트랜지스터당 비용이 반도체 업계의 가장 큰 문제
무어의 법칙은 앞으로도 계속되지만 법칙 자체의 의미가 없어진다. 그러한 위기가 임박했다는 견해가 퍼지고 있다. CMOS 프로세스의 미세화는 계속할 수 있지만 트랜지스터의 비용 하락이 멈춰 버릴 가능성이 있기 때문이다. 전환점은 28nm 공정으로 여기보다 미세화하면 공정 기술의 복잡화와 도구의 고가격화 때문에 웨이퍼당 비용의 상승이 급등하게 된다고 한다. 웨이퍼당 비용 상승이 CMOS 스케일링의 장점을 상쇄해 버리기 때문에, 트랜지스터당 비용이 내리지 않을 것으로 알려져 있다.
이 문제가 크게 받아들여지기 시작한 것은 2년 정도 전으로, 아울러 다양한 움직임이 반도체 업계에서 일어나고 있다. 하나는 450mm 웨이퍼로의 전환으로 웨이퍼의 대구경화에 의한 트랜지스터당 비용 절감, 미세화에 의한 비용 절감의 한계를 완화하려고하고 있다. 450mm 로의 이행이 한때 급 가속된 원인의 하나는 이 트랜지스터 비용 절감의 한계에 있다. "450mm 아자아자 " Intel에 끌려가는 형태로, 업계는 450mm로 움직이고 있다.
한편, 28nm 공정을 장기적인 노드로 미세화를 뒤로 미루고 있는 칩 벤더 측의 움직임도 있다. 20nm 공정의 디자인이 시작된 무렵부터 그러한 움직임이 활발해 지고 있다. 20nm 이후의 비용이 보였기 때문이다. 전형적인 대응은 ARM이 28nm 공정용 (POP을 28nm 준비)으로 새로운 CPU 코어 "Cortex-A12 '의 라이센스를 시작한 것이다. ARM은 28nm가 장기적으로 남는다 생각하고, 비용에 민감한 고객을 위한 코어를 28nm에 맞춰 냈다.
CMOS 공정의 미세화에 의한 비용 절감의 맛이 사라져 가는 것을 웨이퍼의 대구경화로 상쇄하려는 일부 반도체 제조업체. 그것에 비해 미세화는 잠시 미루고 시든 28nm까지의 공정에 머물고 있는 일부 칩 벤더. 28nm 이후의 움직임은 복잡한 상황이 되기 시작했다.
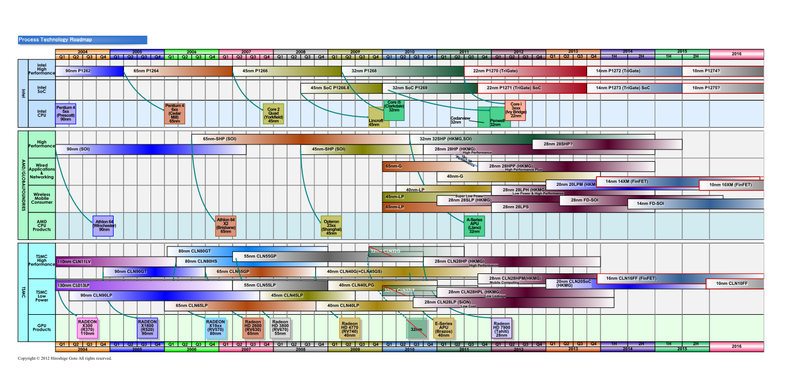
주요 파운드리의 프로세스 로드맵
고전 스케일링은 무료 점심이었던 트랜지스터 수 증가
성능 CPU와 GPU 또는 모바일 SoC (시스템 온 칩)를 만드는 칩 벤더에게 트랜지스터 당 비용의 상승은 매우 심각한 문제이다. CMOS 공정의 미세화를 실현해 왔던 CPU와 GPU의 아키텍처와 기능의 진화에 경제적으로 제동을 의미하고 있기 때문이다. NVIDIA가 이 문제를 지적하는 선봉장인 이유는 거기에 있다.
