CPU에서 전력을 먹는 명령 디코더
Nehalem 마이크로 아키텍처는, Intel의 향후 CPU의 발전 방향성이 간파된다. 그것은 프로그램 속의 핫 코드, 즉, 자주 실행되는 부분만을 병목을 피해서, CPU에 보다 깊은 캐시해서, 실행을 고속화하는 방향이다. 실제, Nehalem 마이크로 아키텍처를 보면, 실질적인 캐쉬인 루프 스트림의 버퍼 등이 CPU의 실행엔진에 보다 가까운 곳에 배치되어, 매우 계층화 된 캐시 구조로 되어있는 것을 알 수 있다. 그리고, 이것은 x86 CPU의 경우, 자연적인 진화의 흐름 이기도 하다.
x86 CPU의 경우 최대의 짐은 명령 디코더(Instruction Decoder)다. 가변 길이에 명령 형식이 복잡한 x86 명령어 페치부터 디코드까지는, 처리가 어려워 로직이 복잡해진다. 그 때문에, 명령 디코더의 비용(트랜지스터 수)이 높다 (이 기사 보다 조금 더 뒤에 나오는 기사에서는 최근으로 올 수록 CPU에서 다른 부분이 더욱 복잡해지고 커지면서, 상대적으로 디코더의 크기 비율이 작아졌다고 합니다. 최근 일수록 걱정 할 정도가 아니라고 합니다).
CPU의 경우, 비용은 = 전력 소비다. 트랜지스터 수가 많은 복잡한 명령 프리 디코더 & 디코더가 많은 전력을 소비한다. 특히 디코더에서는 비교적 작은 면적이 집중되어 열원이 되기 때문에, 그것이 CPU의 성능을 규정해 버린다. Intel의 Justin R. Rattner (저스틴 · R · 래트너) 씨 (Senior Fellow, Corporate Technology Group 겸 CTO, Intel)는 다음과 같이 말했다.
"(CISC 인 x86 명령 세트의) 가변길이 명령의 디코더는, 고정길이 명령의 RISC 디코더 보다 전력을 소비한다. 인텔이나 AMD의 프로세서의 서멀맵 (온도 분포도)을 보면, 칩상에서 가장 뜨거운 지역이 디코더 부분임을 알 수 있다. 디코더의 전력 효율에 관해서는, 고정 길이 명령 세트 아키텍쳐 쪽이 아무래도 유리하게 된다. (SIMD 유닛 역시 온도가 높은 부분. 특히 AVX에 와서는 더욱 온도가 높음)
여기서 중요한 것은, 프로세서의 성능은 평균 소비전력으로 제약되는 것이 아니라, 피크 온도로 제약되는 것이다. 따라서 핫스팟인 디코더가, CPU의 동작 주파수의 사실상의 제약이 된다. 왜냐하면 그 부분의 접합 온도가 기본값을 초과하지 않도록, 억제하지 않으면 안되기 때문이다. (각 CPU별로 최대 허용온도가 다르고(같은 세대 모델에서도 모델마다 다를 수 있음) 인텔 제품의 경우는 ark.intel.com 에서 모델별로 확인이 가능 합니다. 데스크탑 CPU 경우는 히트스프레더가 있는 관계로 히트스프레더의 허용온도가 (히트스프레더 접촉) 더 낮습니다 (허용 온도가 높아야 쿨링을 덜 해도 괜찮음). 모바일 제품처럼 다이가 직접 노출된 경우는 허용 온도가 (다이 접촉) 더 높습니다. 모바일 쪽이 훨씬 쿨링이 용이하죠. 대신 다이와 잘 고정된 히트스프레더(열 확산판)이 없는 관계로 쿨링 솔류션을 그만큼 잘 접촉시켜야 합니다. 또 코어 깨짐도 조심해야죠. 다만 모바일용은 완제품으로 구입을 하기에 유저하고는 관계가 없죠. 또 핫스팟을 얘기하는 이유는, 위에서도 디코더 부분이 가장 뜨겁다고 말한 것 처럼, 반도체 다이 상에서 열전도율이 전체가 균일하게 유지되지 않기 때문입니다. 히트스프레더 (CPU 뚜껑)에 고열전도율의 써멀그리스에 거대 쿨러를 달아도 마찬가지... 구리가 아무리 열 전도율이 좋다한들... 다른 물질에 비해서 좋은거지.. 어떤 지점의 매우 뜨거운 온도를 전체로 균일하게 전달할 정도는 안되죠. 구리 파이프에 직접 불을 쏜다면 전체 온도가 균일하지 않죠. 불이 직접 닿는 부분만 빨개지고, 반대편은 그냥 뜨겁기만 하죠.)
