공정 세대 마다 명령어 세트 확장

신 명령 확장을 발표하는 Patrick P. Gelsinger 씨
Intel은 45nm 프로세스 세대의 CPU "Penryn (펜린)"에서 새로운 명령어 세트 확장 "SSE4"와 가속기 "Application Targeted Accelerators"의 구현을 시작한다.
이전 기사 에서 명령어 세트 확장의 시기에 대해 불분명이라 쓴 것은 실수로 많은 명령은 먼저 Penryn에 구현된다. 나머지 Penryn 후의 CPU에 구현되는 시기, "Nehalem (네할렘)"이 해당한다고 볼 수 있다. Penryn은 Core MA를 45nm 공정으로 미세화뿐만 아니라, 명령 세트의 확장과 단일(다이) 쿼드코어판을 포함하게 된다. (1다이 쿼드코어 화이트필드는 인텔 인도 하위 센터의 개발지연으로 최종 취소. CPU 코어는 콘로 아키텍처. 취소되고 켄츠필드& 요크필드로 대동단결. 인텔 개발 센터는 메인 개발센터와 하위 개발센터가 존재. 메인 개발센터는 데스크탑&서버&노트북용에서는 2개팀이 동시 개발로 2~2.5년에 신 아키텍처 등장. 아톰및 제온파이 개발센터도 메인센터. 하위 개발센터는 개발된 제품의 변형 상품을 설계하는 곳. 개발기간 통상 5년.)
명령어 세트의 확장은 크든 작든 마이크로 아키텍처의 확장을 동반한다. 따라서 Intel은 공정 기술을 쇄신하고 더 많은 트랜지스터를 CPU 코어에 할애 할 수 있게 되는 시점에서, 명령 세트를 확장하고 있다. 공정 세대와 명령어 세트 확장은 함께 발전해 왔다. 놀랍게도 마이크로 아키텍쳐의 쇄신은 반드시 연동하고 있지 않다.
구체적으로는 Intel의 명령 세트 확장의 역사는 아래 그림과 같다. 옛날에는 x87 부동 소수점 명령어의 추가가 있지만, 여기에서는 IA-32 이후의 SIMD (Single Instruction, Multiple Data) 명령어의 추가를 중심으로 한 확장을 나열했다.
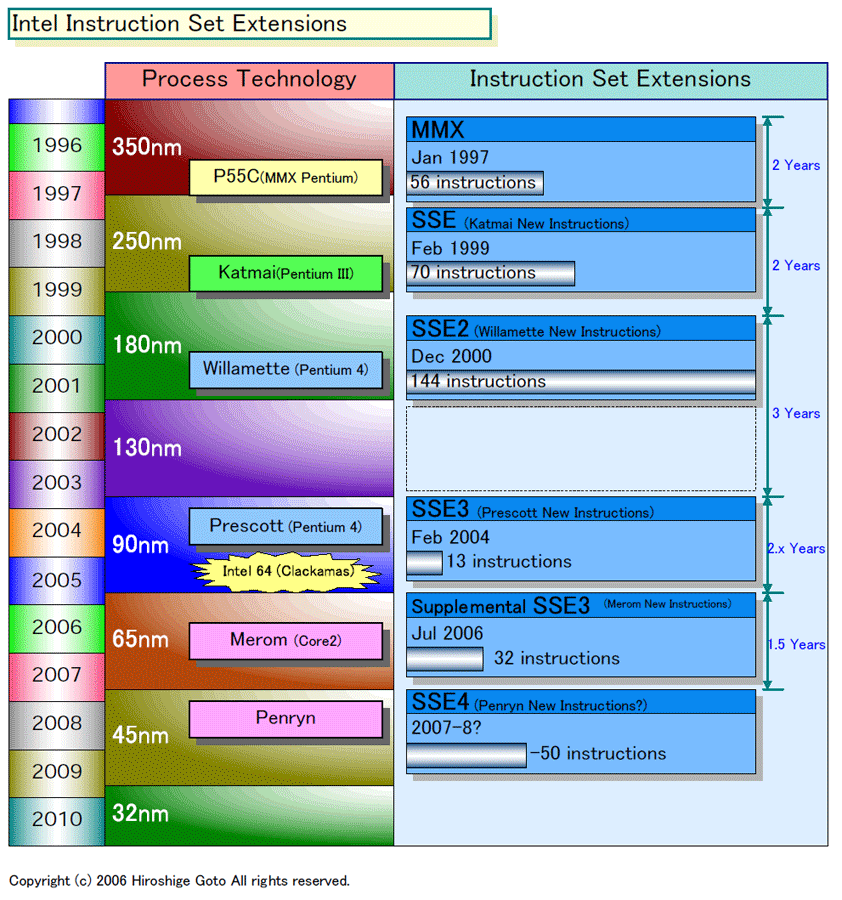
Intel Instruction Set Extensions
첫 번째 확장은 '97 년 'MMX'로 350nm 프로세스의 MMX Pentium (P55C)에서 구현됐다.. 그런 다음 "SSE (Katmai New Instructions)" "SSE2 (Willamette New Instructions)"라고 Intel은 공정을 1세대 미세화 할 때마다 1 그룹씩 확장 명령을 가해왔다. 추가된 명령 수는 MMX가 56 명령, SSE가 70 명령, SSE2가 144 명령.