옛 고전 CMOS 스케일링의 시대에는 모든 것이 괜찮았는데. 프로세스 노드가 1세대 (0.7 배 = 가로 세로 0.7로 줄어들면 면적은 0.5배가 되죠.) 미세화 되면 트랜지스터의 크기는 절반의 0.5 배가 되어, 같은 크기의 다이 (반도체 본체)에 2배의 트랜지스터를 올릴 수 있었다. 그렇게 하면, 웨이퍼의 공정 비용은 거의 변함없이, 트랜지스터당 비용이 절반 0.5 배가 되었다. 칩에 싣는 트랜지스터를 세대마다 배가 되어도 칩당 비용은 거의 일정했다. 또한, 구동 전압은 0.7 배, 소비 전력은 0.5 배, 동작 주파수는 1.4 배가 되었다.
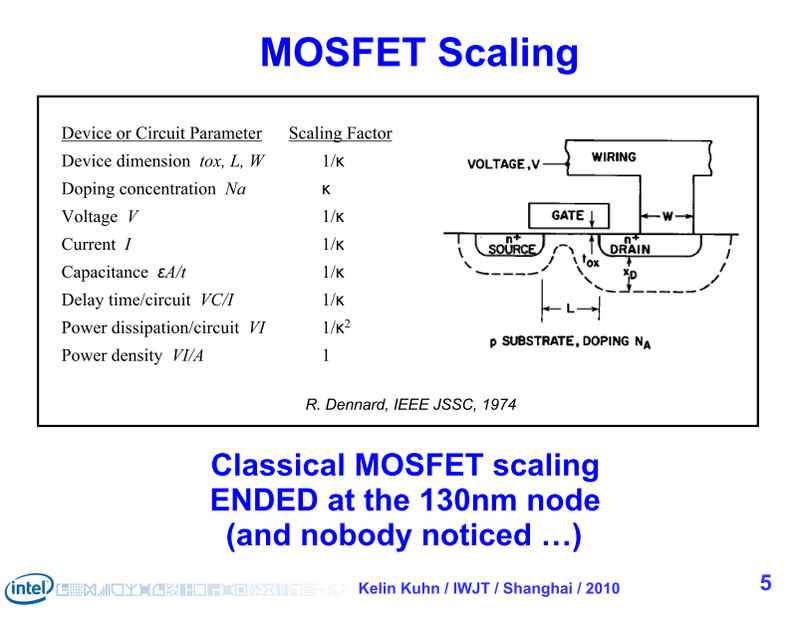
전통적인 CMOS 스케일링의 모식도
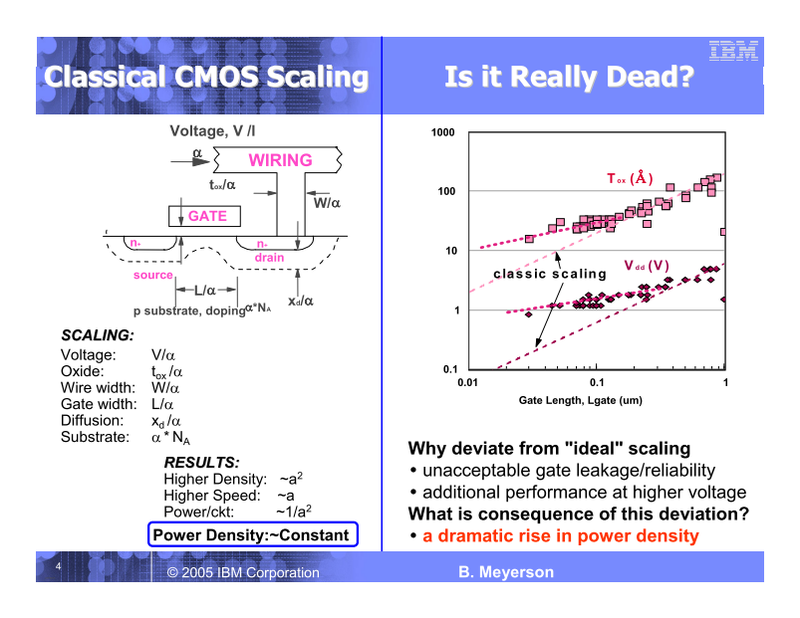
전통적인 CMOS 스케일링의 게이트 길이와 전압의 상관 관계
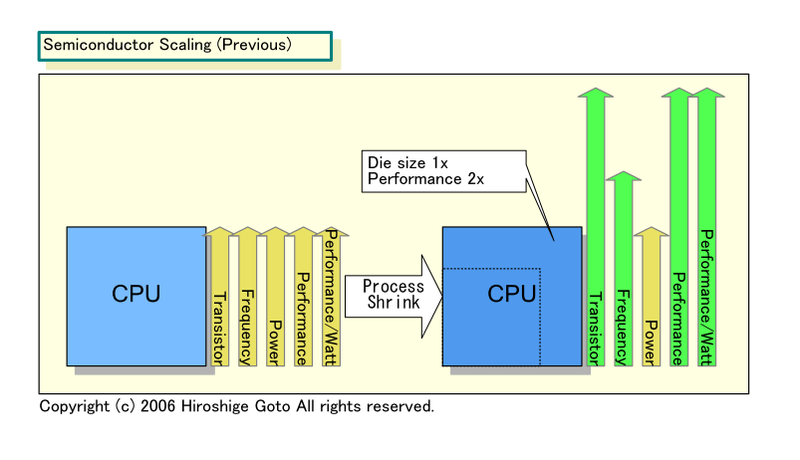
전통적인 CMOS 스케일링에서 얻은 혜택
