아키텍처를 쇄신한 Nehalem
Intel이 내년 (2008 년) 후반에 투입하는 차기 CPU 마이크로 아키텍쳐 "Nehalem (네할렘)" 이번 IDF에서는 마이크로 아키텍처의 자세한 내용은 거의 공개되지 않았다. 그러나 몇 가지 팁이 주어졌다.

Stphen L. Smith
Intel의 Stephen L. Smith 씨 (Vice President, Director, Digital Enterprise Group Operations, Intel)는 브리핑에서 다음과 같이 말했다.
"Nehalem는 4 이슈 (명령 발행) 머신으로 Core 2의 4 와이드 (= 이슈) 머신 상에 구축된다. 그러나 근본적으로 다르며, 보다 고성능이 된다."
Intel은 Core 2 계의 Core Microarchitecture (Core MA)에서 명령 발행의 폭을 4 이슈로 확장했다. Core MA 이전 Intel CPU는 모두 3 이슈 마이크로 아키텍처였다. Nehalem은 Core MA의 4 이슈 아키텍처를 계승한다.
Patrick(Pat) P. Gelsinger
그러면 Nehalem의 CPU 코어는 Core MA를 기반으로 약간의 확장을 더했을 뿐인 것일까? 그것에 대해 Nehalem의 설계팀을 Digital Enterprise Group을 이끄는 Patrick (Pat) P. Gelsinger 씨 (Senior Vice President and General Manager, Digital Enterprise Group)는 다음과 같이 말한다.
"마이크로 아키텍처 확장에 대한 자세한 내용은 아직 공개 할 수 없다. 공개 할 수 없는 이유의 하나는 (경쟁사와의) 경쟁으로, 또 아직 중간 지점으로 Penryn조차 제품 발표하지 않기 때문이다. Nehalem에 대해서는, 다음 IDF에서 많은 것을 공개한다. 다만 Nehalem에 큰 확장이 더해진 것 만은 말할 수 있다. 왜냐하면 Nehalem은 틱톡 모델의 톡에 있으며, 완전히 새로운 마이크로 아키텍처이기 때문이다.
내부 마이크로 아키텍처는 물론 변경했다. 메모리 계층도 바꿨다. 중요한 새로운 명령 실행 기능도 머신에 더했다. 아키텍처의 파이프 라이닝도 재편성 했다. 또한 공표한 대로 네이티브 쿼드코어 설계로, 옥타코어 설계판도 앞두고 있다. CPU 내부의 비 코어 부분에서는 온칩 네트워크를 크게 바꾸었다. 물론 메모리 컨트롤러와 QuickPath Interconnect (QPI)의 내장도 새롭다. 모두가 완전히 새로운 설계다.
Nehalem에는 많은 훌륭한 기능이 탑재되어있다. 아직 말할 수 없지만, 좋은 아키텍처임을 믿어 달라 "
Nehalem의 구성
Nehalem의 기본 구성

DP판 Nehalem의 구성 예
Nehalem의 CPU 코어 사이즈는 Penryn의 1.5 배
실제로, Nehalem과 Penryn의 다이(반도체 본체)를 비교하면, CPU 코어에 큰 차이가 있는 것이 명확히 알 수 있다. 아래 그림은 Nehalem의 다이를 약 270 제곱 mm로 추정, Penryn의 다이와 거의 같게 축척하여 비교한 것이다. 보이는 대로, Nehalem 쪽이 약 2.5 배의 다이 사이즈가 된다. 그리고 그 중 CPU 코어 부분을 비교하면, Nehalem의 CPU 코어는 Penryn의 CPU 코어에 대해 약 1.5 배의 면적이 되는 것을 알 수 있다. 이것은 CPU 코어에 상당히 대폭적인 확장이 더해진 것을 의미한다.
