다이에 62 개의 CPU 코어를 탑재한 진정한 매니 코어 CPU
Intel이 "Xeon Phi 5110P"의 브랜드로 투입한 "Knights Corner (나이츠코너)"는 22nm 공정에서 물리적으로 62 개의 CPU 코어를 탑재하는 매니 코어 프로세서이다. 1 칩으로 단정밀도(32비트)부동 소수점 연산이라면 2TFLOPS 이상 배정밀도(64비트) 1TFLOPS 이상의 성능을 달성한다. 칩당 성능은 하이 엔드 GPU 수준이면서 CPU 형의 명령어 세트를 갖춘 하이브리드 프로세서인 점이 특징이다. 아키텍쳐적으로 시장출시를 취소한 그래픽 전용 제품 "Larrabee (라라비)"를 계승한 "MIC (Many Integrated Core)" 아키텍처다.
Intel은 몬스터 프로세서를 HPC (High Performance Computing) 시장에 투입한다. HPC 시장에서 슈퍼 컴퓨터의 실적을 쌓아 가고 있는 NVIDIA의 "Kepler"GPU와 IBM의 매니 코어 프로세서 "BlueGene / Q", 게다가 일본 후지쯔의 "SPARC64 VIIIfx"에 도전한다. GPU와 전용 아키텍처가 석권한 시장을 Intel 프로세서로 하는 것이 목표다.

나이츠 코너 다이 사진
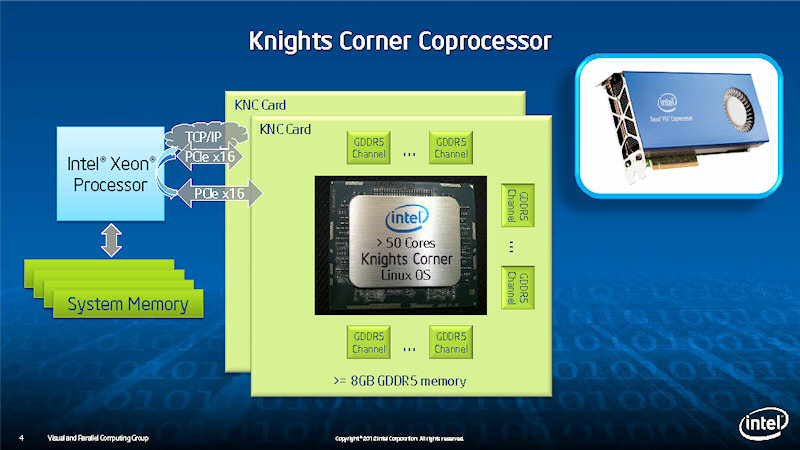
나이츠 코너는 코프로세서(보조연산기)로 동작
현재 미국 솔트 레이크 시티에서 개최 된 슈퍼 컴퓨팅 컨퍼런스 'SC12'에 맞춰 슈퍼 컴퓨터 톱 500 목록이 발표되었다. 목록 1위는 NVIDIA의 K20x의 "Titan"(ORNL : Oak Ridge National Laboratory). 2위는 IBM의 BlueGene / Q의 "Sequoia"(LLNL : Lawrence Livermore National Laboratory), 3위는 일본 후지쯔 SPARC64 VIIIfx의 "K 컴퓨터"(이화학 연구소). Intel의 Xeon Phi는 "Stampede" (Texas Advanced Computing Center / Univ. of Texas)로 7위 (Intel CPU 시스템으로는 SuperMUC가 6 위)



