좁히는 Intel의 Larrabee에 대응을 서두르는 NVIDIA의 CUDA 전략
Intel은 데이터 병렬 + 태스크 병렬형 프로세서인 "Larrabee (라라비)"의 준비를 진행하고 있다. 올 여름 아키텍처의 개요를 분명히 하고 내년 (2009년)에는 제품 출시 예정이다. Intel은 당초 Larrabee를 고성능 컴퓨팅 (HPC)용으로 설명을 하고 있었지만, 실제로는 그래픽 제품에 투입한다. 이것은 NVIDIA가 그래픽 카드로 볼륨을 출하해 범용 컴퓨팅에도 사용할 수 있는 프로세서를 보급시키는 전략을 답습하는 것이다.
Intel은, 실은 Larrabee 전략의 처음부터 그래픽 제품으로 보급할 계획이었다. 즉, 그래픽 제품으로 전략을 전환한 것이 아니라 처음부터 그래픽으로 판매 계획이었다. 그러나 GPU 벤더를 경계시키지 않기 위해 처음에는 연막을 쳐, Larrabee는 HPC 용으로 강조하고 있었다고 한다. 이 코너에서도 Intel이 Larrabee 전략을 전환 것처럼 써 왔지만, 그것은 실제로는 Intel의 홍보 전략에 실려 있던 것이다.
Intel은 최초 버전의 Larrabee를 투입하는 즉시 (공정) 수축 버전의 Larrabee 2를 투입. 이 세대는 노트 PC에도 GPU로 올리려고 계획하고 있다고 한다. 즉, Larrabee를 완전히 GeForce 대항으로 투입하는 의도이다.
이러한 Intel의 압박 때문에, NVIDIA는 엉덩이에 불이 붙은 상태다. NVIDIA가 GPU의 범용적인 이용 형태인 GPU 컴퓨팅으로 매진하는 것은 Intel이 따라잡기 전까지, GPU 컴퓨팅의 입지를 굳히고 싶기 때문이다. 따라서 GPU 컴퓨팅 프레임 워크인 "CUDA (쿠다 : compute unified device architecture)"의 보급에 포커스 한다. 하지만 NVIDIA에 있어서, 이것은 어려운 길이다.
NVIDIA는 CUDA가 다양한 분야에 침투하고 있다고 강조. 사실, CUDA는 HPC 등의 분야의 일부에서 환영되고 일정한 성과를 올리고 있다. 그러나 실태는 CUDA가 널리 퍼져 있다는 페이즈에는 아직 멀다.
성능 최적화가 어려운 GPU 컴퓨팅
CUDA에 도전한 프로그래머들의 일부는 CUDA로 GPU의 성능을 끌어내는 프로그램을 짜는 것은, 일부의 사람 정도라고 지적한다. CPU와는 다른 다양한 성능 병목이 기다리고 있기 때문이다. 따라서 단지 CUDA 코드를 이식하는 것만으로는 GPU의 스펙에 맞는 성능을 내는 것은 어렵다고 말한다.
CUDA가 등장하고 부터 아직 그렇게 시간이 지나지 않은 지난해 (2007년) 8월의 CPU 컨퍼런스 "HotChips 19" 에서는 NVIDIA의 협력을 얻어 CUDA 프로그래밍 과정을 개설 한 일리노이 대학이 학생들의 프로그래밍에 대한 결과를 발표했다. 그것을 보면 성능이 크게 오르는 것도 있고, 그렇지 않은 것도 있어, 상당한 차이가 있었다. NVIDIA의 David B. Kirk (데이비드 B 커크) 씨 (Chief Scientist)는 그 결과에 대해 "병렬 컴퓨팅 알고리즘에 아직 프로그램을 작성하는 측이 익숙하지 않기 때문"이라고 설명했다. GPU 컴퓨팅에 최적인 알고리즘에 아직 친숙하지 않아서 성능을 발휘하지 못하는 경우가 나온다는 것이다.
그로부터 1년, CUDA 프로그래밍 커뮤니티는 일정한 확산을 보여, 응용 프로그램도 등장하고 매우 높은 성능을 달성하고 있는 것도 있다. 하지만 그래도 NVIDIA CUDA에 최적화가 어렵다는 비판이 붙어 다니고 있다. NVIDIA의 GT200 세대인 "GeForce GTX 200"과 "Tesla T10P"는 그러한 문제에 대해 NVIDIA가 어느 정도의 해답을 낸 것이다.