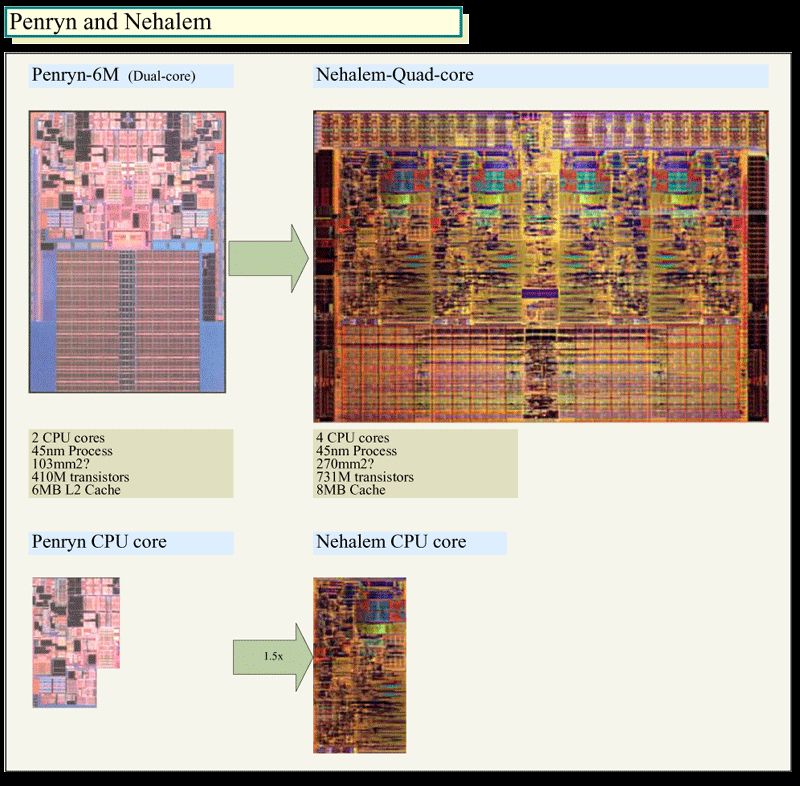
Penryn과 Nehalem의 다이 비교
원래 Core MA의 CPU 코어는 65nm의 Merom (메롬)에서 19M (1,900 만)으로 비교적 컴팩트하게 했다. 단순 계산으로는 Nehalem의 CPU 코어는 30M (3,000만) 정도의 트랜지스터 수가 된다고 추정된다. 간단히 말하면, Intel은 Nehalem에서는 CPU 코어를 작게 멈추어 확장을 억제하고, 그 대신 CPU 코어 수를 늘려서 스레드 병렬성을 높인다는 방책은(이렇게 만든게 불도저로 멈춘정도가 아닌 기존 자사 코어보다 더 작게 만듬) 채택하지 않은 것이다. 스레드 병렬성도 높이지만 (4코어와 하이퍼쓰레딩으로 8스레드 병렬처리), CPU 코어 자체도 강화하는 노선이다.
Intel은 Nehalem에서 마이크로 아키텍쳐를 쇄신하고, 크게 확장해야 하지 않으면 안되는 이유가 있다. Intel의 내부에는 현재 2 개의 CPU 설계팀이 PC & 서버 전용 CPU의 개발에서 경쟁하고 있다. 하나는 오리건주 힐스보로 (Hillsboro)에 있는 개발 팀으로, Digital Enterprise Group에 속하며, Pentium III (P6)와 Pentium 4 (NetBurst) 아키텍처를 개발했다. 또 하나는, 이스라엘에 있는 팀으로 Mobility Group에 속하며, Pentium M (Banias)과 Core Microarchitecture (Core MA)를 개발했다.
원래는 데스크탑 & 서버용 CPU는 오리건에서 개발하고 있었다. 그러나 저전력 코어의 개발 지연 때문에, 모바일 용으로 개발했던 Core MA를 데스크탑 & 서버에도 확장한 경위가 있다. Nehalem은 힐스보로 개발로서는 NetBurst 이후의 마이크로 아키텍쳐 개혁이 된다. 2004년 ~ 2006년에 걸쳐서 계획되어 있던, 힐스보로 개발 NetBurst 확장 "Tejas (테자스, 테하스)"와 오리지날 계획 Nehalem은 취소 되었다. Core MA는 그 대안으로 붙었다.
즉, 형태로는 힐스보로의 넘어짐을, 이스라엘의 아키텍처가 구한 것이 된다. 따라서 어느 Intel 관계자는 "지금은 개발팀으로서 힐스보로와 이스라엘은 동격으로 줄서있다. Gelsinger 씨는 Nehalem으로 힐스보로 개발력을 보여주지 않으면 안되는 입장에 있다"고 말했다.