제온 파이로 구성한 첫번째 슈퍼 컴퓨터 시스템 "Stampede 스템피드"
하지만 실제로는 Stampede 점수는 풀 가동 이전 40% 정도의 시스템에서 수치다. 그렇다고 해도, 이번 턴은 미국의 슈퍼 컴퓨터의 정점인 ORNL과 LLNL 등 미국 최고의 연구 시설은 Intel의 손에서 흘러 버린 것도 사실이다. ORNL은 Larrabee시는 Intel을 검토하고 있다고 소문이 있었지만, NVIDIA에 갔다.
Intel은 다음 턴에서 ORNL과 LLNL 등 슈퍼 컴퓨터를 상징하는 탑 연구소를 자사 아키텍처에 통합할 목적이다. 당면 목표는 ExaFLOPS 슈퍼 컴퓨터를 재빨리 실현, 엑사 레이스의 승자가 되는 것이다.
Intel은 HPC의 성장이 데이터 센터의 성장을 견인하고 있다고 보고 있으며, HPC 시장을 중시하고 있다. 또한 Intel은 빅 데이터 분석의 필요성이 높아지는 것으로, 매니 코어의 수요가 향후 높아질 수도 있다고 예측한다. 매니 코어 프로세서와 같은 높은 병렬 프로세서가 제한된 현재 HPC 시장뿐만 아니라 더 넓은 시장에서 사용되어 간다는 것이 Intel의 비전이다. 보통 데이터 센터에, 매니 코어의 Xeon Phi가 들어가게 되면 매출도 커지고 프로세서 개발비도 상각하기 쉬워진다.
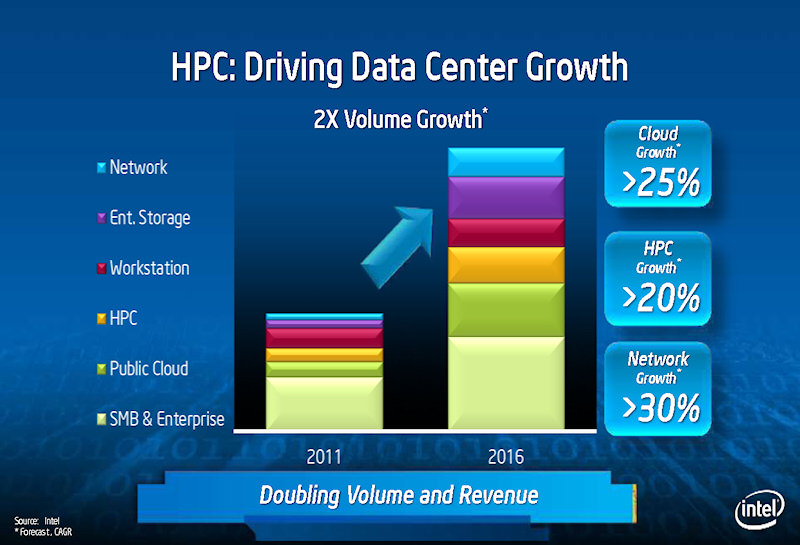
HPC 데이터 센터의 성장을 지원

HPC 업게에서 제온 E5가 널리 채택

엑사 스케일 시대

나이츠코너 제품 브랜드는 Xeon Phi
2 계통의 Xeon Phi 제품군은 메모리와 TDP로 차별화
Intel이 출시한 Xeon Phi 제품은 5100 계와 3100 계의 2 제품군. 모두 22nm 공정으로 동일한 다이(반도체 본체)에서 파생시키고있다. 모두 PCI Express 카드의 형태로 데이터 센터를 위한 패시브 냉각 카드와 팬이 있는 액티브 냉각 카드 2가지 형태가 있다. 데이터 센터에서는 랙 단위로 냉각하기 때문에 일반적으로 칩에 냉각 팬이 없다.
상위 Xeon Phi 5100 계는 패시브만, 현재는 "Xeon Phi 5110P"의 1 모델. Xeon Phi 5110P는 현재 특정 고객에게 출하되고 있으며, 내년 (2013 년) 1월 28일 부터 일반에 발매된다. 카드 가격은 2,649 달러.

첫번째 제품은 제온 파이 3100과 5110P (P 패시브)

제온 파이 5110P의 배정밀도 성능이 1,010 GFLOPS
Xeon Phi 5110P는 62코어 중 60코어가 활성화 되어 있으며 동작 클럭은 1.053GHz. 각 코어가 512-bit 폭의 FMA 벡터 유닛을 갖추고, 배정밀도로 1,011 GFLOPS, 단정밀도 라면 그 2배의 성능을 발휘한다. 각 코어가 4 스레드의 SMT (Simultaneous Multithreading)에 대응해 전체 칩은 240 스레드가 구동된다.
60 코어 각각 512KB 씩 L2가 제공하는 칩 전체의 L2 캐시의 양은 30MB에 달한다. 메모리 인터페이스는 512-bit의 GDDR5에서 5Gtps로 전송 피크 메모리 대역은 320GB/sec. GPU로 최고급 메모리 대역폭이다. 메모리 인터페이스는 32-bit 단위로 동작하고, 메모리 액세스 범위를 억제하고 있다. 카드의 메모리 8GB. TDP (Thermal Design Power : 열 설계 전력)는 카드 225W.