범용 컴퓨팅의 병목을 하드웨어로 해결
NVIDIA의 CUDA가 최적화가 어려운 것은 GPU 특유의 아키텍처 상의 병목이 있기 때문이다. 하드웨어를 은폐하는 프로그래밍 모델 때문에 문제가 보이지 않는 것도 있다. 그러나 하드웨어 자체가 아직 범용적인 컴퓨팅에 충분히 최적화되어 있다고는 말하기 어려운 것도 확실하다.
HotChips 19에서 지적된 병목은 레지스터나 비디오 메모리 액세스 지연 시간, 공유 메모리 (Shared Memory) 용량, 명령 발행 레이트 등. 단독(외장) GPU의 숙명인 CPU와 GPU 간의 데이터 전송 병목도 있지만 대부분의 경우는 GPU 측에서 아키텍처 상의 병목이 차지하고 있는 것을 알 수있다.

HotChips에 표시된 GPU에 의한 각 응용 프로그램에서 성능 향상의 정도
HotChips에 표시된 GPGPU 응용 프로그램 작성시 주의 사항
NVIDIA는 지난해 11월 미국 프린스턴에서 개최된 천문학 및 천체 물리학에서의 GPU의 응용 컨퍼런스 "AstroGPU 2007"에서 CUDA의 최적화의 포인트를 설명했다. 거기서 NVIDIA가 든 것은 레지스터의 부족에 의한 멀티 스레딩 제약 등 "레지스터 압력 (Register Pressure)"메모리 액세스의 비 효율화를 초래하는 "비결합 메모리 액세스 (Non-Coalesced Memory Access)" 여기에 GPU 내부에 갖춘 스크래치 패드 메모리에서 "공유 메모리 뱅크 충돌 (Shared Memory bank conflicts)"등이다.
AstroGPU에 표시된 레지스터 압력의 문제
AstroGPU에서 나타난 비결합 메모리 액세스 문제

AstroGPU에 표시된 뱅크 충돌 문제
AstroGPU는 NVIDIA 아키텍처 상의 이러한 문제를 들어 올리고 그것을 피해 최적화 하는 방법을 표시 했을 뿐이다. 즉, 그 시점에서 하드웨어 개량이 아니라 프로그래머 측의 노력으로 문제를 피해 달라는 접근이었다. 이때 프레젠테이션만 보면 NVIDIA는 하드웨어를 보다 범용 컴퓨팅을 위해 개량하는 것을 피하고 프로그램 측에 부담을 떠넘기려고 하는 듯 보였다.
그러나 지난달 명확해진 GT200 에서는, NVIDIA는 AstroGPU에서 지적한 몇 가지 문제를 하드웨어로 해결했다. 이것은 NVIDIA가 앞으로도 범용 컴퓨팅에 병목 부분은 점차 하드웨어를 개량하는 것으로 해결해 가려는 것을 보여주고 있다.
레지스터 수와 멀티 스레드의 트레이드 오프
GPU의 성능을 끌어 내려고 하면 GPU의 연산 자원을 최대한 풀 가동시켜야 한다. 실행 파이프 라인이 메모리로 부터 데이터 대기나 리소스 경합으로 멈추는 것을 최대한 줄일 필요가 있다. 여기서 문제가 되는 것은, 전통적인 그래픽스 태스크와 비 그래픽의 범용적인 태스트는 프로그램의 동작이 다른 것. 그때문에 전통적인 GPU와는 다른 아키텍처상의 궁리가 필요하다.
그러나 여기에는 트레이드 오프가 있다. 범용 컴퓨팅을 위해 자원을 할애하면 반면에, 상대적으로 그래픽에 유용한 리소스를 억제하지 않으면 안된다. 양자를 세우려고 하면 GPU 자체가 거대하게 되어 버린다.
무엇보다,이 문제는 약간 모호한 부분이 있다. 그래픽도 쉐이더 프로그램 중심이 되어, 쉐이더 프로그램이 복잡해 짐에 따라 전통적인 그래픽로 부터 벗어나 부분적으로 범용 컴퓨팅과 비슷한 특징을 갖게 되었다. 따라서 일률적으로 그래픽 기능 대 범용 컴퓨팅 기능과 대비는 없다.
GT200 프로세서 코어 안에서 NVIDIA가 개혁한 큰 포인트의 하나는 범용 레지스터의 두배 증가다. 이 확장은 GPU 컴퓨팅 성능을 끌어 메모리 지연 시간을 은폐하는 데 큰 효과가 있다.