그러나 점차적으로 구동 전압이 스케일 다운되지 않게 되고 전력이 감소되지 않게 되어 동작 주파수의 성장도 완만하게 되었다. 전력과의 싸움이 시작되었다. 그래도 트랜지스터당 비용은 떨어짐이 계속되어 반도체 업체들은 무어의 법칙의 장점을 누릴 수 있었다. 공정 세대마다 칩의 트랜지스터 수를 배로 늘리고,이를 통해 연산 유닛을 늘려 아키텍처를 확장하고 기능을 통합 하였다. 그러나 이것은 세대마다 트랜지스터 비용이 떨어질 것이라는 전제가 있었기 때문이었다.
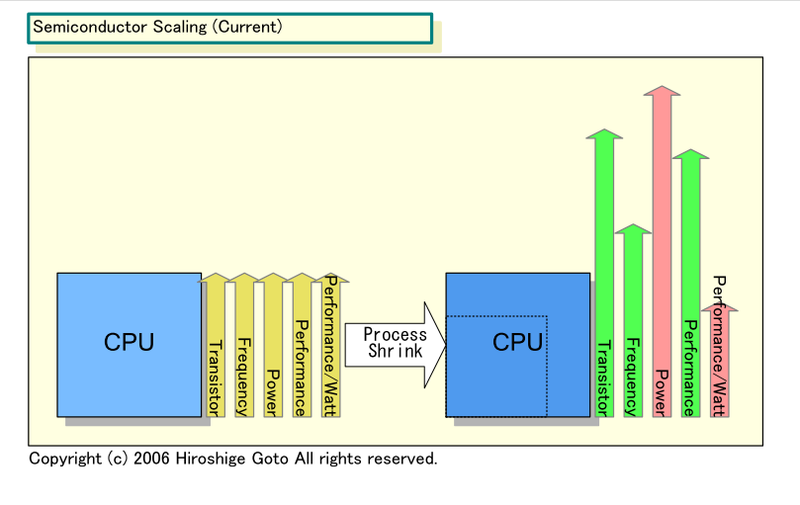
CMOS 스케일링의 현황
웨이퍼당 비용 상승 영향
지난 몇 세대에 걸쳐 웨이퍼 자체의 비용이 상승 웨이퍼당 공정도 복잡한 만큼 (예를 들어 노출이 다중 된) 비용이 상승했다. 그래도 CMOS 스케일링의 효과는 웨이퍼당 비용 상승을 계속 웃돌아, 트랜지스터당 비용은 추락했다. 55nm보다 40nm 쪽이 트랜지스터 비용은 낮고, 40nm보다 28nm 쪽이 더 떨어졌다. 따라서 CPU와 GPU, SoC 제조 업체는 공정의 미세화 때 마다 같은 수준의 다이 사이즈로 동 가격대의 칩 아키텍처와 성능을 확장했다. 예를 들어, GPU 아키텍처는 28nm에서 NVIDIA는 Kepler (케플러)를 AMD는 GCN (Graphics Core Next)을 실현했다.