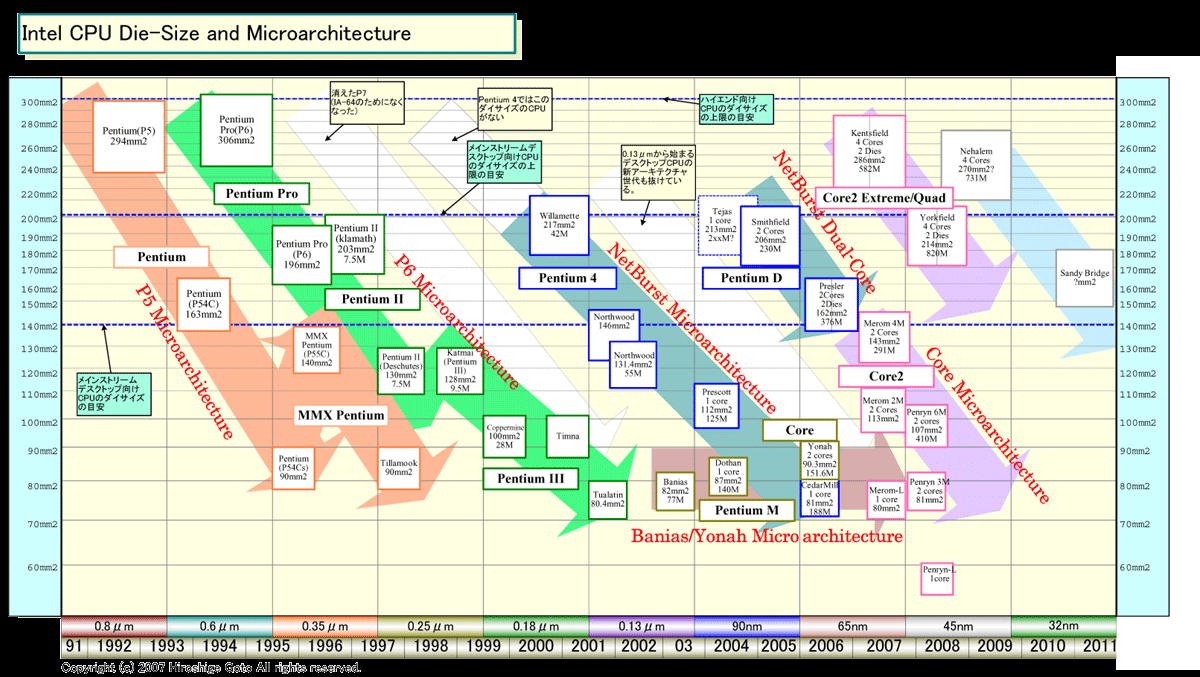
Intel CPU Die-Size and Microarchitecture
NetBurst의 Hyper-Threading에서 발전
힐스보로가 Nehalem에서 새롭게 추가한 신 요소의 하나는 "SMT (Simultaneous Multithreading)" 이다. Nehalem은 Hyper-Threading과 동일한 모양의 SMT 기술을 탑재, 1개의 물리 CPU 코어가 2 스레드를 병렬 실행 가능하다. 논리 스레드 수는 각 CPU 코어 당 2 스레드가 된다. Gelsinger 씨는 Nehalem의 SMT 대해 다음과 같이 설명한다.
"SMT는 매우 우아한 설계다. 워크로드가 스레드화 되어 있으면, 매우 뛰어난 자원 공유가 가능하다. 물론 SMT 구현은 쉽지 않다. AMD가 아직 실현하지 못한 것이 어려움을 증명하고 있다. (인텔 CPU에서의 명칭 하이퍼스레딩 = SMT (동시 멀티스레딩). 아이테니엄 몬테시토의 방식도 하이퍼 스레딩이라고 하지만 SMT는 아니고, 아이테니엄을 일반 사용자가 쓸일도 없기 때문에 하이퍼스레딩 = SMT. 멀티 스레딩은 크게 동시에 실행 하느냐 아니냐의 2가지로 나뉩니다. 동시가 아닌 것에 Coarse-grained 멀티스레딩이냐 Fine-grained 이냐로 또 나뉘구요.)