제온 파이 3100은 배정밀도 1,000 GFLOPS 이상
염가판인 Xeon Phi 3100 시리즈는 2013년 상반기에 출시될 전망. 이것은 62코어 중 57코어가 활성화 되어 있다. 즉 5개의 코어가 비활성화 되어 있다. Xeon Phi 3100은 데이터 센터의 수동 냉각 버전이 아닌 능동 냉각 버전도 준비된다. 현재 동작 클럭은 1.1GHz에서 배정 밀도로 1,003 GFLOPS의 전망이다.
L2 캐시의 양은 전체 칩은 28.5MB. 메모리 인터페이스는 384-bit에서 전송 속도는 5Gtps에 메모리는 6GB. 피크 메모리 대역은 240GB/sec가 된다. TDP는 300W.
Xeon Phi는 5100도 3100도 모두 호스트 버스는 PCI Express Gen2. 이것은 칩 설계에 들어간 단계에서 PCI Express Gen3 규격이 확정되지 않았기 때문이라고 한다. 그러나, PCI Express Gen2 이지만 전송속도는 가속화되고 있어, 호스트 버스 대역폭으로 PCI Express Gen3에 가깝다.
시판하는 2계열의 버전 외에, Intel은 스페셜 에디션도 제공하고 있다. 현재 밝혀진 것은 벤치마크 및 Texas Advanced Computing Center (TACC)의 Stampede를 위해 제공하는 SE10라는 시리즈. 이것은 61코어를 활성화 하고, 1.1GHz 동작, 352GB/sec의 메모리 대역폭, TDP 300W의 카드다.
Xeon Phi 5100계와 3100계를 비교하면 명확한 것은 피크 성능으로 차별화 하는 것이 아니라, 메모리 대역폭과 TDP로 차별화를 꾀하고 있는 점. 5110P와 3120A는 모두 1,000 GFLOPS 이상의 성능이지만, 5100계는 메모리 인터페이스가 넓고, TDP가 75%로 낮다. HPC에서 가치가 있는 것은 실제 응용 프로그램의 성능에 미치는 영향이 큰 메모리와 서버 센터의 운영 비용에 큰 영향인 전력이기 때문이다.

Stampede의 스페셜 에디션 제온파이 카드


제온 파이 각 제품
그래픽 유닛이 남은 Knights Corner 다이
Knights Corner와 이전 세대의 Knights Ferry의 다이 (반도체 본체)는 아래 그림과 같다.
Knights Corner 다이의 비율은 정확하지 않다. Intel이 공개한 다이 사진으로 정확한 비율을 판별하는 것이 어렵기 때문이다. 또한 Knights Corner와 Knights Ferry의 다이 크기의 비율도 정확한 것은 아니다. 현상태에서 알수 있는 것은, CPU 코어의 수와 배치 등이다.

Knights Corner와 Knights Ferry의 CPU 코어는 기본적으로 같은 계열의 마이크로 아키텍처이다. 그러나, Knights Ferry는 45nm 공정이며 Knights Corner는 22nm, 공정 세대적으로 2세대 차이가 있다. 또한 캐시 메모리의 양에 차이가 있다. Knights Ferry의 CPU 코어는 256KB의 전용 L2 캐시를 갖추고 있지만, Knights Corner는 2배 512KB의 L2를 갖추고있다. 캐시 양의 차이도 있고, Knights Corner 의 CPU 코어에서 홈 레이아웃이다.
Knights Corner는 다이에 총 62개의 CPU 코어가 배치되어 있는 것을 알수 있다. 4단계 구성으로, 그림의 상단에서 3단까지 각각 16코어씩, 더 하단에 14코어의 총 62코어다. 반면 Knights Ferry 의 CPU 코어수는 32코어 약 절반이다. Knights Corner와 Knights Ferry의 모두 양품으로 사용되는 CPU 코어 수가 물리적 코어 수보다 적은 것은, 수율 향상을 위해 중복을 갖기 때문이다. 여러 CPU 코어에 결함으로 제대로 작동하지 않는 CPU 코어가 있어도 그 코어를 비활성화 하여 제품으로 출하 할수 있다.
Knights Ferry는 원래는 그래픽용 Larrabee 2로 계획된 다이를 전용해 HPC(High Performance Computing)을 위한 것. 따라서 그래픽 전용 유닛이나 텍스처 필터링이 탑재 되어있다. "하드웨어는 Larrabee 이지만 소프트웨어 계층을 HPC 용으로 한 것이 Knights Ferry이다. 그래픽 전용의 기능은 다이에 실려 있지만 사용하지 않는다"라고 Intel은 설명한다. 실제로 Knights Ferry의 다이는, CPU 코어 단위 사이에 텍스처 필터링 유닛으로 보이는 유닛이 배치되어 있다.
흥미롭게도, Knights Corner에서도 CPU 코어 사이에 정체 불명의 유닛이 8 개 정도 배치되어 있다. Intel의 링 버스는 L2 캐시에 연결되어있을 것이므로, CPU 코어에 끼워진 장치도 링 버스에 연결되어 있는 것이다. 위치를 보면 I / O 계 유닛이 아닌 텍스쳐 유닛의 수로 많다. Intel은 "Knights Corner는 그래픽 전용 유닛은 싣고 있지 않다"라고 설명하고 있지만, 실제로 설치되어 비활성화 되어 있는 것으로 보인다. Knights Corner에도 여전히 텍스처 유닛이 탑재되어 있다고 하면, Intel은 MIC 아키텍처의 그래픽시장에 투입 가능성을 아직 버리지 않게된다.
복잡한 고리 구조를 은폐한 내부 구조
Knights Corner의 62개의 CPU 코어와 각 I / O 장치는 링 버스로 연결되어 있다. 링 버스에 CPU 코어와 L2 캐시 쌍과 GDDR5 메모리 컨트롤러, PCI Express 버스가 연결되어 있다.링은 양방향 단방향 독립된 3가지 형태가 있다.
가장 큰 링은 "BL"이라고 하고 있다. BL은 64 byte (512-bit) 폭 Knights Corner 벡터폭과 일치하고 있다. 두 번째 링은 "AD"로 이름 그대로 메모리 액세스 주소의 송수신에 사용된다. 세 번째 링은 "AK"로 일관된 메시지등을 주고받는데 사용된다.