GPU는 일반적으로 물리 레지스터와 프로그램 측 (또는 중간 언어)에서 보이는 논리 레지스터가 분리되어 있다. 현재 CPU 다수가 행하고 있는 논리 레지스터를 CPU 내부의 물리 레지스터에 매핑하는 "레지스터 리 네이밍"과 다소 비슷하다.
GPU는 우선, 쓰레드 당 레지스터 수의 할당은 고정되어 있지 않다. GPU는 프로그램이 드라이버 소프트웨어의 런타임 컴파일러에서 GPU의 네이티브 명령어로 변환 할 때 할당 레지스터 수를 결정한다.(실제의 물리 레지스터에 매핑은 GPU 측에서 행하는 경우가 많다). 하지만 GPU가 갖춘 물리적 레지스터 수는 정해져 있다. 따라서 스레드 당 레지스터 수와 시작할 수 있는 스레드 수에는 트레이드 오프가 생긴다.
"각 스레드마다 전용의 레지스터 공간을 가지고 있지만 고정되어 있지 않다. 따라서, 시동 스레드 수가 증가하면, 1 스레드가 사용할 수 있는 레지스터 수가 줄어든다.이 2 개는 트레이드 오프의 관계에 있다"고 David B. Kirk 씨는 설명한다. 1 스레드 당의 레지스터 수가 증가하면 스레드 수가 줄어 버리게 된다.
이 구조는 현재의 멀티 스레딩 GPU에 공통된 특징이다. 따라서 컴파일러에 의한 스레드에 대한 레지스터 할당이 성능을 크게 좌우한다. 예를 들면, Xbox 360의 초기 단계에서는 Microsoft 컴파일러는 내보내는 GPU 네이티브 코드가 대량으로 물리 레지스터를 사용해 버렸다. 따라서 스레드의 최대 수까지 시작되지 않고, GPU 파이프 라인이 아이들 되는 조건이 발생 했다고 한다. 그 후, Xbox 360에서는 컴파일러 측의 개혁을 통해 멀티 스레딩을 향상시키고 쉐이더 성능이 올라가는 현상이 되었다.