그러나 일단 구현되면, (2Way의) SMT는 0 에서 최대 30 ~ 40%의 성능 향상을 얻을 수 있다. 경우에 따라서는 향상은 제로일지도 모르지만, 조건이 좋으면 40%가 될지도 모른다. 4 ~ 5% 의 설계 크기의 증가로, 그만큼의 성능 향상을 얻는 것은 좋은 트레이드 오프다" (경우에 따라 제로라는 것은 SMT는 1스레드로는 명령어 병렬화로 파이프 라인을 다 채우지 못해도 2스레드를 동시에 실행하도록 해서 파이프 라인이 쉴틈없이 최대한 효율성을 높여서 성능을 증가시키는 것이지, 없는 성능을 만들어 낸느 것은 아니기 때문 입니다. 즉 CPU의 이론상 성능이 100인데, ILP 만으로는 충분히 각각의 파이프 라인을 항상 지속적으로 채우지 못해서 순간적으로는 100을 쓸수 있을지 몰라도, 실성능이 70~80밖에 나오지 않는다면, 2스레드를 동시에 실행해 최대한 100에 가깝게 성능을 낸다 라는 개념이기 때문 입니다. 피크성능에 가깝게 내는 것이지, 피크 성능을 넘는게 아니라는 거죠.)
몇 %의 구현 비용으로 최대 40%의 성능 이득은 Hyper-Threading 때의 이야기와 공통되어 있다. 이 것에서 Nehalem의 SMT가 NetBurst의 Hyper-Threading과 닮아 있다는 것을 알게 된다. 또 Gelsinger 씨는 올 봄 일본 방문시에 다음과 같이 말했다.
"우리는 Pentium 4의 Hyper-Threading에서 많은 것을 배웠다. 따라서 Nehalem (의 SMT)은 (NetBurst의 SMT 대해) 동등하거나 보다 뛰어난 것이 된다고 생각한다. Nehalem에서는 (NetBurst와 비교해서)보다 짧은 파이프 라인이기 때문에 스레드 간의 전환이 보다 빠르게 된다 "
Nehalem의 SMT가 NetBurst의 Hyper-Threading의 개선인 것이 엿보인다. 후단의 설명은 SMT가 아닌 파이프 라인 스레드 전환의 이야기가 되었지만, 여기에서는 Nehalem이 Core MA 같이 짧은 파이프 라인 구조인 것을 알게 된다.
PC 소프트웨어 환경의 워크로드를 고려한 2way의 SMT
SMT에서는 2 스레드 이상의 병렬화도 가능하다. 그러나, Intel은 Nehalem에서는 2way 이상의 SMT는 구현하지 않는다. Hyper-Threading과 마찬가지로 최대 2 스레드까지 SMT에 그쳤다. 그 이유에 대해서 Gelsinger 씨는 다음과 같이 설명한다.
"3 ~ 4way 하는 경우에는 성능은 (2way)보다 향상되겠지만, 설계의 복잡도는 계속 늘어나 버린다. 3 ~ 4way의 SMT를 단일 CPU 코어의 자원에 더해도, 늘어나는 복잡도에 비해 놀라운 성능 향상은 얻을 수 없다. 2Way SMT는 복잡도와 성능이 좋은 밸런스로, 매우 전력 효율이 좋은 최적의 마이크로 아키텍처다 "
그러나 서버계 CPU에서는 3way 이상의 하드웨어 멀티 스레딩을 구현한 CPU도 등장했다. 예를 들면, Sun Microsystems의 Niagara 2에서는 코어 당 8way의 멀티 스레딩을 지원한다. 그것에 대해서, Gelsinger 씨는 최적화 하는 워크로드에 따라서 최적인 멀티 스레딩의 구현도 다르다고 설명한다.
"Sun이 구현한 것은 SMT가 아닌, 이벤트 스레드를 스위치하는 "Switch-on Event Multi-Threading (SoEMT) "이다. 구현은 크게 다르다. 우리의 SMT는 파이프 라인을 통해서 (두 개의 스레드 사이에서) 완전히 자원을 공유한다. 그것에 비해서, 그들의 구현은 스레드 군을 파이프 라인에 보내, 다른 스레드의 스테이트를 트랙 유지한다. (쉽게 말하면 SMT처럼 CPU 작업 관리자에 1코어가 8개의 논리 프로세서라고 나와도, SMT처럼 8스레드의 명령을 동시에 실행하는게 아니라, 각각의 스레드를 한번씩 실행 하는 것. 각각의 스레드 상태를 갖는 부분이 8개지만, 실제 실행하는 것으로는 1스레드씩 실행. 번갈아 가면서 실행한다고 해도 없는 것 보다는 있는 것이 메모리 레이턴시 등에 의해서 각각의 파이프 라인이 쉬는 것을 방지하고 역시 마찬가지로 각각의 파이프 라인을 바쁘게 해서 최대한 성능을 뽑을 수 있습니다. MT가 안되는 그냥 1코어 CPU로 여러 작업을 동시에 실행하면, 각각의 스레드 전환에 지연시간이 생깁니다. 반면 SMT가 아니라도 MT가 되면 스레드 상태를 가지고 있기 때문에 전환이 빠르구요. 그래픽 카드 같은 경우도 SMT가 아닙니다. SMX가 여러개를 말하면 CPU로 말하면 멀티코어 같은게 되는 것이고, 내부의 SP 들이 몇스레드를 처리한다 라고 나오는 부분이 SMT가 아니닙니다. 각각의 스레드에 따른 레지스터는 갖추고 있기에 스레드 전환을 즉시해서 처리하는 거죠.)