그런데 내년은 상황이 달라진다. 공정이 미세화하면 웨이퍼당 비용이 크게 상승하는 것으로 알려져 있기 때문이다. 만약 1세대 미세화로 웨이퍼당 비용이 2배까지 증가한다면, CMOS 스케일링으로 실리는 트랜지스터 수가 2배로 증가되도 비용 절감의 효과는 상쇄되어 버린다. 사실 거기까지 오르지 않기는 하지만, 트랜지스터당 비용이 이전 세대로 떨어지지 않게 된다고 알려져 있다.
그렇게 되면, 동일한 정도의 트랜지스터 수의 칩이라면 미세화 해도 비용이 너무나 떨어지지 않게된다. 그리고 트랜지스터 수를 두배로 한 칩을 만드는 경우 대당 비용은 지금까지보다 크게 증가해 버리는 것이된다. 트랜지스터 비용이 올라도 높은 가격의 하이 엔드 CPU와 GPU 하이 엔드 모바일 SoC는 어느 정도 부응 되지만 경제성이 중요한 미드 레인지 이하의 칩은 미세화가 맞지 않게된다.
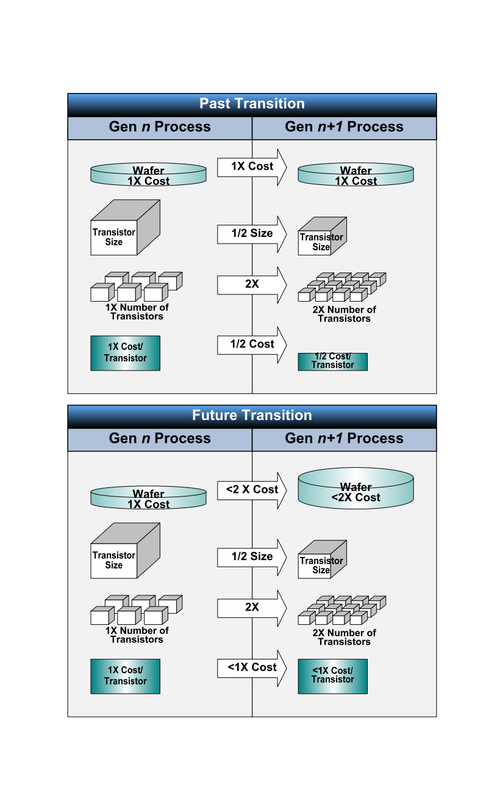
프로세스 세대 마이그레이션 및 비용의 변화
비용 스케일링이 정체하는 파운드리 공정
파운드리의 20nm 공정은 현재 디자인이 시작되고 있다. 그리고 문제가 표면화 되고 있으며, 28nm에 머무르는 또는 20nm로 진행 여부로 나눠지고 있다 한다. 또한 파운드리는 20nm 끝으로 트랜지스터를 기존 평면에서 FinFET 3D 트랜지스터로 전환. 이것은 20nm 프로세스의 백엔드를 유용하여 트랜지스터만 FinFET로 전환하는 공정으로 GLOBALFOUNDRIES는 14nm TSMC의 16nm와 노드 세대의 이름을 붙이고 있다.
20nm에서 16/14nm로의 전환은 백엔드는 공통이므로, 원리적으로 트랜지스터는 스케일 다운하지 않는다. 뿐만 아니라, 멀티 채널에서는 트랜지스터 크기가 커질 수도 있다. 따라서 공정이 이주되도 트랜지스터 밀도는 원칙적으로 다르지 않다. 또한 FinFET 화로 웨이퍼당 비용이 증가하는 것으로 알려져 있으며, 트랜지스터당 비용은 더욱 올라 버린다. Intel은 지난 5월 Jefferies TMT Conference 프리젠테이션에서 이 문제를 아래의 슬라이드에서 지적하고 있다.