전통적인 그래픽은 그다지 범용 레지스터를 필요로 하지 않기 때문에 이전의 NVIDIA GPU는 레지스터가 매우 적었다. 그러나 범용 컴퓨팅 된다면 이야기가 달라진다. G80/GT200의 GPU 컴퓨팅 아키텍트의 John Nickolls 씨 (Director of Architecture)는 "GPU 컴퓨팅은 스레드 당 32개 범용 레지스터가 적절하다고 생각하고 있다"고 말했다. 일반적인 RISC (Reduced Instruction Set Computer) 프로세서와 동일한 수준 (그러나 GPU의 경우는 정수와 부동 소수점 레지스터의 구별은 없다) 범용 레지스터가 필요하다고 생각하고 있는 셈이다.
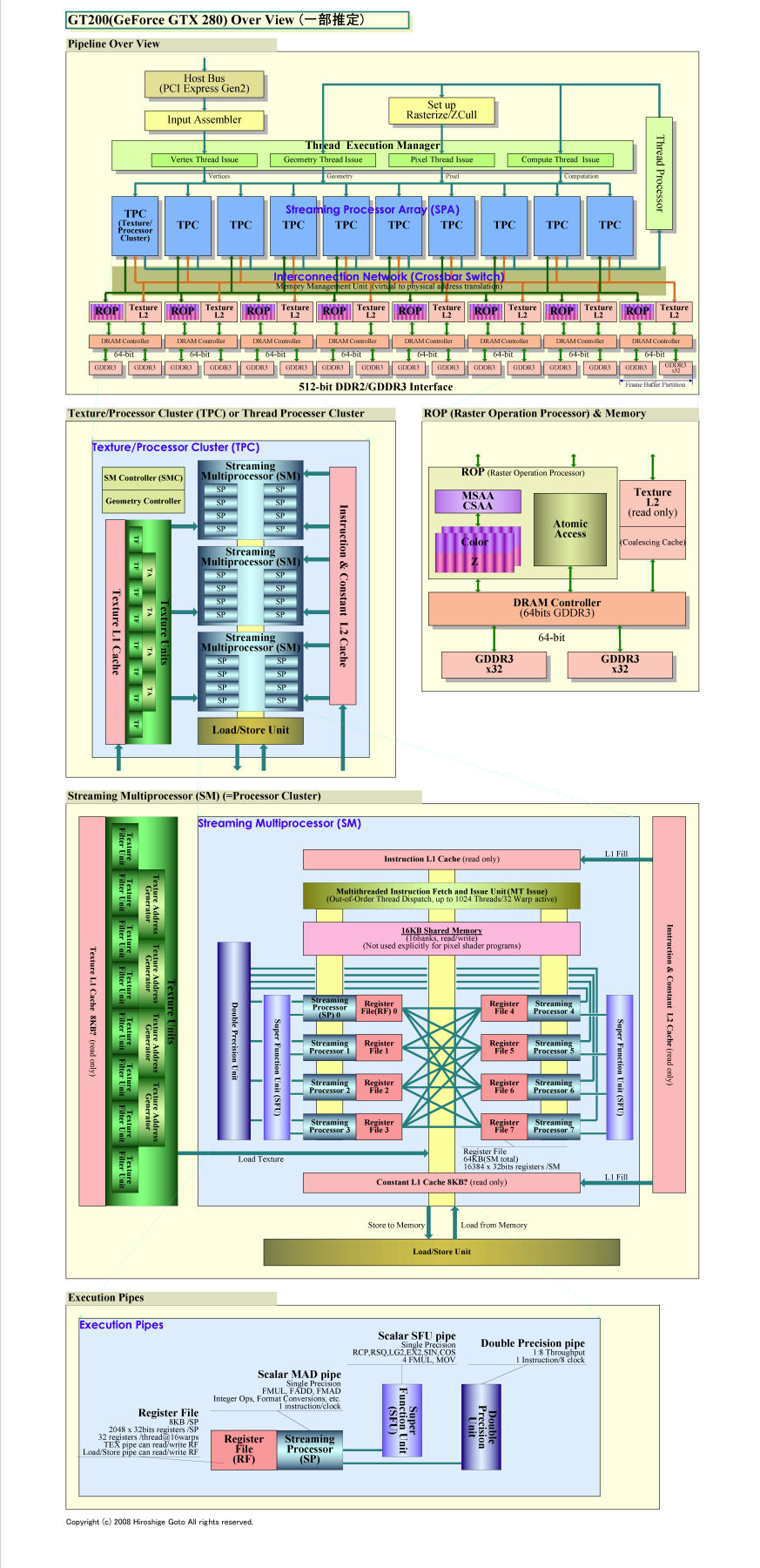
GT200의 개요 (일부 추정)
400 ~ 600 사이클 메모리 지연 시간을 은폐한다.
문제는 여기에 있었다. 1 스레드 당 레지스터 개수를 늘리면 시작할 수 있는 스레드 수가 줄어든다. 그러면 멀티 스레딩으로 은폐하고 있는 메모리 액세스 지연을 커버 할 수 없게 된다. GPU에 밖에 있는 비디오 메모리 액세스에는 시간이 걸린다. G80/GT200 계열에서는 최소 200 사이클 프로그래밍 가이드는 400 ~ 600 사이클로 되어있다.
G80/GT200이 32스레드로 구성된 스레드 배치 "warp"를 각 프로세서 클러스터 "Streaming Multiprocessor (SM)"안에서 4사이클에 걸쳐 실행한다. SM은 프로세서 "Streaming Processor (SP)"가 8개 탑재되어 있으며, 8병렬로 처리하기 때문에 4사이클 32 스레드를 처리 할 수있다.
G80에서는 Streaming Multiprocessor (SM) 당의 레지스터 수는 8,192 개 였다. 따라서 32 레지스터를 각 스레드에 할당하면 시작할 수 있는 스레드 수는 256 스레드가 된다. 쓰레드 배치인 warp 수는 단 8개다.
여기서 프로그램의 메모리 로드 명령어 다음에 로드에 의존하지 않는 명령이 평균 3 명령 계속되고, 8 warp가 각각 4사이클로 메모리 액세스하고 4명령 간격으로 의존 명령이 오기 때문에, 평균으로 128 사이클의 메모리 지연 시간 밖에 은폐 할 수 없다.