나이츠코너 블록 다이어그램
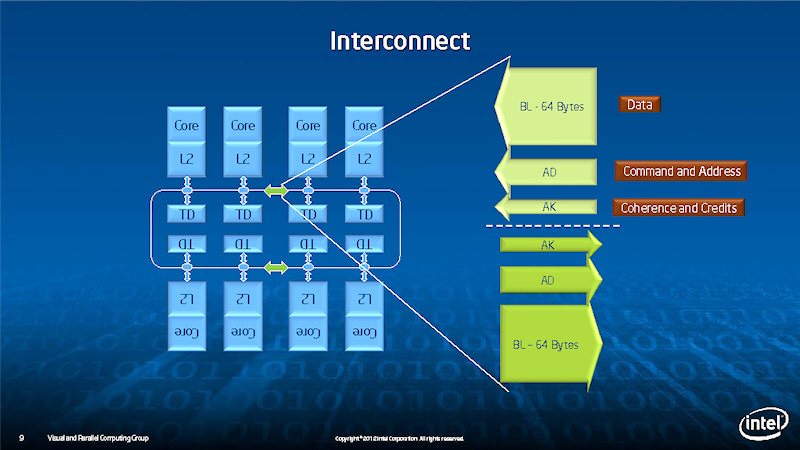
링 버스 구조
링버스 구조
하지만 실제로는 링 1쌍 양방향 링에서 62개의 코어를 모두 연결하고 있는 것은 아니다. "소프트웨어 측면에서 보면, 링은 하나다. 하지만 물리적으로 여러개의 연결로 구성되어 복잡하다. 자세한 내용은 말할 수 없지만, 링의 구성은 최적화되어 있으며, 트래픽을 효율적으로 제어하고 있다. 또한 지연 시간은 (메모리 에서 캐시) 프리 페치 플레잉에서 은폐하고 있다 "라고 Intel은 설명한다. 덧붙여서, Intel은 Larrabee 아키텍처 발표 때 향후 확장으로 아래와 같은 복잡한 고리 구조를 발표했었다.
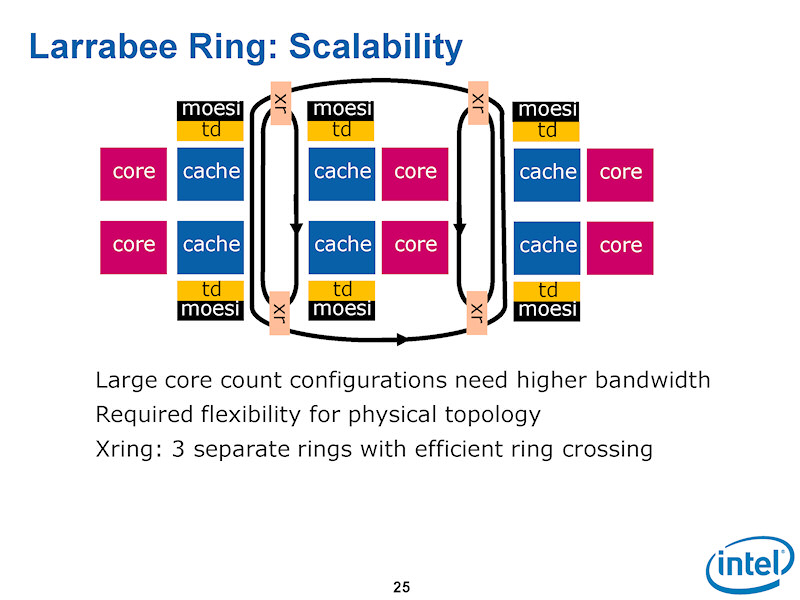
라라비 링 구조
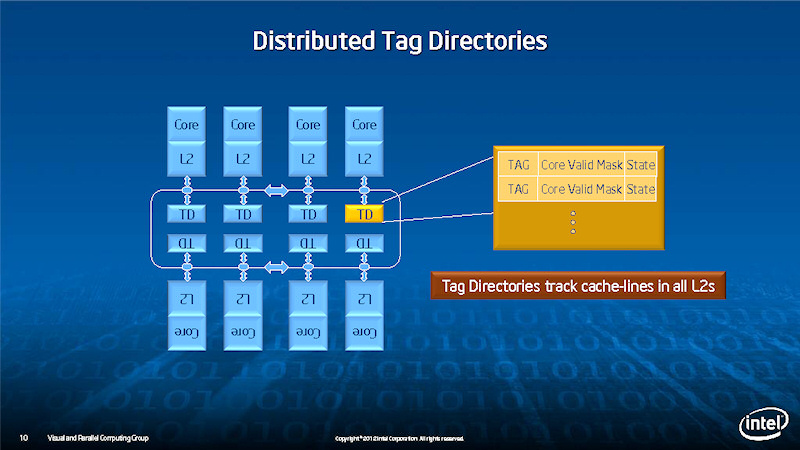
TD는 L2 캐시의 태그 디렉토리에서 각 코어마다 갖추고 있다. 어떤 주소의 메모리 내용이 어떤 L2에 캐시되어 있는지를 추적하고 있다.
Knights Corner의 CPU 코어 마이크로 아키텍처는 Larrabee를 거의 그대로 답습하고 있다. 개별 CPU 코어는 2명령 디코드 & 이슈의 인오더 실행 코어 512-bit 폭의 SIMD (Single Instruction Stream, Multiple Data Stream) 유닛을 더한 구조. CPU코어 자체는 최소된 Intel 그래픽 및 HPC 용 매니 코어는 Larrabee를 답습하고 있다.
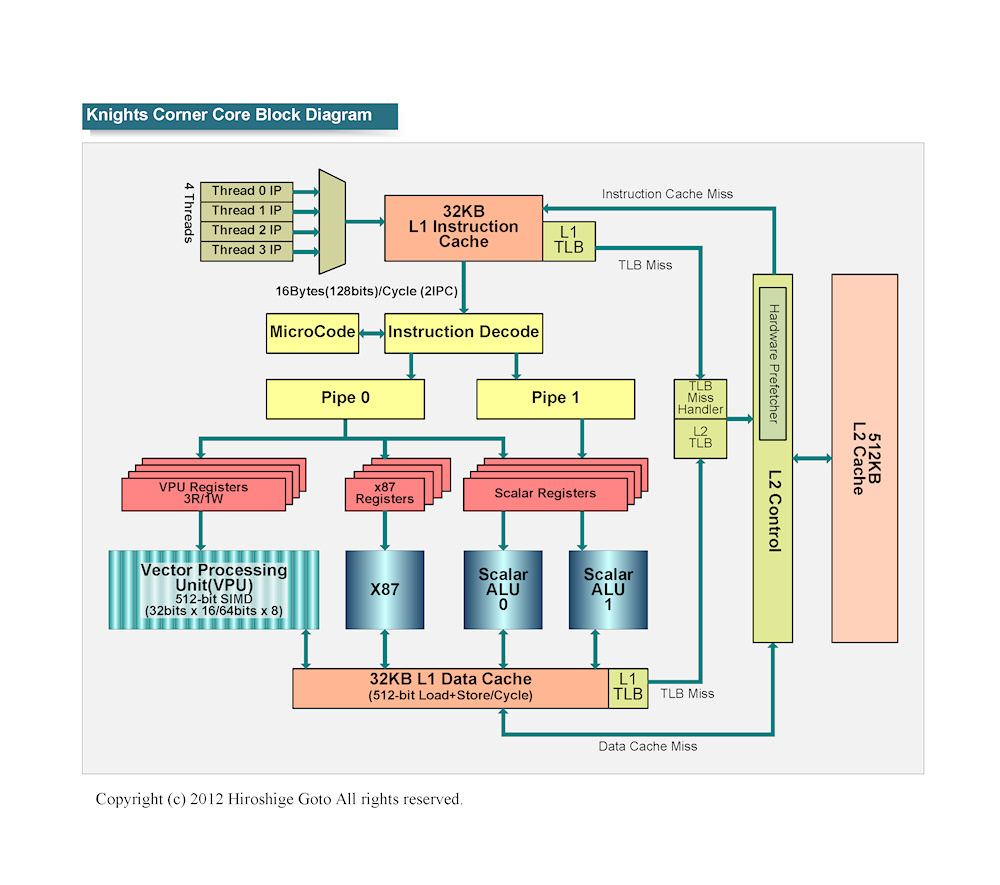
나이츠 코너의 블록 다이어그램
프로세서 파이프 라인은 매우 얕고, 정수 연산 7단계. PC용 CPU 코어와 비교하면 절반 이하로 그만큼 동작 주파수의 상한은 낮다. Knights Corner는 1GHz를 약간 넘는 정도의 주파수에서 작동하는 것을 목표로 하고 있다. 매니 코어를 통해 성능을 향상하면서 주파수는 낮춰 전력소비를 억제하고 있다.