고도로 스레드화 된 워크로드에 대해서는, Niagara의 디자인은 상당히 우아하다. Niagara는 그러한 고스레딩화 (소프트웨어) 환경에 대해서 최적화 한 설계가 이루어져 있다. 한편 스레드화의 정도의 범위가 넓은 다양한 워크로드에 대해서는, 우리의 SMT 쪽이 이점이 있다. 우리는 스레드 정도가 낮은(소프트웨어) 환경과 높은 환경 사이의 균형에 의해 최적화 된 설계를 하고 있다. 예를 들면, Nehalem과 Niagara을 비교한 경우에는, 싱글 스레드 성능에서는 큰 차이가 생길 것이다. 아마 5배 정도의 성능 차이가 있다고 생각한다. (싱글 스레드 라면 네할렘이 5배 정도 빠르다는 말. 네할렘쪽이 훨씬 넓은 슈퍼스칼라이기 코어이기 때문에. 코어의 크기도 크게 될테구요.)
Niagara 자체는 여러면에서 매우 뛰어난 디자인이다. 작은 CPU 코어에 SoEMT 메커니즘을 구현한 극히 병렬도가 높은 어레이로, 그들의 지향하는 워크로드에는 합리적인 성능 트레이드 오프가 얻어진다. 그러나 우리와는 디자인 포인트가 크게 다르다 "
SMT와 비교해서 구현이 쉬운 SoEMT로, 스레드 병렬도를 올린다는 방법도 있다. 그러나 SoEMT는 SMT 처럼 다른 스레드의 명령을 1 사이클에 혼재시켜 (동시에) 실행하는 것으로 CPU 리소스의 활용도를 높이는 것은 할 수 없다. SMT는 스레드 병렬성이 낮은 소프트웨어 환경에서도, 명령 레벨의 병렬성이 높은 (ILP가 높은 = IPC가 높은) CPU 코어의 활용도를 높여 전체 스루풋을 높이는 것이 가능하다. 즉, 모바일을 포함한 클라이언트 PC의 소프트웨어 환경을 생각하면, 2way SMT를 명령 병렬성이 높은 풍부한 CPU 코어에 구현하는 것이 유리하다는 것이 Intel의 판단이다.
64-bit에 최적화가 진행된 Nehalem
SMT는 Nehalem의 새로운 기능이지만, Gelsinger 씨의 설명대로 라고 하면, CPU 코어 설계에 미치는 영향은 4 ~ 5%의 다이의 증가에 머문다. Nehalem CPU 코어의 대형화 이유의 대부분은 SMT 구현에 없는 것은 분명하다.
마이크로 아키텍처 면에서 Nehalem이 Core MA와 명확하게 다른 점 중 하나는 64 bit 모드다. Core MA는 내부의 디자인을 보는 한 ,32-bit 모드를 중심으로 설계를 하고, 64 bit 모드를 덧붙였다는 느낌이 강하다.
특히 프론트 엔드의 명령 페치부터 디코드에 대해서는 ,32-bit에 보다 최적화 되어있어, 64 bit로의 최적화를 위해서는 분명히 확장이 필요하다. 이것은 원래 Core MA가 모바일 용 CPU 마이크로 아키텍처로 개발이 시작된 것과 무관하지 않을 것이다.
반면, Nehalem에서는 데스크탑 & 서버 CPU를 담당해온 Intel의 오레곤 팀이 담당한다. 따라서 64-bit 모드로는 완전한 최적화를 도모 할 것이다.