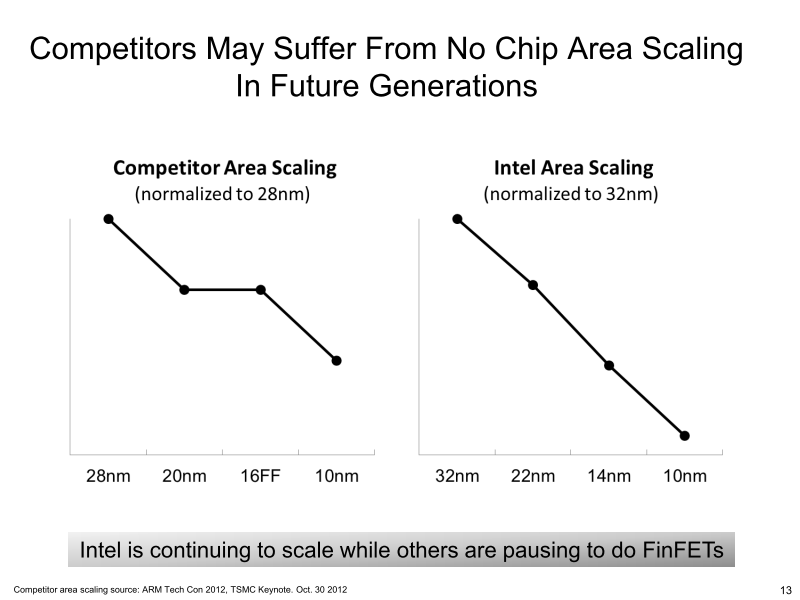
20nm → 16nm FinFET에서 스케일 다운이 없음을 지적했다 Intel의 Jefferies TMT Conference에서 슬라이드
GPU에서 보면, NVIDIA 말해서, 20nm 것으로 보이는 "Maxwell"(맥스웰)에서 문제가 두드러지고, 16nm 추측되는 "Volta"(볼타)에서는 더욱 문제가 커진다. AMD 말로는 20nm의 GPU "Volcanic Islands"세대에서 문제가 시작된다. 따라서 GPU 벤더는 하이엔드 공정을 전환하지만, 하위 라인업은 28nm의 사용을 계속한다 말한다.
참고로, 공정 미세화에 선행하는 Intel은 어떤가. Intel도 아래와 같은 슬라이드에서 현재 포커스가 비용 스케일링에 있다고 지적하고 있다.

Intel의 Jefferies TMT Conference에서 슬라이드
그러나 Intel은 자사의 공정에 대해서는 트랜지스터 비용 절감은 순조롭게 진행되고 있어 향후 14nm나 10nm에서도 비용 절감이 계속 된다고 설명했다. 아래는 5월 London Analyst Summit의 슬라이드다. 이것을 보는 한, Intel에 대해서는 비용 스케일링 한계는 강 건너 불구경인 것으로 보인다.
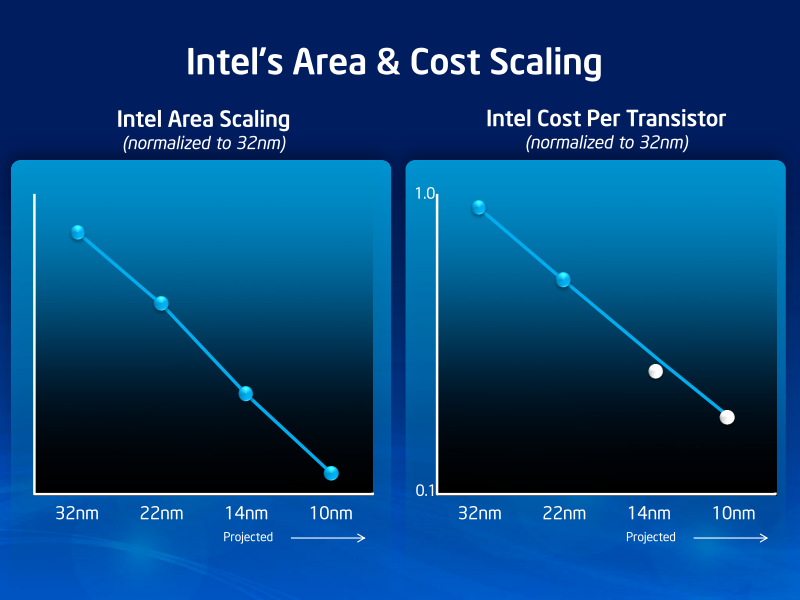
Intel의 London Analyst Summit에서 슬라이드
트랜지스터당 비용은 스케일링 팩터 및 웨이퍼당 비용, 거기에 수율로 결정된다. 만약 Intel의 22nm 수율이 극적으로 양호하다면, 당연히, 22nm 트랜지스터당 비용도 내려 간다. 비슷한 수율을 예측한다면 그 뒤에도 떨어진다. 또한 Intel의 경우 이 비용 예측에 450mm 웨이퍼로의 전환도 포함하고 있을 수 있다. 지금의 스케줄이라면 10nm 세대 정도에서 450mm로 바뀌기 시작하기 때문이다.