나이츠 코너의 파이프 라인
벡터 유닛은 512-bit 길이, 단정밀도와 배정밀도를 모두 지원한다. 단정밀도의 경우 16-way, 배정밀도는 8-way된다. VPU 레지스터는 512-bit 길이의 FMA로 3피연산자 1연산이 가능하다.Knights Corner는 마스크 레지스터를 갖추고 있어 마스크는 벡터 제어 흐름의 제어가 있다. 예를들어 16-way의 벡터의 각 레인의 스트림이 조건 적으로 각각 다른 경로로 분기하면 마스크 레지스터에서 각 레인의 분기를 판별, 각 레인이 다른 경로만 실행하도록 제어하는 . 외관상 벡터의 각 레인이 개별적으로 조건 분기하는 것으로 보인다. 마스크 레지스터는 분산 / 수집 로드 / 스토어에도 사용된다.
Knights Corner의 코어는 32KB 씩 L1 데이터 캐시와 512KB의 개인 L2 캐시를 갖추고 있다.Larrabee 인채 였던 Knights Ferry와 비교하면, L2가 두배로 실제 메모리 주소를 캐시하는"Translation Lookaside Buffer (TLB)"이 64 항목 설치되고 데이터를 예측하는 하드웨어 프리페처(HWP)도 추가되었다.
GPU와의 가장 큰 차이점은 스칼라 유닛을 갖추고 있어, x86 명령을 실행가능. 또한 현재의 GPU는 일반적으로 Single Program, Multiple Data (SPMD) 모델에서 벡터를 프로그램에 노출시키지 않는다. 그러나, MIC 아키텍처는 벡터는 비져블이다. 또한 GPU는 스레드 스케줄링은 하드웨어 제어하지만, Intel은 이것도 제어 할 수있다.
성능 효율 Linpack에서 노드 단독으로 75 %