"(Nehalem에서는) 모두 64-bit이다. 32-bit도 물론 지원하지만, 64 bit에 최적화 되어 있다"(Gelsinger 씨)
이것은 파이프 라인 전체 중에서 프론트 엔드가 크게 개량된 것을 엿보이게 한다. 또한 Gelsinger 씨는 Nehalem에서는 리 파이프 라이닝 했다고 말하고 있어, 파이프 라인 구조가 Core MA와는 다를 가능성이 높다. 또 Nehalem부터 더해진 Application Targeted Accelerator (ATA) 명령의 실행 유닛도, 어느 정도의 다이를 차지할 것이다.
참고로 AMD는 GPU 통합까지 내다본, AMD 버전의 "SSE5" 명령 추가 계획을 밝혔다. AMD는 최종적으로는, GPU 코어 측의 실행 유닛을 SSE5나 그 이후에 추가하는 명령 등을 통해서, CPU 프로그램 위에서 원활하게 사용할 수 있게 한다. AMD의 이러한 SSE 명령어 확장 비전에 대해서 Gelsinger 씨는 다음과 같이 대답한다.
"우리는 SSE4 이후 SSE 명령의 로드맵을 가지고 있다. 그 개요는 내년 공개 할 것이다. AMD가 말하는 SSE5에 우리가 따를 생각은 없다. 지금까지 우리는 SSE4에 명확한 이치를 보여 왔으며, 이에 대한 업계의 대응 자세도 좋다. 반면 AMD는 우리의 SSE4에 완전 호환조차 없다 "

ISA의 혁신은 계속
Core MA 같이 얕은 파이프 라인의 Nehalem
Nehalem은 Core MA와 차별화 되는 한편으로, 강한 공통성도 있다고 추측된다. 우선 앞의 발언에서 알 수 있듯이 Nehalem은 NetBurst 계의 깊은 파이프 라인에 의한 고주파수 설계는 채택하지 않는다. 이것은 소비 전력당 성능에 초점을 맞춘 현재의 Intel CPU에서는 당연한 방향이다. 파이프 라인을 깊게하면, 전력 소비가 큰 래치 회로가 증가해서, 전력 소비가 증가되기 때문이다.

Justin R. Rattner
힐스보로의 이전 마이크로 아키텍처인 NetBurst에서는 x86 명령을 단순한 내부 명령 uOPs (마이크로 오퍼레이션)로 분해했다. 그것에 비해서, Banias 이후 이스라엘계 마이크로 아키텍처는에서는 내부 명령의 입도를 크게 유지한 uOPs 퓨전을 채용하고, Core MA 에서는 또한 x86 명령어끼리 융합시키는 Macro 퓨전을 채택했다.
CISC (Complex Instruction Set Computer) 인 x86의 강점을 어느정도 CPU 내부의 파이프 라인에도 초래한다는 것이, 이스라엘계 마이크로 아키텍쳐의 특징이다. 그리고 그것은, Nehalem에도 적용되는 것으로 보인다.
예를 들어, Intel의 Justin R. Rattner (저스틴 R · 래트너) 씨 (Senior Fellow, Corporate Technology Group / CTO, Intel)는 이전에 아래와 같이 대답했다.
"우리가 전력 효율을 향상시키기 위해 Banias부터 Merom, 한층, 그것 이후(의 CPU 마이크로 아키텍처)에서 계속 진행하고 있는 것은, 보다 uOPs 퓨전을 적용하는 것이다"
uOPs 퓨전을 진화시키는 것은 현재 Intel 마이크로 아키텍처의 기본 노선이라고 생각된다. 따라서 Nehalem에서도, Core MA의 uOPs 퓨전과 Macro 퓨전은 계승되는 것이다.
다만, Macro 퓨전을 Core MA 이상으로 발전시키는 것은, 약간 어려울지도 모른다. Core MA의 Macro 퓨전은 "COMPARE" 와 "CONDITIONAL-JUMP"의 2개의 x86 명령의 연속을 융합시킨다. Intel의 논문에서도, 이것이 가장 uOPs 퓨전에 적합한 조합이라고 지적된다. Macro 퓨전을 그 이상으로 확장한다면, 현재 상태로서는 구현 비용면에서 현실적이지 않을지도 모른다.
Nehalem에서는 트레이스 캐쉬는 어떻게 되나?
Core MA와 Nehalem의 차이점으로, 또 하나 상정 가능한 것은 "트레이스 캐시"다. NetBurst에서는 x86 명령 디코더가 L1 명령어 캐시인 트레이스 캐쉬 앞에 있고, 추적 캐시는 디코딩 된 uOPs를, 명령 패스를 트레이스 해서 격납한다. 이 구조에서 NetBurst에서는 x86 명령 디코드의 복잡성을 디코더에서 아래의 실행 파이프 라인에서 은폐 할 수 있었다.