현재의 CPU는, 복수의 열 센서로 다이 (반도체 본체)의 온도를 측정하고 있다. 다이 위 어딘가의 온도가 규정값에 도달하면, 주파수와 전압을 제어해서 온도를 억제한다. 따라서 CPU의 동작 주파수는, 다이에서 전력 소비가 집중되어 있어 열이 높은 "핫스팟"에 제약되어 버린다. 그리고 x86 CPU에서는, 명령 디코더 방향이 최대의 핫스팟이다.
향후 2 세대 이월되는 명령 최적화
Intel은 Nehalem에도 최대의 열원이 있는 명령 프리 디코더 및 디코더를 더 이상 복잡해지는 것을 피했다. 전력 효율에 초점을 맞춰 성능 효과가 있어도 비용이 높은 개량은 포기했다. 1%의 트랜지스터를 더하는 것은 1% 이상의 성능 향상을 기대할 경우에 한 한다는 것이, Nehalem의 설계 사상이기 때문이다.
Core MA에서는, 명령 프리 디코드 부분에서도 다양한 제약 때문에, 코드 최적화에 몇 가지 제약이 붙어있다. LCP를 피하는, 불필요하게 명령 길이를 길게하지 않는, 등의 제약이다. 그리고 그 대부분은 Nehalem에도 인계된다.
이건은 이전부터 제안은 되어 있었다. Intel은 일본에서 2006년 6월에 실시한 "HPC Developer Conference"에서 코드 최적화에 대해 다음과 같이 설명했다.
"Core MA에 맞추어 코드를 최적화 한다면, 그 최적화의 전부는 아니지만, 그것의 다수는 앞으로 2 세대의 CPU에 걸쳐 효과가 있게 된다. 최적화로의 투자는, 향후 6년간에 걸쳐서 살아 (활용) 있을 것 "
이 세대라는 단어가, 마이크로 아키텍쳐의 쇄신(Tock)을 나타낸다면, Intel은 Nehalem의 차기 "Sandy Bridge (샌디 브리지)"까지, 같은 최적화가 필요한 구조를 유지하는 것이 된다. 즉 프론트 엔드의 구조는 2010년 세대의 CPU에도 인계된다는 것이 된다. 중간 세대의 개량판(Tick) 마이크로 아키텍쳐도 계산한다면, 최적화는 Nehalem까지의 계승이 된다.
6년이라는 표현을 보면, 전자일 가능성은 높다. 2010년에 등장하는 Sandy Bridge가 인계되는 것은 2년 후인 2012년으로, 컨퍼런스가 열린 2006년의 6년 후가 되기 때문이다. 그렇다면 Core MA 의 토대는, Nehalem 뿐만이 아니라 Sandy Bridge에도 계승 된다. 병목 현상 자체는 그 시점까지 남는다고 예상된다.