따라서 메모리 대기로 낭비가 생길 가능성이 크게 된다. 물론 프로그램에 따라 여러가지 조건이 다르기 때문에 일률적으로는 말할 수 없다. 실제로는,로드 명령에서 의존 명령까지 더 간격이 벌어지는 경우도 많을 것이다. 그러나 warp 수가 적어 질수록 스톨이나 파이프 라인 버블이 발생할 가능성이 높아진다. 또한 로드 명령 후, 의존하지 않는 명령을 더 많이 스케쥴 하려고 하면 명령 스케줄링이 더 복잡해진다.
G80의 경우 시작할 수 있는 최대의 활성 warp 수는 24 warp. 24 warp를 확보하면 4명령 간격의 메모리 액세스의 경우는, 평균 384 사이클도 은폐 할 수 있게 된다. 그러나이 경우 G80에서는 스레드 당 레지스터 수는 10 개가 되어 버린다. x86 수준의 거북한 레지스터가 된다. 네이티브 명령어가 레지스터 간 연산 중심인 것을 생각하면 이것은 어려운 것이다. (아래 링크한 글들을 이해하고 보시면 좋습니다.)

AstroGPU에 표시된 메모리 액세스 대기 시간에 대한 설명
레지스터를 2배로 늘려 메모리 레이턴시를 은폐
G80에서는 제한된 레지스터 개수 때문에 응용 프로그램에 따라 이 레지스터 압박 문제에 신경을 써야했다. 그것에 비해서, GT200에서는 레지스터 갯수가 16,384 개로 두 배로 늘어나 최대 활성 warp 수도 32 warp로 늘었다.
GT200은 메모리 로드 명령 후 로드에 의존하는 명령이 4명령 간격으로 나타난다고 하면, 1스레드 32레지스터를 할당한 경우 16 warp 256 사이클을 은폐 할 수 있다. 따라서 스레드 당 32 레지스터가 보다 현실적이 된다. 또한 맥스 32 warp의 경우에는 16 레지스터 / 스레드로 512 사이클을 은폐 가능하다.
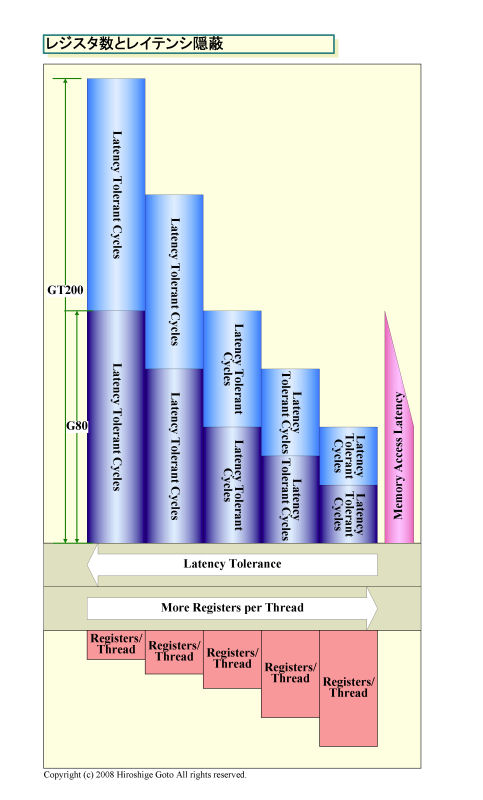
레지스터 수와 지연 은폐
GT200은 Streaming Multiprocessor (SM) 당의 레지스터 수의 두배 증가로 인해, G80과 비교해 레지스터 총량이 3배 이상 늘었다. G80에서는 512KB의 레지스터 였던 것이, GT200에서는 1.875MB로 증가했다. CPU의 캐시와 어느 정도 비슷하게 증가하는 방향이다.
CPU는 시리얼 태스크의 지연 시간을 은폐하기 위해 방대한 캐쉬를 필요로 한다. 대조적으로, GPU는 병렬 태스크에서 지연 시간을 은폐하기 위해 멀티 스레딩 자원으로 방대한 레지스터를 필요로 한다. 두 프로세서는 이렇게 나눠지고 있다.
참고로, 범용 레지스터는 AMD (구 ATI)도 마찬가지로 거대한 수를 쌓고있다. 원래는 ATI 아키텍쳐가 NVIDIA 보다 스레드 당의 레지스터 수가 많았다. ATI는 R6xx 제품군 때 이미 "DirectX 9에서는 스레드 당 16에서 아마 32의 GPR로 (범용 레지스터) 액세스 했다. 앞으로 더 될 것"이라고 지적했다. RV770은 연산 유닛 수가 R620 보다 많은, VLIW (Very Long Instruction Word)에 의한 명령 레벨의 병렬성을 살리기 위해, 보다 스레드 당 레지스터를 필요로 한다.