명령 확장 속도가 둔화된 것은 130nm 이상에서 90nm 판 Pentium 4 (Prescott : 프레스컷)는 "SSE3 (Prescott New Instructions)"의 13 명령, Core 2 (Merom : 메롬)는 "Supplemental SSE3 (Merom New Instructions. SSSE3 ) "32 명령이 첨가됐다. Intel은 2세대 명령 확장이 한세트로 SSE3라 정의하고 있다. Prescott와 Merom의 명령 확장은 비교적 작은 셈이다.
하지만 실제로는 Prescott은 "Intel 64 (이전 EM64T) '가 구현되고, ISA 자체는 크게 확장되어 있다. 참고로, 원래 계획은 Prescott 다음 "Tejas (테하스)"8 개의 새로운 명령어 (Tejas New Instructions)가 첨가하게 되어 있었다. MNI (Merom New Instructions)이 TNI (Tejas New Instructions)의 상위 집합이라고 추정된다.
정리하면 350nm가 MMX, 250nm가 SSE, 180nm가 SSE2, 130nm가 빠지고, 90nm와 65nm에서 SSE3 (+ Intel 64)가 확장되었다. 공정 기술의 발전과 함께 명령어 세트가 복잡하게 온 셈이다. 그리고 45nm 공정의 SSE4는 그 다음에 오는 확장된다.
벡터화를 지원하는 SSE4 명령
SSE4의 특징은 컴파일러에서 자동 벡터화를 지원하는 명령을 중심으로 하고 있는 것이다. 벡터화에는 컴파일러가 스칼라 소스 코드에서 벡터화 (SIMD 화) 할수 있을 것 같은 코드의 국소성을 찾는다. 예를 들어, 32bit 값에 대해 32bit의 값을 더하는 연산이 반복되는 경우 그것을 4개의 32bit 값이 포함된 128bit SIMD 데이터에 마찬가지로 32bit × 4 SIMD를 가해 연산하면 연산은 4번이 1번으로 줄어든다.
일반적으로 벡터라이제이션이 쉬운 것은 루프에서 같은 작업을 반복하는 일련의 데이터에 대해 행하는 경우가 많다. 다음에 컴파일러는 스칼라 명령을 벡터 명령으로 변환 또한 데이터를 SIMD에 팩 / 언팩 하는 명령을 추가한다. SSE4에서는 데이터 포맷 전환 등 이러한 일련의 작업을 쉽게 하는 명령을 포함하고 있다.