Intel은 단일 노드에서의 성능을, Xeon 및 Xeon Phi에서 비교한 결과도 공표했다. 동렬의 소비 전력비교, Xeon 측은 Xeon E5-2670을 2 소켓 구성, Xeon Phi 측은 Xeon Phi SE10P 단일 구성 (Xeon Phi가 연결되는 Xeon 성능 제외)의 성능 비교와 되고있다. 실제로 Xeon Phi 카드는 Xeon에 연결되어 있지만, Xeon Phi 자체의 성능을 비교하고 있다.
HPC(High Performance Computing)에서 표준 벤치 마크인 SMP Linpack에서는 단일 노드에서 803GFLOPS. Xeon Phi SE10P은 판매해서는 스페셜 에디션으로, 61 코어가 활성화 배정 밀도의 피크성능은 1,073 GFLOPS. 따라서 스펙상의 피크 성능에 대한 비율은 약 75%의 성능 효율이다.
Linpack에서 75%의 성능 효율은 GPU에 비해 높은 것처럼 보일지 모르지만, 이것은 단일 노드에서의 성능이다. Knights Corner도 전체 시스템은 성능 효율은 60% 대 중반에 정착한다. TACC의 Stampede는 전체 67%로 되어있다. 단일 노드에서 75% 정도, 시스템에서 65%를 넘는다는 Linpack의 성능 효율은 일반적인 하이엔드 GPU HPC 시스템과 거의 동렬 또는 약간 높은 정도. Knights Corner의 Linpack에서의 효율은 간단히 말해 GPU 수준이라는 것이된다.
벡터 유닛을 묶은 Knights Corner는 비교적 간단한 행렬 연산 SGEMM / DGEMM에서는 보다 성능효율이 높아진다. 그러나 여전히 80% 대에 피크 성능은 높지만, 성능 효율은 CPU 정도로 높지않다. 이러한 Knights Corner의 성능 특성은 GPU로 말할 수 있을 듯하다.
덧붙여서,이 벤치 마크는 ECC를 선택한 결과이지만, STREAM Triad의 메모리 사용량 벤치 마크에서 ECC 온, ECC 오프를 모두 게재하고 있다. Knights 제품군은 GDDR5 메모리로 사용하고 있지만, 메모리 인터페이스에 ECC를 통합하고 있다. 벤치 마크의 ECC에 의한 성능 차이를 보면, 메모리 대역에 미치는 ECC의 영향은 4% 이하로 매우 작은 것을 알 수있다. "놀라운 낮은 패널티에서 ECC를 구현하는 데 성공하여 안정적인 메모리 데이터 액세스를 실현했다"라고 Intel의 Joe Curley 씨는 설명한다.
병렬 프로세서의 성능 향상은 2.x 배 정도
성능 비교에서 눈에 띄는 것은 Xeon 대한 성능 향상이 2.x 배 비교적 소폭이다. GPU 벤더들이 좋아하는, CPU에 10배나 100배의 업 이라는 비교 차트와는 크게 다르다. 이 내용은 Intel의 James Reinders 씨 (Director, Parallel Programming Evangelist, Intel Corporation)가 간단한 예로 설명을 했다.
Reinders 씨는 간단한 행렬 연산 SAXPY (Single-precision real Alpha X Plus Y)를 FORTRAN 코드 비교. 먼저 일반적인 컴파일로 달리게 하면 처리 시간이 67 초 (Xeon E5-2600 6 코어)이 되는 것으로 나타났다.