그리고 메모리 액세스 지연 시간을 은폐해야 하는 사정은 ATI 쪽도 마찬가지다. 다만 프로세서 코어의 동작 사이클 자체는 RV770 쪽이 GT200 보다 느리기 때문에 상대적으로 은폐해야 하는 메모리 레이턴시 사이클은 GT200 보다 적다. 그러나 연산 유닛 수가 많은 것으로 그것은 상쇄되는 것이다. ATI Radeon HD 4800 (RV770)은 MB 단위의 레지스터를 탑재하고 있다고 AMD는 설명한다.
메모리 액세스를 GPU 컴퓨팅용으로 개량
GT200에서 향상된 또 하나의 포인트는 메모리 액세스이다. 전통적인 그래픽스 태스크는 메모리 액세스는 결합 (Coalescing)되는 것을 전제로 한다. 우선, 각 프로세서가 SIMD (Single Instruction, Multiple Data)로 실행되므로 각 프로세서의 메모리 액세스 명령어는 모여있다. 그리고 많은 경우 인접한 픽셀용인 메모리상의 번지가 연속해 메모리 액세스 된다. 따라서 각 스레드의 메모리 액세스를 결합해 입도가 큰 메모리 액세스에 통합이 가능하다.
실제로 G80/GT200 계에서는 warp의 절반인 16 스레드에서 메모리 액세스를 결합시킨다. 그러나 G80의 경우는 각 스레드의 액세스 하는 메모리 주소가 바뀌는 "Permuted Access"나 액세스 할 주소의 머리가 정렬되지 않는 "미서라인드 액세스(Misaligned Access)"의 경우 패널티가 매우 컸다. 그것은 분할된 다수의 메모리 액세스 트랜잭션을 발생시켜 버렸기 때문이다.

AstroGPU에서 표시된 결합 액세스의 흐름

AstroGPU에서 표시된 비결합 액세스의 흐름
그리고, 나쁜 것으로, 범용 컴퓨팅에서는 이러한 액세스 패턴이 생길 가능성이 높은 경우가 있다. 즉, 전통적인 그래픽스 태스크처럼 효율적인 액세스에 형편이 좋은 행동을 해주지 않는 경우가 다수의 어플리케이션이 있다.
GPU의 경우 높은 성능에 있기에, 고로 메모리 대역은 매우 타이트 하다. 메모리 액세스는 일정한 입도 (32 ~ 64 bytes)가 있기 때문에 액세스의 입도가 작을수록 낭비가 생긴다. 즉, 메모리의 최대 대역폭이 넓어도 실제로 전송할 수 있는 데이터 양이 줄어드는 메모리 대역 문제가 생긴다. G80에서는 이 문제가 매우 중요했다.
GT200은 여기가 개선되었다. 일정한 메모리 세그먼트에서 안에서 랜덤 액세스나 미서라인드 액세스는 GPU 하드웨어에 따라 단일 액세스 트랜잭션에 자동으로 정리한다. NVIDIA는 이 기능 때문에 메모리 컨트롤러에 직결되는 읽기 온리의 L2 텍스쳐 캐시를 사용하고 있다고 설명한다.
실제로는,이 비결합 (Non-Coalesced) 메모리 액세스의 하드웨어 지원을 위해 메모리 액세스 지연 시간은 약간은 연장된 것이다. 그러나 트랜잭션이 결합되므로 결과적으로 대기 시간이 단축되고 대역도 효율적으로 사용된다는 것이다. 이 부분은 CPU 비정렬 액세스 기능과 비슷한 것이다.
그대로 놓여진 공유 메모리의 강화
GT200은 강화되지 않은 부분도 있다. 그 대표는 공유 메모리 (Shared Memory)이다. NVIDIA GPU는 각 Streaming Multiprocessor (SM)의 안에 16KB의 공유 메모리가 있다. 이것은 읽기 & 쓰기 가능한 스크래치 패드 메모리로 스레드간에 공유 할 수 있다. 즉, 스레드 간의 데이터 교환에 이용 가능한 메모리다. 지난해 HotChips 19에서는 이 공유 메모리의 양이 한정되어 있으며, 또한 뱅크 충돌이 발생하기 쉬운 것도 문제라고 지적됐다.
