 차세대 CPU "Nehalem" (0) | 2007.09.27 |
|---|---|
| [분석정보] AMD가 2009년의 CPU 코어와 통합 CPU의 개요를 발표 (0) | 2007.07.27 |
| [분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA (0) | 2007.06.18 |
| [분석정보] 인텔이 추진하는 32코어 CPU Larrabee (0) | 2007.06.11 |
| [분석정보] 크게 다른 Radeon HD 2000과 GeForce 8000의 아키텍처 (0) | 2007.05.18 |
| [분석정보] NVIDIA, Radeon HD 2000의 사양에 이의 (0) | 2007.05.15 |
| [분석정보] 임베디드 시장에 IA 침투를 목표로 하는 Intel (0) | 2007.05.07 |
| [분석정보] 초저소비 전력을 달성한 Silverthorne의 비밀 (0) | 2007.04.26 |