그러나 한편으로 단점도 있었다. NetBurst에서는 트레이스 캐쉬를 미스한 경우에는 1 개의 명령 디코더에 의한 디코딩부터 시작하지 않으면 안됐다 (Tejas에서는 여기가 크게 개량될 예정이었다). 또 트레이스 캐쉬에 격납한 것은 x86을 분해한 uOPs이기 때문에 실 명령 수가 부풀어 올라, 트레이스 캐시의 실제 용량을 비대화 시켰다. 그 위에 트레이스 캐시에서 추적한 실행 패스는 디코더가 예측한 추적이며, 실제로 명령 실행된 추적은 아니었다.
따라서 만약 Nehalem에서 Intel이 개량형 트레이스 캐시를 탑재한다고 하면 다음처럼 된다고 예상된다. 트레이스 캐쉬에 격납하는 것은, x86의 CISC의 특성을 어느정도 계승 한 MacroOPs (고정 길이 이지만 여러 오퍼레이션을 포함)로 해서, 캐시하는 실제 명령 수를 줄이는 것이다. 또, 캐시 구조를 바꿔서, x86 명령을 격납하는 L1 명령어 캐시와 MacroOPs를 격납하는 트레이스 캐쉬의 양방을 가질지도 모른다. 실행 파이프 라인의 실행 결과를 기반으로, 백그라운드에서 추적 분석을 진행하고, 반복되어 실행되는 패스의 추적을 L1 명령어 캐시와는 별도의 트레이스 캐쉬에 격납하는 방식이다.

보다 진행된 추적 캐시의 예
이것이라면, NetBurst와 달리, 격납되는 것은 실제로 실행된 추적이 된다. 또, 모든 패스를 거두는 것이 아니기에, 재사용되지 않는 코드의 MacroOPs로 트레이스 캐시의 넘침 걱정은 없다. 또 트레이스 캐시 속에서, 한층 큰 블록 단위로의 명령 스케줄링을 하는 것이 가능하다. 예를 들면, 크리티컬 패스의 오퍼레이션을 캐시 내에서, 추적 가능한 앞쪽으로 이동시키는 것도 가능하다. 더 공격적으로 한다면, 캐시 내에서 명령의 SIMD 화도 가능할지도 모른다.
Gelsinger 씨는 Nehalem에 트레이스 캐쉬를 탑재하고 있는지 어떤지는 "아직 밝힐 수 없다"고 한다. 그러나 트레이스 캐시를 구현한 실적이 있는 힐 스보로라면 가능성은 있을 것이다. x86 아키텍처의 경우에는, 명령 프리 디코드와 디코딩이 매우 복잡해서, 그것을 완화하는 방법은 효과가 있기 때문이다.
Nehalem의 열쇠가되는 3 레벨 캐시 계층
트레이스 캐시에 대해서는, 실제로는 Nehalem에 들어가 있는지 어떤지는 알지 못하지만, Nehalem의 포인트가 캐시에 있는 것은 분명하다. Nehalem은 CPU 코어 각각에 L1 캐시를 갖고 다른 공유 캐시를 갖는다. 이러한 구조는 어떻게 되어있는 것일까, 또 L3 캐시는 CPU에 탑재하는 것일까.

Glenn J. Hinton
Gelsinger 씨는 Nehalem이 전용 L1와 공유 L2를 갖춘다고 인정했다. 또 Glenn J. Hinton (글렌 J · 힌튼) 씨 (Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)는 IDF의 Fellow Shop Talk에서 다음과 같이 말했다.
"Pentium 2/III 까지는 캐시 메모리를 카트리지에 (CPU와 다른 칩) 싣고 있었다. 다음 단계에서 우리는 L2 캐시를 CPU 내부로 넣었다. CPU에서의 내장 캐시의 양은 1 / 2 ~ 4로 줄었지만, 성능은 증가했다. 레이턴시를 줄이고, 대역이 확대됐기 때문이다.