NVIDIA가 공유 메모리를 강화하지 않았던 이유 중 하나는 이 메모리가 프로그램에서 보이기 때문이라 생각된다. 따라서 공유 메모리의 양을 조절하면 프로그래밍 모델에 미치는 영향이 크고, 소프트웨어 호환성을 가지기 어렵게 된다.
GT200은 공유 메모리를 그래픽스 태스크시에도 사용하고 있다고 한다. 지오메트리 셰이더에서는 공유 메모리를 프로그램 측에서 보이지 않는 형태로 이용하고 있다고 NVIDIA는 설명한다. GT200에서는 지오메트리 셰이더의 스루풋이 대폭으로 개선 되었다. (G80은 매우 나빴다) 이 때문에 아웃풋 레지스터 등의 자원이 필요하고, 공유 메모리가 이러한 용도에 이용되고 있을 가능성이 높다.
NVIDIA는 이번 그래픽 파이프 텍스처 캐시를 GPU 컴퓨팅으로 전용하고 GPU 컴퓨팅을 위한 공유 메모리를 그래픽스 태스크에 전용했다. NVIDIA GPU가 가진 두 가지 측면은 융합해 가는 것으로 보인다. 사실, 이것은 업계 전체의 흐름이다. 예를 들어, Microsoft는 DirectX 11에서 GPU 컴퓨팅 용의 특징을 그래픽 파이프로 활용하거나, 반대로 DirectX 11 자체에 GPGPU (범용 GPU) 스테이지를 집어 넣는다. GPU의 두 가지 기능은 미래적으로는 녹아 들어갈 것이다.
다만 NVIDIA의 구현에는 트레이드 오프가 있다. 그것은 그래픽 모드와 GPU 컴퓨팅 모드가 공존 할 수 없는 것이다. 현재 NVIDIA GPU에서는 양쪽 태스크에서 프로세서 모드를 전환 할 필요가 있다. 그래픽 모드에서는 정점 / 지오메트리 / 픽셀의 3개의 태스크를 혼재시킬 수 있지만, GPU 컴퓨팅에서는 모드 전환 할 필요가 있다. 앞으로는 이러한 오버 헤드를 줄이는 것도 중요해져 갈 것이다.
NVIDIA는 GPU 컴퓨팅에서의 문제점의 일부를 GT200 세대에서 해결하거나 완화했다. NVIDIA는 GPU를 범용적인 어플리케이션에서 사용하기 쉽도록 더욱 개량을 더해가는 기운이 있다는 것을 보였다. 문제는 그 속도가 충분히 빠른 것인지, 개량이 프로그래머의 지지를 얻는데 충분한 것인지 라는 점에 있다.
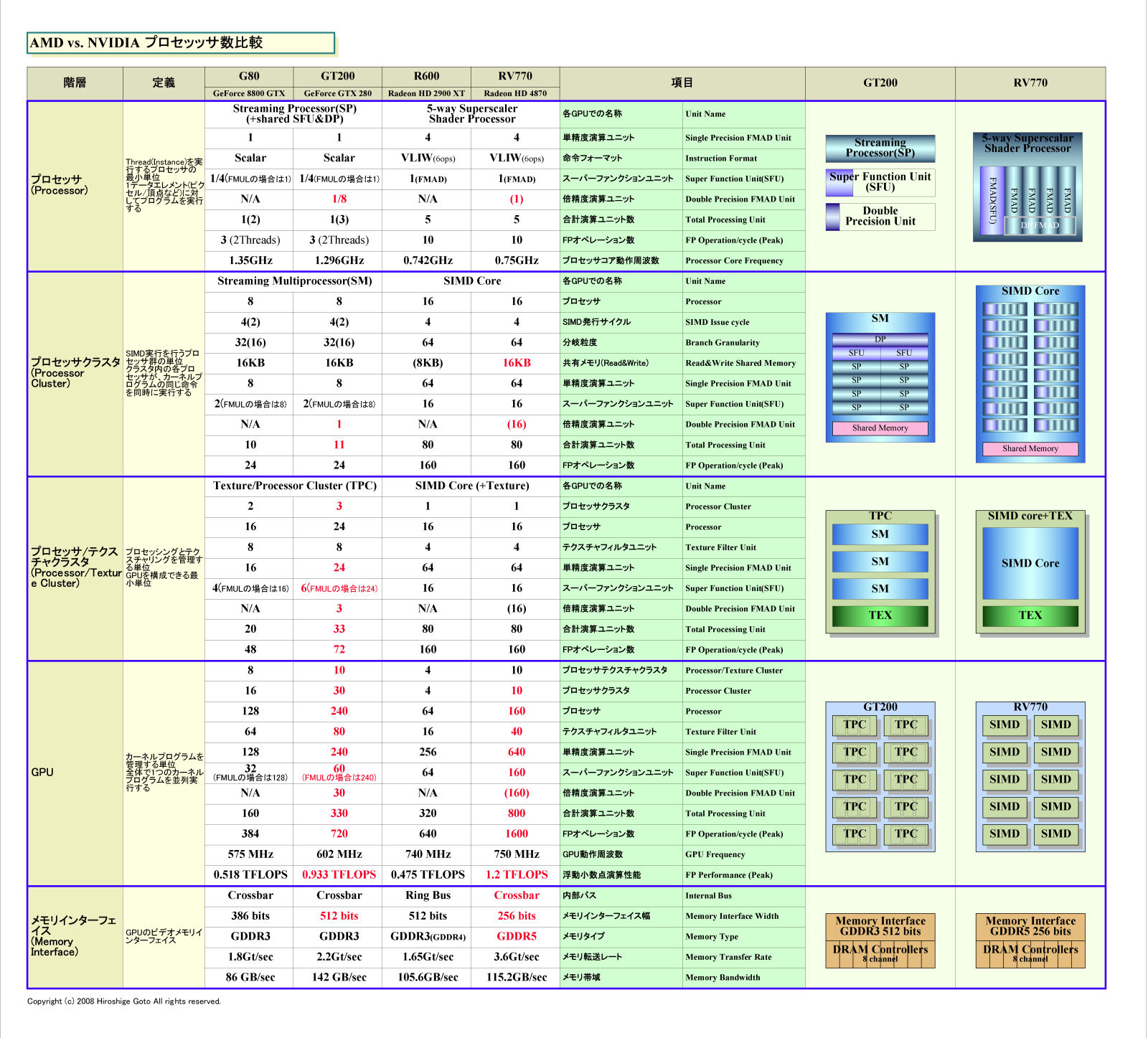
AMD와 NVIDIA GPU의 프로세서 수 비교
2008년 7월 16일 기사 입니다.