다음 Reinders 씨는 병렬화 지시어를 추가하여 컴파일된 코드를 생성. 그것을 Xeon Phi으로 실행한 결과가 0.197 초로 나타났다. 이것만 보면 CPU에 Xeon Phi의 속도는 약 340 배가된다. Reinders 씨는 지금은 병렬 프로그램을 병렬 프로세서에서 달리게 한 결과와 시리얼 프로그램을 CPU에서 실행시킨 결과와 비교 한 것이라고 지적했다. CPU도 병렬화 할 수 있으므로 공정하지 않다고 설명했다.
즉, GPU 메이커의 비교 수치는 CPU 측을 낮게 추정하고 있다고 비판하고 있다.



그 뒤에 Reinders 씨는 같은 병렬화 지시어를 추가하여 컴파일 된 코드를 Xeon에서 달리게 했다. 그 결과를 Xeon Phi과 비교하면 2.3 배의 성능 향상 밖에되지 않는다고 Reinders 씨는 지적. Xeon Phi 같은 높은 병렬 프로세서의 성능 향상은 실제로 2.x 배가 된다고 설명했다. (이게 더 맞는 거겠죠. CPU에도 최적화한 코드랑 GPU랑 비교해야지 맞지, 그렇지 않게 해놓고 GPU랑 비교해서 GPU가 100배 속도라고 말하면 속임수죠. 실제 이런 100배 차이라면, GPU를 쓰지 않고 순수 CPU만으로 구성된 슈퍼컴퓨터는 순위에도 없거나, 있어도 엄청난 격차가 있어야 하지만 그렇지 않죠.)
또한 Reinders 씨는 Intel Xeon Phi는 2.x 배의 성능 향상을 지시문을 더하는 것만으로 얻을 수 있기 때문에 핸드 코딩 최적화가 필요하지 않아 프로그래밍 효율이 높다고 설명했다. Intel은 이 연구논문도 발표하고, GPU의 극적인 성능 향상은 허구라고 반박하고있다. 또한 Intel은 Xeon Phi의 장점은 단독으로 스칼라 코드와 벡터 코드를 모두 실행할 수있는 것을 강조하고 있다.



