2014년은 서버에 요구되는 기능이 크게 달라 보인다. 이것은 서버가 사용되는 장면이 변하기 시작하는 것에 유래한다. 선진 기업에서는 기존의 IT 시스템뿐만 아니라 빅 데이터 등 지금까지 전혀 없었던 용도의 서버가 이용되기 시작하고 있다.
이번에는 기존의 엔터프라이즈 Xeon과는 다른 컨셉을 가진, Xeon Phi를 중심으로 2014년에 등장하는 Intel 제품을 해설해 나간다.
또한 반도체 공정 기술 자체가 큰 모퉁이에 접어 들고 있다는 점도 또 다른 큰 주제라고 할 수 있다. 공정의 미세화에 상당한 투자가 필요할 Intel 플랫폼에서도 지금까지의 방침을 전환하고 파운드리(타 회사 반도체를 찍어주는) 서비스의 제공을 확대하는 것 이라고 한다. 기사의 뒷부분에서는 이 점에 대해서도 설명한다.
병렬 컴퓨팅을 위한 보조 프로세서 Xeon Phi
Xeon Phi는 Intel Many Integrated Core (MIC) 아키텍처를 채용한 병렬 컴퓨팅 용 프로세서다.
NVIDIA와 AMD가 GPU를 이용한 GPGPU 카드를 출시해, HPC 등 많은 연산을 필요로하는 분야에서 적극적으로 채용되고 있다. 이러한 트렌드를 Intel 자체도 놓칠 수 없기 때문에 Intel 플랫폼 판 병렬 컴퓨팅을 위한 프로세서로서 Xeon Phi를 출시했다.
Xeon Phi의 가장 큰 특징은 코어가 Pentium 기반의 x86 프로세서 + 512 비트 벡터 연산 기능이 있는 것이다. 이 코어를 60개 정도 탑재하여 병렬 컴퓨팅에서 높은 성능을 실현하고 있다.
22nm 공정으로 제조된 Xeon Phi 7120P는 1.238GHz 작동 (터보 모드 동작시 1.33GHz) 코어를 61개 내장하고 있다. 메모리는 8GB (DDR5)를 탑재, 배정밀도 부동 소수점 연산 성능은 약 1.2TFlops.
이 제품을 비롯해 현재의 Xeon Phi 다른 프로세서의 코 프로세서로 작동하기 때문에 PCI Express 카드로 볼 수 있으며, Xeon E5 등의 범용 프로세서와 함께 사용된다.
Xeon Phi에서 재미있는 것은, x86 코어에서 Linux OS를 독립적으로 움직여 병렬 컴퓨팅 프로그램을 처리 할 수 있는 것이다. 따라서, Xeon Phi 자체가 OS를 가지고 동작하는 것은 NVIDIA 나 AMD의 GPGPU와는 크게 다르다.
또한 코어는 x86 아키텍처를 이용하고 있기 때문에, GPGPU 처럼 자신의 프로그래밍 언어로 프로그램을 작성하는 것이 아니라 현재 이용하고 있는 x86 프로그래밍을 그대로 이용할 수 있다는 점도 큰 장점이다.
그러나 모든 x86 프로그램이 Xeon Phi에서 달리는 경우 성능이 오르는 것은 아니다. 역시 병렬 컴퓨팅 용으로 개발된 프로그램을 Xeon Phi 용으로 재 컴파일 할 필요가 있다. 실제로 Intel에서는 기존의 Xeon 용의 C / C + + 프로그래밍에 대한 컴파일러를 Xeon Phi에 대응시키고, Xeon Phi 환경에서 가장 효율이 높아지도록 하고 있다.