벡터화 의도는 SIMD에 의한 데이터 수준의 병렬성 "DLP (Data-Level Parallelism)"을 사용하면서, 실질적으로 명령 수준의 병렬성 "ILP (Instruction-Level Parallelism)"를 올리는 것에 있다. CPU의 단일 쓰레드 애플리케이션 성능은 작동 주파수 × IPC (instruction per cycle) × 명령 스텝 수에 비례한다. 벡터화에 의해 주문 단계 수를 줄여 쓰레드의 병렬성을 높인다. Intel은 SIMD 유닛의 성능을 높이는 방향으로 향하고 있어 그것을 이용하려는 의도다.
또한 Intel은 SSE4 이외에 CPU에 통합하는 액셀레이터 코어용 명령에 대해서도 언급하고 있다.

래트너 씨 기조 강연에서 소개 된 테라 스케일 프로세서에 대한 자세한
Intel이 밝힌 것은 "애플리케이션 타겟티드 액셀러레이터 (Application Targeted Accelerator) '라고 부르는 일종의 코프로세서인 고정 기능 유닛을 CPU에 통합해 나가는 것이다. 특정 응용 프로그램이나 특정 처리에 특화한 가속기를 범용 CPU에 통합한다. 이러한 가속기는 대상 응용 프로그램을 매우 빠르게 하면서도 소비 전력을 억제 할 수 있다. CPU 및 시스템의 효율화를 도모하는 좋은 솔루션이다.
Intel은 테라 스케일 컴퓨팅 (매니 코어)에서도 고정 기능 추가를 강조하고 있다. 45nm 공정 세대에서 그것이 실제 CPU 제품에 구현되기 시작 것 같다. 이 때문에는 테라 스케일 구상은 Intel의 CPU 아키텍처의 방향성의 집대성인 것으로 나타났다.
응용 프로그램에 특화된 가속 명령
지금까지의 범용 (General Purpose) CPU는 가능한 범용적으로 사용할 수 있는 명령을 중심으로 해왔다 (실제로는 그렇지도 않은 명령도 있다). 하지만 가속기 명령은 그것과는 분위기가 다르다. 아예 애플리케이션에 특화한 특수 명령이 된다고 한다.
그 중으로, Intel이 먼저 구현하려고 하는 것은 "Cyclic Redundancy Check (CRC : 순환 중복 검사)"의 가속. CRC 가속기를 위해 CRC 값의 검사 명령 "CRC32"를 구현한다. CRC는 데이터 무결성, 즉 데이터가 손상된 여부를 체크하는 구조. 대상으로 하는 데이터에서 생성된 CRC 값을 비교하여 점검한다.
CRC는 통신이나 스토리지에서 자주 사용되고, Intel도 네트워크 스토리지를 대상으로 한다고 설명했다. Intel에 따르면, "iSCSI (Internet Small Computer System Interface)"및 "RDMA (Remote Direct Memory Access)"와 같은 스토리지 데이터 전송 기능 프로토콜 가속이 주목적 이라고. 현재는 이러한 프로토콜 처리를 CPU 오프로드 하는 전용 칩도 사용되고 있지만, Intel의 구상은 그것을 CPU 기반으로 통합에 있다. CPU의 범용 코어를 오프로드 하거나 외부 부착의 가속기 카드의 필요성을 없앰으로써 시스템 전체의 소비 전력을 낮추게 된다.
또한 Intel은 두 번째 가속기 명령으로 대형 데이터 셋트의 검색용 명령 "POPCNT"를 들었다. Population Count 명령에서 오퍼랜드의 비트 세트 수를 센다. Intel은 응용 예로서 게놈 마이닝, 필기 인식, 허밍 알고리즘 등을 들고있다.
Intel의 45nm 프로세스 세대의 CPU는 범용 연산 유닛뿐만 아니라 CRC 가속기 및 검색 가속기 2종류의 고정 기능 유닛을 갖게 될 것 같다. Intel은 이 두 가지가 통합해도 비용에 걸맞은 가속이라고 판단했다.