[분석정보] NVIDIA, Radeon HD 2000의 사양에 이의
[분석정보] 크게 다른 Radeon HD 2000과 GeForce 8000의 아키텍처
[분석정보] 지포스 GTX 280 배정밀도 부동 소수점 연산
[정보분석] 엔비디아 세계 최다 트렌지스터 칩 GK 110 공개
[분석정보] Intel의 Larrabee에 대항하는 AMD와 NVIDIA
[분석정보] Sandy Bridge와 Bulldozer 세대의 CPU 아키텍처
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 1/2
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 2/2
[분석정보] 슈퍼 스칼라에 의한 고속화와 x86의 문제점은
[분석정보] 명령의 실행 순서를 바꿔 고속화 하는 아웃 오브 오더
[분석정보] x86을 고속화하는 조커기술 명령변환 구조
[분석정보] CPU와 메모리의 속도 차이를 해소하는 캐시의 기초지식
[분석정보] 캐쉬 구현 방식으로 보는 AMD와 인텔이 처한 상황
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] IDF 2008 저스틴 래트너 CTO 기계 지능이 인간을 넘을때 (0) | 2008.08.23 |
|---|---|
| [분석정보] 정식 발표된 라라비(Larrabee) 아키텍처 (0) | 2008.08.22 |
| [분석정보] 가상 머신에서 직접 I / O 매핑이 가능한 VT-d. 미 Intel과 미 VMware가 데모 (0) | 2008.08.20 |
| [아키텍처] 베일을 벗은 인텔 CPU & GPU 하이브리드 라라비(Larrabee) (0) | 2008.08.04 |
| [분석정보] 인텔 박물관/연구소 견학기 4004 전자 계산기부터 최신 기술까지 (0) | 2008.07.01 |
| [분석정보] 지포스 GTX 280 배정밀도 부동 소수점 연산 (0) | 2008.06.20 |
| [분석정보] 9년전의 아이디어에서 태어난 아톰. 리서치 @ 인텔 (0) | 2008.06.13 |
| [아키텍처] Nehalem(네할렘)으로 볼 수 있는 인텔 CPU 마이크로 아키텍처의 미래 (0) | 2008.05.23 |