2012 ~ 2013 년에 제공한 Xeon Phi (개발 코드 명 : Knights Corner)는 PCI Express 카드로 볼 수 있었다. 배정밀도 부동 소수점 연산 성능으로 1TFlop을 실현하고 있다
CPU가 되는 Xeon Phi
11월 말에 미국에서 개최된 슈퍼 컴퓨터에 대한 컨퍼런스 "International Supercomputing Conference 13 (SC13)"'에서 Intel은 14nm 공정으로 제조하는 차세대 Xeon Phi (개발 코드 명 : Knights Landing)에 관한 발표가 있었다.
2014년에 출시될 Knights Landing 세대는 종래와 같은 PCI Express 카드만이 아닌 메모리와 인터페이스를 탑재한 패키지도 제공된다고 한다.
구체적으로는 프로세서 칩과 전송 속도가 빠른 고 대역 메모리를 MCM (멀티 칩 모듈)으로 포장. 또한 패키지 외부에 대용량의 외부 메모리 (통합 메모리보다 대기 시간이 긴)를 탑재한다. 프로세서 코어의 가까운 부분에 빠른 메모리를 배치하는 것으로, Xeon Phi 자체의 성능이 올라간다.
미래에는 내부의 고 대역 메모리는 더욱 쌓아 높이 방향으로 연장에서 (적층 메모리 : 2.5D 메모리) 대용량화도 검토되고 있다.
이러한 개량에 의해, Knights Landing은 배정밀도 부동 소수점 연산 성능으로 3TFlops에도 성능이 향상한다고 한다.
Knights Landing에 관해서는 지금까지 Xeon Phi에서 사용된 Pentium 기반의 코어가 아니라 2013년에 발매된 Atom Silvermont 코어가 사용될 것으로 예상된다.