ILP 월이 CPU 업계의 공통 인식
SSE4 와 가속 명령이 시사하는 것은 향후 Intel의 CPU 성능 향상의 방향이다. 컴파일러에서 벡터화로 병렬성을 높이고 액셀러레이터에 의해 특정 처리의 효율성을 크게 개선한다. 이런 접근 방식에서는 CPU의 성능을 컴파일러와 가속기 하드웨어에서 올리려는 의도가 느껴진다.
하지만 당연한 방향이다. 라는 것은, 싱글 스레드 성능의 향상은 이제 전통적인 ILP 향상 기술이 그다지 유효하지 않기 때문이다. 그것은 ILP 향상의 여지가 작아져 가기 때문이다.
현재 CPU 아키텍처는 ILP 향상이 벽을 앞두고 있다고 한다. 예를 들면, 컴퓨터 과학 연구자로서 유명한 David A. Patterson (데이비드 · A · 패터슨) 교수 (University of California at Berkeley)는 2006년 8월 칩 컨퍼런스 "HotChips 18"에서 ILP의 벽 "ILP 월 (ILP Wall) "에 대해 언급했다. 그에 따르면, ILP를 올리기 위해 하드웨어 리소스를 추가해도 거기에서 얻어지는 ILP 향상의 정도가 줄고 있다 한다. 즉, ILP를 조금 높이기 위해 지금까지 보다 많은 트랜지스터를 필요로 해 성능 향상이 비효율화 되는 것이다.
Patterson 씨는 이 외에도 소비 전력의 벽 "파워 월 (Power Wall)"과 메모리 액세스의 벽 "메모리 월 (Memory Wall) '이 CPU 성능 향상의 장벽이 되고 있다고 지적했다. 그 결과 단일 프로세서의 성능 향상은 기존의 1.5 년에 2배 정도에서 5년에 2배 정도로 떨어질지도 모른다고 시사했다. 즉, 싱글 코어 성능은 더 이상 이전과 같은 속도로 올라 가지 않는다. (여기서의 성능 향상은 IPC만이 아닌, 클럭을 포함한 겁니다. 클럭 향상이 점점 없어지죠. 특히 클럭을 못 올리는건 열밀도가 가장 문제가 큽니다. 같은 CPU에서 클럭이 오른다면, 코어의 핫스팟의 온도가 엄청나게 오르기 때문이죠. 열이 분산되어 온도가 낮아지는 것 이상이라.. 온도 해소가 안됩니다.)

컴퓨터 아키텍처의 상식의 변천
다수의 CPU 제조사들이 멀티 코어화에 의한 TLP 방향으로 뛰어가는 것은 그 때문이다. 싱글 코어로 성능이 오르지 않는다면 코어 수를 늘려 성능을 올리려는 흐름이다.
그런데 Intel은 새로운 마이크로 아키텍처 Core MA에서는 NetBurst에 비해 싱글 코어의 ILP도 크게 끌어 올렸다. 그 가장 큰 이유는, NetBurst의(펜티엄4) ILP가 원래 낮았기 때문이지만, 다른 CPU 벤더가 ILP에서 TLP로 초점을 옮기고 있는 것과 꽤 방향이 다르다. Core MA 만 보면 Intel은 ILP를 계속 늘리고 있는 것 처럼 보인다.
ILP에 한계가 보였기 때문에 SSE4와 가속기로 향하는
그러면 Intel은 앞으로도 이번 Core MA와 같은 속도로 ILP를 끌어 올릴 수 있다고 생각하고 있는 것일까.
아무래도 그렇지 않을 것 같다. 예를 들어, Intel의 Joel S. Emer 씨 (Intel Fellow, Director, Microarchitecture Research, Enterprise Group)는 이번 IDF의 Q & A 세션 "Shop Talk"때 다음과 같이 설명했다.