그 이후는, 비용면에서 합당하면 캐시를 증대시켜 왔다. 현재 우리는 몇 레벨의 캐시 계층을 가지고 있다. Nehalem은 3 레벨의 캐시 계층 구조를 갖는다 "
이상의 점에서 알 수있는 것은 Nehalem이 3 레벨의 캐쉬를 가지며, 그것은 아마 칩에 실려있는 것이다. 또 Intel은 캐시 계층화가 Nehalem의 "옵션" 이라고도 말하고 있지 않다. 서버 / 데스크톱 / 모바일에서 캐시 크기가 바뀔 가능성이 있다고 말하고 있지만, 캐시 계층이 바뀔 가능성은 한번도 시사하지 않았다. 따라서 3 레벨 캐시는 모든 Nehalem에 공통되어 있다고 추측된다.
이것은 시사적이다. 통상 L3의 캐시 계층화는, 캐시량이 증대되고, 캐시 액세스 레이턴시가 증대하는 경우에 행한다. 중용량에 액세스가 빠른 L2와, 대용량에 약간 느린 L3로 계층화 한다는 의미다. 또 AMD 아키텍처에서는, 각 CPU 코어가 점유하는 L2를 갖기에, 공유 L3를 갖추는 것은 이치에 맞다. 그러나 중도 용량의 캐시를 단순히 다 계층화 해서도 의미는 얇다. 따라서 Nehalem의 경우는 기존과는 캐시 계층화의 방법이 다를 가능성이 있다.
상정 가능한 캐시 계층 모델의 하나는 위에서 말한것 처럼, L1 명령어 캐시의 한층 상위에 트레이스 캐쉬를 마련하는 가능성. 이 경우는 트레이스 캐시를 L0 명령어 캐시로서 간주하게 된다.
그러나, Intel은 Nehalem 마이크로 아키텍쳐가 "복수 레벨의 공유 캐시"를 갖는다고 설명하고 있다. 말 그대로 받아들이면, 각 CPU마다 L1이 있고, 그 밖에 공유 L2와 L3를 갖게 된다. 이 경우에 생각할 수 있는 것은, L2 캐시에 보다 많은 정보를 부가하는 것이다. 예를 들면, L2에 도입 단계에서, 캐시 라인의 내용을 해석해서 보다 많은 태그 붙임을 행하면 그 외측에 보다 간단한 L3를 갖추는 것은 이치에 맞다. 어쩌면, L2와 L3는 물리적으로는 같은 캐시 SRAM에, 재구성으로 영역을 나누어 구분하고 있을지도 모른다.
실제로 어떻게 되어 있는지는 아직 알 수 없다. 그러나 Nehalem의 3 계층 캐시가 다소 부자연인 것은 것은 확실하다.
[분석정보] x86에서의 탈피를 도모 Intel의 새로운 로드맵
[아키텍처] Intel의 차기 CPU "Nehalem"의 설계 개념은 "1 for 1"
[아키텍처] Nehalem(네할렘)으로 볼 수 있는 인텔 CPU 마이크로 아키텍처의 미래
[정보분석] 인텔의 2013년 CPU 하스웰로 이어지는 네할렘 개발 이야기
[정보분석] 같은 무렵에 시작된 Nehalem과 Larrabee와 Atom
[분석정보] intel의 듀얼 코어 CPU 1번타자 Montecito
[분석정보] 인텔이 목표하는 네할렘 에서의 GPU와 CPU의 통합
[분석정보] 인텔 네할렘과 AMD 퓨전 양사의 CPU + GPU 통합의 차이
[분석정보] IDF에서 공개된 "Nehalem"의 내부 구조
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] AMD, 데스크탑 네이티브 쿼드코어 Phenom을 발표 (0) | 2007.11.19 |
|---|---|
| [분석정보] 2008년 중에 95%를 듀얼 코어로 하는 Intel CPU로드맵의 비밀 (0) | 2007.11.09 |
| [분석정보] 인텔 네할렘과 AMD 퓨전 양사의 CPU + GPU 통합의 차이 (0) | 2007.10.11 |
| [분석정보] 인텔이 목표하는 네할렘 에서의 GPU와 CPU의 통합 (0) | 2007.10.05 |
| [분석정보] AMD가 2009년의 CPU 코어와 통합 CPU의 개요를 발표 (0) | 2007.07.27 |
| [분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA (0) | 2007.06.18 |
| [분석정보] 인텔이 추진하는 32코어 CPU Larrabee (0) | 2007.06.11 |
| [분석정보] 고속화를 가져오는 Radix-16 Divider와 shuffle Engine (0) | 2007.05.24 |