450mm 웨이퍼의 대구경화에 의해 상쇄하기
지금까지 반도체 산업은 실리콘 웨이퍼를 대구경화 하는 것으로, 코스트 다운을 측정해 왔다. 이번에도 그것을 다시 반복하자 라는 움직임이 활발해지고 있다. 현재 주류 웨이퍼 직경 300mm를 450mm로 1.5 배하면 1 매의 웨이퍼에서 제조 할 수 있는 칩의 수와 트랜지스터 수가 최대 약 2.2 배로 늘어난다. 그러나 웨이퍼당 비용은 숙련되어 가면 2배로 늘뿐 (보통) 1.x 배로 된다. 따라서 칩당 또는 트랜지스터당 비용은 웨이퍼의 대형화로 감소하게 된다. 이것이 웨이퍼의 대구경화의 논리다.
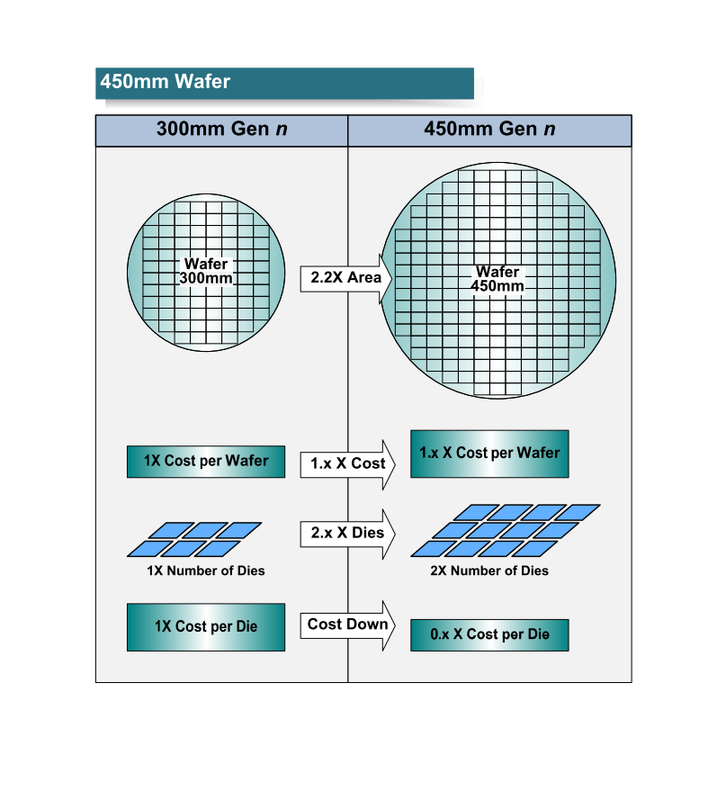
300mm에서 450mm 웨이퍼로의 전환
그 말대로라면 웨이퍼를 450mm로 확대하면 미세화의 트랜지스터 비용의 상승을 어느 정도 상쇄할 수 있게 된다. 칩 벤더는 코어의 아키텍처를 강화하려 트랜지스터를 써버려도 비용이 급증하지 않는다. 지금 그대로의 아키텍처와 기능 강화를 계속할 수 있다.