Knights Landing 에서는 카드의 제공이 아니라 1칩화

Knights Landing은 MCM으로 패키지 내부에 고 대역의 메모리와 프로세서가 담겨있다
이 Knights Landing을 이용하는 경우에는 보조 프로세서가 아닌 일반 프로세서로 시스템을 구축 할 수 있기 때문에, Xeon E5 등의 CPU를 별도로 준비하지 않아도, Knights Landing 만으로 서버를 구성 할 수 있다.
그러나 일반 Xeon 같은 범용 프로세서가 아니기 때문에, 역시 모든 응용 프로그램이 높은 성능으로 움직이지는 않는다. Xeon Phi (Knights Corner)는 Atom (Silvermont 코어) 기반이라고 예상되므로 엔터프라이즈에서 사용하는 데이터베이스 등의 애플리케이션을 가속화하는 것은 어려울 것이다.
이러한 점을 감안할 때, Knights Landing만으로 구성되는 서버, 블레이드 서버 등의 형태로 고밀도 섀시에 탑재되어 수천 수만 프로세서로 구성된 HPC 시스템으로 이용되지 않을까?
또한 Intel은 Knights Landing 대해 적층 메모리로 부터 내부 메모리의 대용량화 이외에 패브릭 스위치 차세대 스토리지 인터커넥트 등을 탑재할 예정이다.
또한 향후 고객의 요구에 따라 맞춤형 버전의 Knights Landing의 제공도 계획하고 있다. 예를 들어, 내부의 고 대역 메모리 대용량화 하거나 상호 연결 InfiniBand를 탑재하거나와 같은 커스텀화가 있을 수 있다고 한다.
여담이지만, GPGPU 측에서도 다음의 대처가 진행되고 있다. NVIDIA는 CES2014에서 Tegra K1을 발표했다. Tegra K1, GPU 부분에는 Geforce600 시리즈로 채용된 Kepler 아키텍처의 코어를 사용하고 있다. 따라서 Tegra K1의 GPU 코어는 192 코어로 크게 증가하고 있다 (Tegra 4에서 72 코어였다.)
또한 차이가 큰 것은 CPU 코어인 것이다. Tegra K1은 2개의 CPU 코어 제품이 계획되어 있다. 2014년 상반기에는 32비트 Cortex-A15 (4 코어 +1 코어)를 채용한 제품이 출시된다. 또한 올해는 NVIDIA가 ARM 64 비트 아키텍처 ARMv8을 기반으로 독자 개발 한 Denver 코어 (2 코어)을 탑재한 SoC를 계획하고 있다.
특히 Denver 코어는 ARM이 개발한 64 비트 Cortex-A57/53 보다 성능을 추구한 구조로 되어있는 것 같다. 따라서 HPC 분야의 적응을 시야에 넣고있다.
차세대 Xeon E7이 등장 예정, Xeon E5의 새로운 변형
서버 전용의 하이 엔드 프로세서로 출시되는 Xeon E7 시리즈는 Ivy Bridge 세대의 새로운 Xeon E7 (개발 코드 명 : Ivy Bridge-EX)가 2014년에 등장 할 전망이다. 기존에는 2013 중에 출시가 예정되어 있었지만, 일정이 어긋난것 같고, 곧 등장 할 것으로 보인다.
현재 Xeon E7은 마이크로 아키텍쳐가 Westmere 세대 (제조 공정은 32nm)이며, 메인 스트림 서버용 Xeon E5가 Ivy Bridge 세대인데 비해 2세대 이전. 따라서 기업의 기간 시스템 서버를 제공하는 서버 벤더로는 Ivy Bridge 세대와 더 새로운 세대의 프로세서를 기대하고 있었다.
한편, Xeon E5에서도 2014년에 새로운 라인업이 발표되고 있다. 2013년에는 메모리 채널을 4개 가진 Xeon E5-2600v2 (주로 2 소켓 전용) 시리즈와 Xeon E5-1600v2 시리즈 (1 소켓 전용)의 Ivy Bridge 세대의 2개의 라인 업이 등장하고 있다 하지만 이 외에도 2014년 1월에는 메모리 채널이 3개의 Xeon E5-2400v2 시리즈가 발표되었다. 기본적으로, Sandy Bridge 세대였던 Xeon E5-2400 시리즈의 업데이트 버전이다.
또한 Xeon E5는 Ivy Bridge 세대는 아직 제공되고 있지 않지만, 4소켓 용 Xeon E5-4600 시리즈는 제품도 존재하고 있기 때문에 총 4가지 변형이 존재하게 된다.
이렇게 라인업 된 배경에는 Sandy Bridge 세대 전에 AMD의 Opteron 점유율을 늘린 때문에 그것에 대항하는 것 이있다. 또한 전술한 바와 같이, 하이 엔드 Xeon E7 시리즈의 리프레쉬가 상당히 진행되지 않아서 잠정적으로 Xeon E5 시리즈의 라인업을 늘린 것도 있을 것이다.
단지 Intel의 방침을 보면, Haswell 세대에서는 조금 라인업이 변경될 가능성도 있다고 생각하고 있다.
Sandy Bridge 세대와 Ivy Bridge 세대는 서버에서도 동일한 소켓이 사용되고 있었기 때문에, 서버 벤더 측의 대응도 그리 어려운 것은 없었다. 한편, Haswell 세대 이상에서는 소켓의 핀이 변하기 때문에 서버 벤더도 Haswell 세대에 대한 대응을 다시 추진할 필요가 있다.
이러한 상황을 고려하면 개인적으로 나는 4 종류의 라인업은 종류가 너무 많은 것 같다. 현재는 서버 시장에서 AMD의 Opteron의 영향력은 크게 줄어들고 하이 엔드 Xeon E7 시리즈도 리프레쉬의 목표가 섰다. 이런 것을 생각하면, Haswell 세대의 Xeon E5는 라인업이 정리된다고 예측하고 있다.
또한 실제로 Haswell 세대의 Xeon E5 출시되는 것은 2015년에서 2016년이 될 것이다.
다양한 계층과 용도로 프로세서를 제공
Intel은 Xeon, Xeon Phi, Atom 등의 프로세서를 다양한 계층과 용도로 사용할 수 있도록 나아갈 계획이다. 범용 프로세서 Xeon 병렬 컴퓨팅 Xeon Phi 등을 InfiniBand 패브릭 및 실리콘 포토닉스에 연결하고 데이터 센터 전체 x86 기반 컴퓨팅 환경을 실현하려고 생각하고 있다.
NVIDIA와 AMD는 X86과 ARM 같은 프로세서와 GPU를 결합한 이기종 컴퓨팅을 계획하고 있지만, Intel은 X86을 모든 영역으로 확대해 나가는 것으로, x86 기반의 프로그램 자산을 살려 가려고 생각하고 있다.
또한 HP의 Moonshot 이나 AMD의 SeaMicro 등으로 주목을 받았던 MicroServer 분야에서는 Atom 프로세서를 이용해 가려 하고 있다. 서버 전용의 Atom 프로세서로 차세대 Atom 아키텍처를 채용한 Denverton 이 계획되어 있다. Denverton는 Airmont 아키텍처, 14nm 공정으로 제조된다. 따라서 약간 일정이 늦어지고 있는 것 같다. 출시는 2014년 4분기 또는 2015년에 들어가는 것이다.
서버 전용의 Atom 프로세서는 MicroServer 분야뿐만 아니라 Software Defined Network (SDN)을 실현하기 위한 네트워크 스위치, 스토리지 시스템 등에 이용되는 것이다.