Nehalem(네할렘)의 개요
데스크탑 용 Nehalem "Bloomfield"의 블록 다이어그램
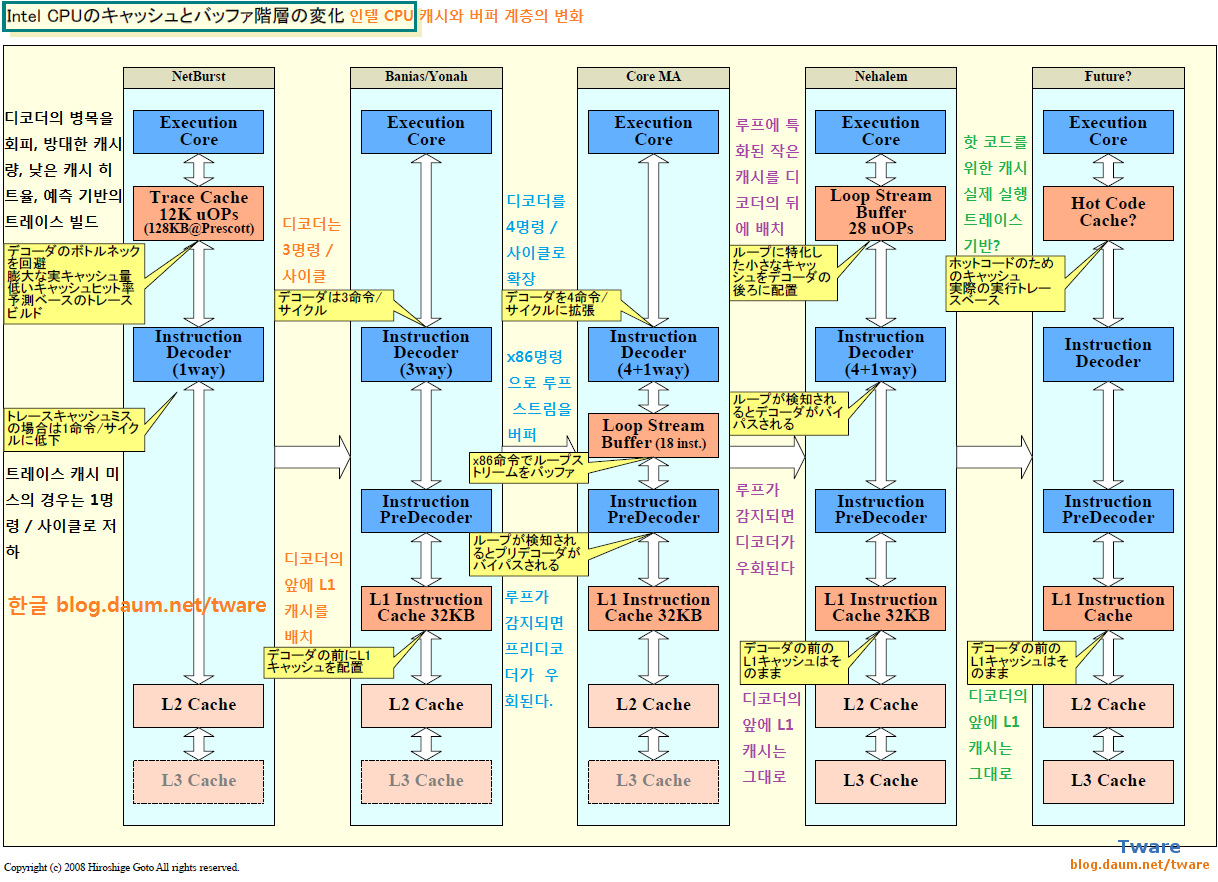
병목 현상을 회피하는 루프 스트림 디텍터
그러면 Nehalem에서는 병목 현상이 남는 명령 프리 디코드나 디코드를 어떻게 회피하는가? Intel은 해결에 비용이 드는 페치 / 프리 디코드 / 디코드에 얽힌 문제에 대한 최선의 해결책 중 하나는, 명령 페치로부터 디코드까지를 실행하지 않고서 완료되도록 하는 것이라고 생각하는 것 같아 보인다.
그것이 보이는 것은 Nehalem에서 구현된 uOPs 기반 "루프 스트림 디텍터 (Loop Stream Detector)"다. Core MA부터 편입된 루프 스트림 디텍터는, 루프를 감지하면 루프 내의 명령을 최대 18 명령까지 캐쉬한다. 실제로는 루프의 경우, 프리 디코더 아래의 명령 큐에 저장한 명령을 플러시 (버리지) 않고서 유지하며, 반복 실행한다. 따라서 Core MA에서는 루프 내의 명령은 다시 페치 & 프리 디코드 할 필요가 없다.
반면 Nehalem의 루프 스트림 디텍터는, 명령 디코더 뒤의 루프 스트림 디텍터가 있어, 루프 내의 uOPs를 최대 28 uOPs까지 캐쉬한다. 따라서 명령 디코더까지 우회 할 수 있다. Nehalem의 리드 아키텍트의 한 사람인 Ronak Singhal 씨 (Principal Engineer, Oregon CPU Architecture, Intel)는 명령 프리 디코드 & 디코드를 비용을 들여 개량하기 보다, 오히려 루프 스트림 디텍터 등 다른 해결책을 강구하는 쪽이 좋다고 판단했다고 말했다.