그러나 450mm 웨이퍼로의 전환은 심한 통증을 동반하기 때문에 결코 좋은 얘기만은 아니다. 먼저 Fab의 도구는 450mm 대응의 새것에 바뀌고, Fab의 웨이퍼 이송 시스템 등도 모두 바꾸게 된다. 전반적으로, Fab에 대한 투자가 팽창하게 된다. 가뜩이나 Fab에 대한 투자가 공정 세대마다 증가하고 있는데, 추가 투자가 팽창하는 것은 반도체 제조업체들에게 엄청난 부담이다.
따라서 투자에 걸맞는 매출을 전망할 수 있는 메이커가 아니면 450mm를 단행하기 어렵다. 하지만 450mm로 전환하는 업체가 트랜지스터당 비용에서 우위에 서 버린다면, 450mm로 단행하지 않으면 살아남을 수 없다. 엄청난 투자를 감행한 치킨 레이스에서 반도체 메이커는 결단이 강요된다.
이전 300mm 웨이퍼로의 전환은 웨이퍼의 대구경화에 추종 할 수 없는 반도체 메이커가 떨어졌다. 이번에도 450mm로의 전환에서 Intel은 반도체 메이커를 (격차를) 떨어뜨림도 계획에 있는 것으로 말해진다. 체력이 있는 거대 메이커만이 생존하는 게임이다.
다시 파운드리도 다리가 절단되는 탈락반과 헤어나는 길이 갈라지는 가능성이 나온다. 그렇게 되면, 팹리스 CPU나 GPU, SoC를 최첨단 공정으로 제조하는 파운드리가 더 적어질 가능성도 있다. 다만 450mm에 발 맞춤은 결코 갖추어져 있다고는 말하지 못하고, 어떤 전개 될지 아직 끝까지 읽을 수 없는 부분이 있다. Intel 관계자는 "450mm를 할지 말지 논의는 벌써 끝나 있고 의견 일치가 됐다."고 말하지만, 반도체 메이커의 온도 차이는 꽤 크다.
[분석정보] DDR4는 어떻게되나? 인텔의 메모리 전략을 예측
[분석정보] JEDEC이 "DDR4"와 TSV를 사용 "3DS" 메모리 기술의 개요를 밝힌다.
[분석정보] 하스웰 eDRAM에 JEDEC 차세대 DRAM으로 대항하는 AMD의 메모리 전략
[분석정보] IDF 2013 베이징 전시장 및 기술 세션에서 새로운 기술에 주목한다.
[분석정보] 엘피다 메모리의 한계는 DRAM 종언의 상징?
[분석정보] 20나노 공정부터 앞으로 무어의 법칙의 의미가 없어지나? ~ 트랜지스터당 비용 상승
[분석정보] 정체를 보인 Haswell의 eDRAM 솔루션
[분석정보] 반도체 공정 한눈에 알기 인텔의 14nm가 늦는 이유
[분석정보] 왜 NVIDIA의 Maxwell은 28nm이고 Apple의 A8은 20nm 공정인가
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] IBM이 기술의 집대성 괴물 CPU Power8 발표 (0) | 2013.08.28 |
|---|---|
| [분석정보] 고속화와 함께 전력 절약에도 눈 돌리는 PCI Express 3.1 (0) | 2013.08.26 |
| [분석정보] 스몰 코어 마이크로 서버로 기우는 Intel의 서버 전략 (0) | 2013.07.30 |
| [분석정보] 부드러운 데이터 센터를 만드는 Intel의 Software Defined Infrastructure (0) | 2013.07.30 |
| [분석정보] 인텔 하스웰 설계를 행한 마레이시아 제조 개발 거점을 공개 (0) | 2013.07.08 |
| [분석정보] 하스웰 eDRAM에 JEDEC 차세대 DRAM으로 대항하는 AMD의 메모리 전략 (0) | 2013.07.08 |
| [분석정보] AMD의 차세대 APU Kaveri (카베리)는 아키텍처의 전환점 (0) | 2013.07.05 |
| [분석정보] Research @ Intel 2013 Direct Compressed Execution 등을 시현 (0) | 2013.06.30 |