클라우드의 등장으로 프로세서의 수요가 높은 성장을 보여준다. 앞으로도 이러한 경향은 계속

Intel에서는 엔터프라이즈 분야에서는 용도에 따라, Itanium Xeon, Xeon Phi, Core i5, Atom 등이 이용된다

워크로드에 맞게 서버, 스토리지, 네트워크 등의 Intel 프로세서가 사용된다. 일부 기업은 Intel 프로세서를 맞춤(커스텀) 제공하고 있다. 앞으로는 Rackscale 아키텍처에 따른 데이터 센터를 구축해 나간다.
Compute 부분에서 커다란 전환점이 될 것이 Ethernet 또는 InfiniBand를 프로세서에 통합하는 흐름이다. 특히 InfiniBand 내용은 InfiniBand 칩이나 카드를 제공했던 Qlogic의 자산을 인수하여 True Scale 패브릭을 제공하고 있다. InfiniBand를 프로세서의 요소로 통합해 서버를 연결하는 패브릭으로 사용해 가려고 생각하는 것 같다.
또한 Intel은 이전부터 연구·개발하던 실리콘 포토닉스를 사용한 네트워크를 2014년 제공한다. 2014 년에 제품화 되는 실리콘 광자칩은 100Gbps 속도를 제공하며, 케이블 길이로는 800 미터의 장거리를 지원한다.
실리콘 포토닉스를 이용해 서버 랙 내부나 랙 사이의 네트워크를 고속화 할 수 있으므로 데이터 센터 자체의 성능을 올리는 것이 가능하게 될 것이다.
[분석정보] IDF 2013 베이징 Intel 프로세서에서 가능한 것은 Windows 만이 아니다
[분석정보] Research @ Intel 2013 Direct Compressed Execution 등을 시현
[분석정보] Research @ Intel 2012 리포트

향후 중요하게 되는 것은, 패브릭, 실리콘 포토닉스, 비 휘발성 메모리다

Intel은 Ethernet, InfiniBand를 프로세서에 통합 할 예정

서버 및 랙 간의 네트워크로 실리콘 포토닉스를 이용한다. 100Gbps 속도의 케이블을 수백 미터로 연장 할 수 있다
파운드리 서비스를 일반제공
또한 SC13 직후에 개최 된 Intel의 투자자 컨퍼런스에서 새로 CEO가 된 브라이언 크르자니크 씨가 Intel의 반도체 공장의 파운드리 서비스 제공을 확대한다고 발표했다.
Intel은 FPGA 업체 등 일부 제조 업체의 칩을 제조하고 있다. 하지만 TSMC 같은 다양한 메이커의 칩을 받아들이지 않고 한정된 칩 생산만 하고 있었다. 그러나 이번 발표에서는 어떤 기업에 대해서도 Intel의 최첨단 반도체 제조 기술을 이용한 파운드리 서비스를 제공하고 있다.
Intel에서는 엄청난 수의 iPhone과 iPad 등을 제공하는 애플에서 프로세서의 제조를 하청하고 싶은지도 모른다.
이러한 전략으로 꺾은 배경으로 10nm 반도체 공정의 개발· 운용이 엄청난 금액이 드는 것을 꼽을 수 있다. 실제 반도체 제조 장비를 다루는 도쿄 일렉트론과 어플라이드 머티리얼즈의 경영 통합의 큰 원인으로 차세대 반도체 제조 장치의 개발에 막대한 금액이 드는것이 지적되고 있었다.
이런 것을 생각하면, 10nm 이후의 반도체 제조에 엄청난 칩을 제조하는 Intel에 있어서도 제조 비용이 뛰게 될 것이다. 최첨단 반도체 공장을 계속 유지 할 수 있도록 다양한 수요를 받아들이기 때문에 자사 칩의 제조 비용도 절감 할 수 있는 것은 아닐까 라고 생각하고 있는 것 같다.