이 부분은 MIC 아키텍처 대 GPU 아키텍처에서 가장 논쟁이있는 곳에, 현재 Intel과 NVIDIA가 설전을 벌이고 있다. 모두 어느 정도 자신에게 적당한 유도하고있다. 그러나 일정한 범위의 벡터에 의한 병렬 프로세서화를 도입하지 않으면 성능 / 전력 향상을 바랄 수 없다는 점에서 일치하고 있다.
Xeon Phi의 Stampede는 아직 풀 가동 전
현재는 (슈퍼컴)500 위에서, NVIDIA, IBM, 후지쯔, Intel은 아래이다. Intel은 앞으로 실증 해 나갈 필요가 있다. 첫번째 Xeon Phi를 채용한 Stampede는 Linpack 2.66PFLOPS로
최고의 ORNL Cray / NVIDIA Titan은 17.59PFLOPS. Intel은 여전히 뒤져있다.
(전체 시스템의 CPU점유율은 인텔이 압도적 입니다. 이건 슈퍼컴퓨터 기사를 참고)
당연하게 Stampede는 아직 풀 가동 상태가 아닌 것으로, 2013년 1월 완공 예정의 초기 시스템으로 피크 성능은 거의 10PFLOPS 가까이에 이른다고 한다. 이른바 10 페타 수준이다. 완성 시점에서 총 6,400개의 Xeon E5 듀얼 소켓 노드 (12,800 개의 CPU)와
6,400 개의 Xeon Phi 카드로 구성될 예정이다.
피크 성능으로 2PFLOPS 이상을 Xeon이 7PFLOPS 이상을 Xeon Phi가 담당한다. 계산 상으로는 Xeon Phi 성능이 부족한 것이지만, 그래도 9PFLOPS에 도달할 것이다.
완성하면 총 182 랙에서 6MW의 전력 시스템이다.
현재 (슈퍼컴)500 에서 Stampede는 총 204,900 코어에서 피크가 3,959 TFLOPS이다. 역산하면 2소켓의 Xeon과 1 Xeon Phi 노드가 약 2,600 개라고 계산된다. 즉, 아직 풀 가동의 절반 이하의 구성의 벤치마크 결과에서 7위의 점수에 도달하게 된다. 풀 가동하면 후지쯔 K컴퓨터 에는 미치지 못 하지만, Linpack 6PFLOPS 클래스에 도달 할 것 같다.
HPC에서의 싸움은 Intel에게 아직 초기 단계임을 알 수있다. MIC 아키텍처의 진가를 시험받는 것은 앞으로다.
![]() xeon-phi-software-developers-guide.pdf
xeon-phi-software-developers-guide.pdf
(2012년 가이드)
![]() xeon-phi-software-developers-guide (1).pdf
xeon-phi-software-developers-guide (1).pdf
(2013년 가이드)
이외에 더 자세한 내용이나 수많은 관련 문서들은 http://software.intel.com/mic-developer 에서 확인하시기 바랍니다.
[분석정보] TOP500 슈퍼컴퓨터 순위 2013년 11월
[분석정보] 매니코어 프로세서로 손바닥 슈퍼 컴퓨터를 실현
[분석정보] 4만 8000개의 제온파이로 중국 톈허2 세계에서 가장 빠른 슈퍼 컴퓨터
[분석정보] TOP500 슈퍼컴퓨터 순위 2013년 6월
[제품뉴스] Intel Xeon Phi 새로운 폼 팩터 채용 포함 5모델 추가
[정보분석] 인텔 60코어 매니코어 "Xeon Phi" 정식발표
[분석정보] 인텔 슈퍼컴퓨터용 가속기 Xeon Phi 5110P 발표
[분석정보] Intel, HPC 전용 보조 프로세서 Xeon Phi 2013년 1월부터 일반용으로 출시
[분석정보] IDF 2012에서 주목한 한가지, 매니 코어 "Knights Corner"
[정보분석] 엔비디아 세계 최다 트렌지스터 칩 GK 110 공개
[정보분석] IDF 2011 Justin Rattner 기조연설 매니코어 시대가 다가옴 1/2부
[정보분석] IDF 2011 Justin Rattner 기조연설 매니코어 시대가 다가옴 2/2부
[정보분석] 같은 무렵에 시작된 Nehalem과 Larrabee와 Atom
[분석정보] Intel은 Larrabee 계획과 아키텍처를 어떻게 바꾸나?
[분석정보] 다시 처음부터 시작된 라라비 무엇이 문제였나?
[분석정보] 라라비 (Larrabee)의 비장의 카드 공유 가상 메모리
[분석정보] 인텔의 스칼라 CPU + 라라비의 이기종 CPU 비전
[분석정보] Larrabee는 SIMD와 MIMD의 균형 - Intel CTO가 말한다.
[정보분석](암달의 법칙) 2010년대 100 코어 CPU 시대를 향해서 달리는 CPU 제조사
[분석정보] 인텔 GDC에서 라라비 명령 세트의 개요를 공개
[분석정보] GDC 2009 드디어 소프트 개발자 정보도 나온 "Larrabee"
[정보분석] Intel 힐스보로가 개발하는 CPU 아키텍처의 방향성
[분석정보] SSE와는 근본적으로 다른 Larrabee의 벡터 프로세서
[정보분석] 팀스위니 미래의 게임 개발 기술. 소프트웨어 렌더링으로 회귀
[분석정보] 정식 발표된 라라비(Larrabee) 아키텍처
[아키텍처] 베일을 벗은 인텔 CPU & GPU 하이브리드 라라비(Larrabee)
[정보분석] 암달의 법칙(Amdahl's law)을 둘러싼 Intel과 AMD의 싸움
[정보분석] 모든 CPU는 멀티 스레드로, 명확하게 된 CPU의 방향
[벤치리뷰] 인텔 제온 파이 5110P와 엔비디아 테슬라 K20 행렬 곱 실효 성능 비교
[벤치리뷰] N형 문제 프로그램의 인텔 제온 파이 이식 평가
[분석정보] Many-Core CPU로 향하는 Intel. CTO Gelsinger 인터뷰 1/2부
[분석정보] 5W 이하의 저전력 프로세서의 개발로 향하는 Intel
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [정보분석] Hasell(하스웰) 최강의 무기 통합 전압 조절기 (0) | 2013.01.04 |
|---|---|
| [분석정보] 아이테니엄(Itanium)을 둘러싼 불안과 기대 (0) | 2012.11.30 |
| [정보분석] 아웃 오브 오더 및 최신 프로세스를 채택하는 향후의 Atom (0) | 2012.11.30 |
| [분석정보] Steamroller (스팀롤러) 가 사라진 AMD 로드맵의 변화와 차세대 게임기의 행방 (0) | 2012.11.21 |
| [분석정보] 2013년에 출시되는 Intel의 새로운 서버용 프로세서 (0) | 2012.11.15 |
| [분석정보] 인텔 슈퍼컴퓨터용 가속기 Xeon Phi 5110P 발표 (0) | 2012.11.13 |
| [분석정보] Intel, HPC 전용 보조 프로세서 Xeon Phi 2013년 1월부터 일반용으로 출시 (0) | 2012.11.13 |
| [분석정보] Windows 8로 떠오르는 Intel 태블릿 SoC 클로버 트레일의 배경 (0) | 2012.10.31 |