"싱글 코어 ILP는 앞으로도 계속해서 향상되지만. 그만큼 눈부신 비율은 되지 않는다. ILP를 올리기 위한 구현 비용이 높아졌기 때문이다. 우리는 계속 코어도 확장해 가지만, 실리콘을 보다 효율적으로 사용하기 위해서는 CPU 코어의 수도 늘려 간다. ILP와 TLP의 조합의 균형을 잡는다. "
Emer 씨는 본래 DEC에서 Alpha EV8 등의 아키텍트로 지냈다. Emer 씨의 의견도 거의 Patterson 씨와 공통되었다. 참고로, HotChips 18 키 노트에서 등장한 Intel의 Justin R. Rattner (저스틴 R · 래트너) 씨 (Intel Senior Fellow, Director, Corporate Technology Group)도 향후 싱글 코어의 성능은 그다지 올라 가지 않는다 라고 말했다.

David Perlmutter 씨
Intel의 Mobility Group을 총괄하는 David (Dadi) Perlmutter 씨 (Senior Vice President, General Manager, Mobility Group)도 다음과 같이 말했다.
"싱글 쓰레드 와 멀티 쓰레드를 모두 올린다. 우리는 단일 쓰레드 성능을 (Core MA)에 올렸으나 멀티 코어에 보다 중점을 뒀다.하지만 단일 스레드 응용 프로그램의 성능도 계속 향상 시키려 한다. 그때문에 모든 종류의 테크닉을 쓴다.
ILP 향상은 그 중 하나지만, 다른 방법은 부동 소수점 연산에서 (컴파일러에서) 벡터 화에 의해 싱글 쓰레드 디지털 미디어 성능을 올린다. 또 마이크로 아키텍처는 물론 시스템 레벨에서의 성능 향상도 도모한다. 예를 들어, 메모리 계층 구조의 개선 등이다 "
Perlmutter 씨도 싱글 쓰레드 성능 향상은 역동적인 ILP 향상 기술뿐 아니라 벡터 라이 제이션 및 시스템 수준의 개량에 의한 메모리 월의 경감 등 복합적인 접근으로 달성한다는 느낌이다.
이렇게 보면 Intel도 ILP 향상은 벽에 부딪쳐 있는 것을 전제로 아키텍처를 생각하는 것을 잘 알수 있다. 아마 향후 Intel 마이크로 아키텍처는 이번 Core MA 정도로 하드웨어에 의한 동적 ILP의 대폭적인 향상은 바랄 수 없다. 즉, CPU 코어 자체의 동적 ILP는 그만큼 올라가지 않는다.
CPU 리소스는 CPU 코어 내부에서 부동 소수점 연산 SIMD 계의 확장에 쓰고, 또한 CPU 코어를 늘리는데 투입한다. 단일 스레드 성능 향상은 컴파일러 벡터라이제이션 이나 특정 애플리케이션 가속기 탑재로 올려 간다. 그리고, 전체의 성능은 멀티 코어를 활용하여 올린다. 기본적으로는 향후 Intel CPU의 발전은 이러한 라인에 있는 것을 알 수 있다.

Intel Microarchitecture Cycle
2006년 10월 4일 기사 입니다.
[분석정보] x86에서의 탈피를 도모 Intel의 새로운 로드맵
[분석정보] IDF 2007 Penryn 벤치마킹 세션 리포트
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] 인텔 45nm 공정 차세대 CPU Penryn(펜린) High-k 메탈게이트 성공. (0) | 2007.01.29 |
|---|---|
| [분석정보] Intel 또 하나의 차세대 CPU LPP (0) | 2006.10.23 |
| [분석정보] 대폭 강화된 AMD의 쿼드 코어 Barcelona (0) | 2006.10.16 |
| [분석정보] AMD가 쿼드 코어 CPU Barcelona의 상세를 발표 (0) | 2006.10.13 |
| [분석정보] 차세대 CPU 힌트가 나왔다 IDF (0) | 2006.10.02 |
| [분석정보] 차세대 기업용 플랫폼 "Weybridge" 데모 (0) | 2006.09.29 |
| [분석정보] Intel의 UMPC는 이륙 직전 (0) | 2006.09.29 |
| [분석정보] 미래를 지향하는 Intel의 연구 (0) | 2006.09.29 |