네할렘(Nehalem)의 루프 스트림 디텍터

코어 마이크로아키텍처(Core MA : 콘로)의 루프 스트림 디텍터

네할렘(Nehalem)의 인출 및 디코딩

Core MA의 인출 및 디코딩
이 발상은, NetBurst (Pentium 4)의 트레이스 캐쉬의 사상과 (규모와 케이스는 한정되지만) 기본적으로 비슷하다. 추적 캐시도, 명령 디코더의 병목 현상을 해결하기 위한 구조 였기 때문이다.
그러나 Nehalem의 리드 아키텍트의 한 사람인 Ronak Singhal 씨 (Principal Engineer, Oregon CPU Architecture, Intel)는 다음과 같이 신중하게 설명한다.
"Nehalem의 루프 디텍터는, 트레이스 캐쉬를 기반으로 했다는 의미는 아니다. 루프 디텍터는 Core MA에 이미 있어, 파이프 라인 속에서 그 위치를 위와 같이 효율적인 위치로 이동하는 것은 자연스러운 확장이기 때문이다. 결과적으로는 비슷하지만 기본 토대는 다르다 "
비효율적이었던 NetBurst의 트레이스 캐쉬
NetBurst에서는, 디코더 이후에 L1 명령 캐시에 해당하는 트레이스 캐쉬를 배치했다. 따라서 트레이스 캐시가 히트하는 한, 명령 디코드의 필요가 없었다. 명령 디코더의 병목 현상을 L1 명령 캐쉬를 디코더 이후로 가져와, 명령 디코드를 파이프 라인에서 제외하는 것으로 실현했다.
그러나, NetBurst의 트레이스 캐시는 매우 고비용에 비효율적이었다. 우선, x86 명령을 uOPs로 분해하면 명령 수가 많아지고, 명령 길이도 길어, 캐시가 비대화 되어 버린다. Prescott에서는 12K의 uOPs를 저장하기 위해서 128KB의 트레이스 캐시를 장착했다. x86 CPU의 일반적인 L1 명령 캐쉬보다 훨씬 크고, NetBurst CPU를 보면 트레이스 캐시가 다이상에서 큰 면적을 가지고 있는 것을 알 수 있다.
또, NetBurst의 트레이스 캐쉬는, 분기 예측에 근거한 예측 트레이스를 캐시하고 있었다. NetBurst에서는, 예측 미스등으로, 캐시 미스가 발생하면, 명령 디코드로부터 실행한다. 그런데, 명령 디코더는 1way이므로, 캐시 미스시에는 1 명령 / 사이클 머신이 되어 버린다.
NetBurst에서 캐시와 버퍼 계층의 변화
NetBurst의 개량 아키텍처였던 "Tejas (테자스, 테하스)"는, 이 부분의 개량에 힘을 쏟았다고 전해진다. Intel 관계자는, Tejas는 파이프 라인 속에 디코더가 2군데에 있어, 캐시 미스 때의 디코딩 효율을 극적으로 올린 아키텍처 였다고 말했다. 그러나 Tejas는 CPU 코어가 지나치게 복잡해졌기 때문에, 멀티 코어화의 흐름 속에서 취소되고 말았다. 여기서도 디코더 부분을 확장하면 x86 CPU가 비효율적이 되는 것이 암시되어 있다.
핫 코드만을 격납하는 uOPs 캐시
비용이 높고, 효율이 나쁘고, 캐시 미스 때의 패널티가 큰, NetBurst의 트레이스 캐시는 이 마이크로 아키텍처의 약점이었다. 따라서 Pentium III에서 확장된 Pentium M (Banias : 베니어스)에서는, 명령 디코더 전에 L1 명령 캐쉬가 배치 되었다. 추적 캐시의 시도는 파산되고, 또 한번, 일반 x86 CPU의 스타일로 돌렸다. 전력 효율을 생각하는 경우에, 트레이스는 효과적이지 않다고 인정한 모습이다.
그리고, Pentium M에서 발전한 Core MA에서는, 명령 프리 디코더와 명령 디코더의 사이에 루프스트림 디텍터 버퍼 (물리적으로는 명령 캐시)를 끼우는 아키텍처가 되었다. 즉, 명령 프리 디코드의 병목을 회피 가능한 부분에, 루프에 특화된 캐쉬를 배치했다. 자주 사용하는 코드 부분(핫 코드)에 대해서는, 보다 CPU의 실행 엔진에 가까운 곳에서 캐시한다 라는 시도라고 말할 수 있다.