Intel의 반도체 제조 공정은 다른 파운드리 보다 먼저 실시하고 있기 때문에, 파운드리 서비스로는 큰 어드밴티지가 있다

Intel의 파운드리 서비스는 단순히 반도체 제조 공장뿐만 아니라 지금까지의 프로세서 설계, 제조에서 축적해 온 각종 도구 등을 사용할 수 있다.
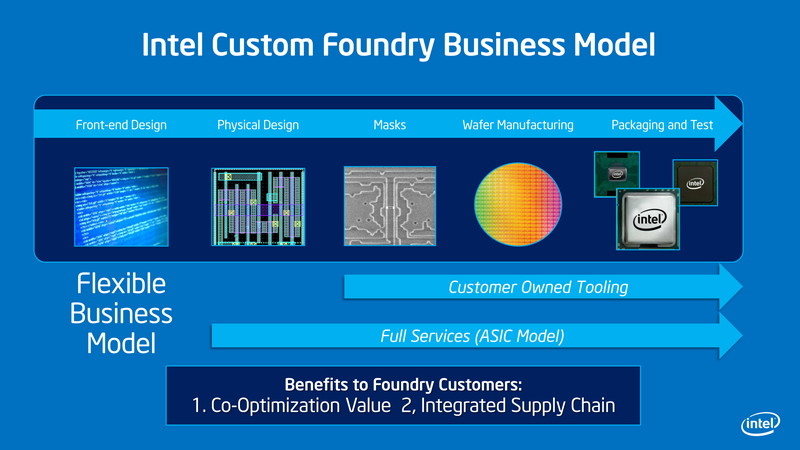
Intel의 파운드리 서비스는 모든 기업에 유연한 서비스를 제공
[분석정보] 아이테니엄(Itanium)을 둘러싼 불안과 기대
[제품정보] Intel Xeon Phi 새로운 폼 팩터 채용 포함 5모델 추가
[분석정보] IDF13 San Francisco에서 보는 2014년의 서버용 프로세서
[분석정보] Intel, Ivy Bridge-EX Xeon E7 v2 패밀리.최대 15코어 CPU 메모리 용량은 최대 1.5TB
[분석정보] 드디어 등장한 최상위 x86 서버 프로세서, 아이비브릿지 세대 제온 E7 v2 시리즈
[분석정보] 인텔 HPC 시스템 Scalable System Framework 소개
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] Intel이 ISSCC에서 15 코어 Ivytown과 Haswell의 FIVR 기술 등을 발표 (0) | 2014.02.13 |
|---|---|
| [분석정보] ARM 서버는 어디에 사용될 것인가? (0) | 2014.02.12 |
| [분석정보] AMD Kaveri의 메모리 아키텍처와 향후의 APU 진화 (0) | 2014.01.29 |
| [분석정보] 카베리와 최근 인텔 AMD 칩의 부동소수점 피크 성능 (0) | 2014.01.25 |
| [CES 2014] Intel의 SD 카드 형 컴퓨터 "Edison" (0) | 2014.01.17 |
| [CES 2014] Steam Machine 을 일제히 전시 (0) | 2014.01.17 |
| [CES 2014] AMD 차기 APU "Kaveri"의 개요 및 성과를 공개 (0) | 2014.01.14 |
| [CES 2014] ASUS Windows,Android 쌍방 동작 4-in-1 노트 (0) | 2014.01.14 |