그리고, Nehalem에서는, 루프 스트림을 위한 버퍼가, 명령 디코더의 이후에 설치되었다. x86 명령 큐를 루프 스트림 버퍼로서 사용하는 대신에, uOPs 큐를 버퍼로서 사용하게 되었다. 핫 코드 부분의 캐시가 점점, CPU 안쪽으로 이동해 가는 것을 잘 수 있다. 그러나, NetBurst와 달리, 디코더 밖의 L1 명령 캐쉬는 그대로, 디코더 안쪽의 uOPs 캐시는 매우 작은채이다.
NetBurst의 트레이스 캐쉬에서는, 1 번만 실행하는 코드 부분(콜드 코드)도, uOPs 캐시에 저장되어 있었다. 반면 Nehalem의 방법에서는, 콜드 코드는 디코더 밖의 L1 캐시에 있어, 루프 부분의 핫 코드만 uOPs에 캐시된다. 따라서 트레이스 캐시와 비교하면 작아도 매우 효율적이다.
따라서 이 흐름이라면 논리적으로 예상되는, Intel CPU의 진화 방향성은 다음과 같다. 명령 디코더 아래에 배치하는 캐시를 한층 크게 한다. 보다 긴 루프나, 실행중인 루프 이외의 핫 코드도 감지해서 저장하도록 한다. 실제 명령 실행을 기반으로 하는 실행 트레이스를 캐시한다. 그러면 보다 많은 코드에 대해서, CPU의 프론트 엔드의 병목 현상을 회피시키는 것이 가능하다.
실제로, Intel이 그러한 구현을 하는지 어떨지는 알 수 없다. 그러나 x86 명령의 프리 디코드와 디코드가 병목이 있어, 그 개선이 전력 효율적으로 보면 맞지 않는 것인 이상, 전력 효율을 유지하면서 성능을 올리는 방법은, 이론적으로는 보다 많은 명령 실행에서 병목 현상을 회피하는 것이 된다. 핫 코드만을 캐시하면, 예전 Transmeta가 그랬던 것처럼, 핫 코드만을 백그라운드에서 최적화하는 것 같은 수법을 채택하는 것도 가능하다.
Nehalem에 보이는 것은, Intel이 Core MA의 기본에 자신을 가지고, Core MA를 기반으로 명확한 방향으로 CPU 마이크로 아키텍쳐의 개발을 진행하고 있는 것이다. 그만큼 NetBurst에서 전력효율을 악화시킨 실패에 질렸다고 추측된다.
[아키텍처] Core Microarchitecture"속도의 비밀은 "CISC의 아름다움"
[정보분석] 인텔의 2013년 CPU 하스웰로 이어지는 네할렘 개발 이야기
[아키텍처] 왜 Sandy Bridge는 성능이 높은가?
[아키텍처] 폴락의 법칙에 찢어지고 취소된 테자스(Tejas)
[아키텍처] Intel 차세대 하이퍼 쓰레딩 (Hyper-Threading) 기술 공개
[01년02월06일] 2010년 CPU 소비 전력은 600W?
[01년01월11일] Intel의 0.13μm 공정 P860/P1260에서 CPU는 어떻게 바뀌나
[분석정보] IDF에서 공개된 "Nehalem"의 내부 구조
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] Larrabee에 쫓기는 NVIDIA가 GT200에게 입힌 GPGPU용 확장 (0) | 2008.07.16 |
|---|---|
| [분석정보] 인텔 박물관/연구소 견학기 4004 전자 계산기부터 최신 기술까지 (0) | 2008.07.01 |
| [분석정보] 지포스 GTX 280 배정밀도 부동 소수점 연산 (0) | 2008.06.20 |
| [분석정보] 9년전의 아이디어에서 태어난 아톰. 리서치 @ 인텔 (0) | 2008.06.13 |
| MSI 에릭 장, Gigabyte와 ASUS에 정면으로 대응 (0) | 2008.05.19 |
| [분석정보] 인텔의 대항에 직면한 AMD의 서버 로드맵 (0) | 2008.05.13 |
| [아키텍처] Intel의 차기 CPU "Nehalem"의 설계 개념은 "1 for 1" (0) | 2008.04.24 |
| [분석정보] 왜 인텔은 샌디브릿지에 AVX를 구현하는가? (0) | 2008.04.10 |