AVX 지원으로 전환한 AMD
AMD는 향후 범용 CPU 코어에 구현하는 벡터 연산 유닛을 위한 인터페이스를 AMD 독자적인 "SSE5"에서 Intel의 "AVX"호환으로 전환했다. 이미 보도된 바와 같이, AMD는 Intel이 2011년에 도입하는 Advanced Vector Extensions (AVX) 명령 확장을 자사의 CPU에도 구현해 간다.
이에 따라 우려되고 있던 Intel과 AMD의 확장 명령의 분단은 회피된 것이다. 또한, 명령 세트의 변경은 그 명령을 실행하는 CPU 하드웨어의 설계에도 큰 영향을 준 것으로 추정된다. AMD는 공식 블로그에서 2011년의 CPU에 AVX 명령을 구현 할 계획이라고 밝히고있다. 2011년의 CPU 아키텍처 "Bulldozer (불도저)"는 원래 SSE5를 지원할 예정이었다.
AMD와 Intel은 지금까지 SIMD 형을 중심으로 하는 명령 확장으로, 각각 다른 명령을 제창하고 있었다. AMD가 2007년에 적화 연산도 포함한 SSE5를 발표 후 Intel도 작년 (2008년) 봄에 AVX와 적화 연산의 FMA를 발표했다. 양사 모두, 범용 CPU 코어 안의 벡터 연산 유닛을 강화해 간다는 방향은 일치하고 있지만, 그 실현 방법과 명령 세트의 구현은 크게 달랐다. Intel은 SIMD 연산하는 데이터 길이를 펼치는 것을 중시, AMD는 데이터의 조작이나 데이터 타입을 늘리는 것을 중시했다. 물론, 호환성은 전혀 없었다.
이번 AMD는 Intel에 서로 양보하면서, 자사의 독자성을 유지하는 방법을 취했다. Intel의 사양을 지원하는 동시에, SSE5로 제안한 기능의 확장 명령도 구현하는 것을 밝혔다. 어떤 의미로 AMD가 구현하는 것은 Intel의 사양 슈퍼 세트가(인텔것을 지원하면서 추가로 더 지원하는) 된다.
구체적으로는 AVX 명령을 구현하는 동시에 AMD의 독자적인 확장 명령을 추가했다. "XOP (eXtended Operations)", "CVT16 (half-precision floating point converts)", "FMA4 (four-operand Fused Multiply / Add)"의 명령 군이다.
개념을 그림으로 하면 다음과 같이 된다. 지금까지는 그림 위 처럼, AMD가 녹색의 원, Intel이 파란색 원의 사양을 커버하고 있으며, 양사의 스펙은 공통되는 부분도 있지만 다른 부분도 컸다. 새로운 AMD의 방침에서는 그림의 아래같이, Intel의 사양은 커버하고 그 위에 덧붙여 왼쪽의 사양을 구현한다. AMD에서 보면, 기능적으로는 SSE5와 AVX의 양쪽 모두를 커버하게 된다.
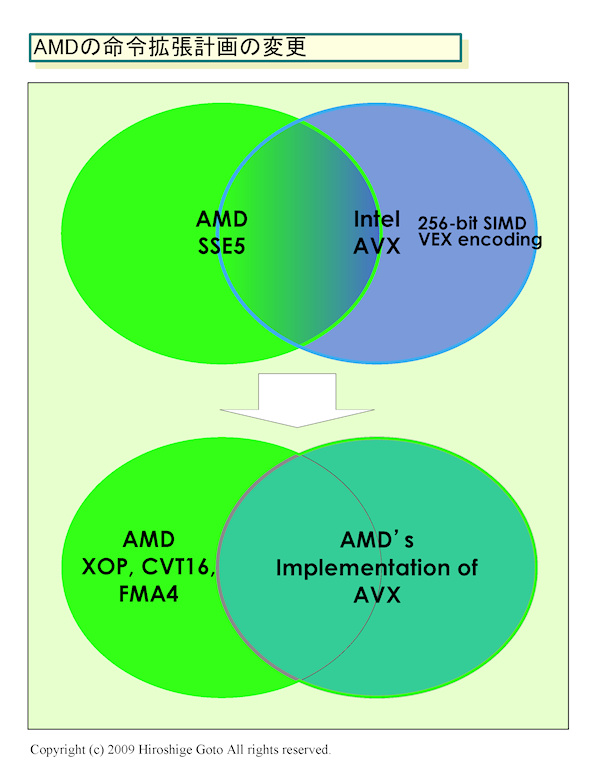
AMD의 명령 확장 계획의 변경
적화연산의 포맷은 4 피연산자
이번 변경으로 SIMD 연산의 벡터장은 SSE5의 128-bit 길이에서, AVX의 256-bit 길이로 바뀌었다. 32-bit 단정밀도 부동 소수점 연산이라면 8 병렬로 SIMD 실행할 수 있다. SIMD 레지스터도 128-bit 길이에서, 256-bit 길이 (YMM0 ~ 15)로 확장되었다. AMD는 AVX에 해당하는 명령이 있는 SSE5의 명령은 AVX로 전환하고 있다.
AVX에 해당하는 명령이 없는 부분은 AMD 독자적인 확장 명령인 XOP와 CVT16로 구현했다. 다음과 같은 명령군이다.
· Horizontal integer add / subtract 128-bit
· Integer multiply / accumulate 128-bit
· Shift / rotate with per-element counts 128-bit
· Integer compare 128-bit
· Byte permute 128-bit
· Bit-wise conditional move 128/256 -bit
· Fraction extract Scalar / 128 / 256-bit
· CVT16 (half-precision floating point converts)
적화 연산은 4 오퍼랜드의 적화 연산을 지원하는 FMA4를 정의했다. 이전 기사에서 잘못이 있었는데, Intel의 FMA는 처음은 4 오퍼랜드 였지만, 지금은 3 오퍼랜드 포맷으로 변해있다. Intel의 FMA 포맷에서는 기능적으로 충분하지 않다고 AMD는 판단하고, 포맷을 바꾼 FMA4를 도입한다.
적화산에서는 3 개의 소스 오퍼랜드를 필요로 한다. 예를 들면, 2 개의 레지스터 값 곱셈의 결과에 1개의 레지스터의 값을 더한다. 그 결과를 저장하려 하면 네번째 오퍼랜드가 필요하지만, 3 오퍼랜드 포맷에서는 그것을 할 수 없다. 그래서 소스 오퍼랜드의 하나에 결과를 덮어쓰지 않으면 안된다. (FMA3 예 : a = a x b + c)
4 오퍼랜드 포맷에서는 결과를 4 번째 피연산자에 쓸 수 있기 때문에 소스 오퍼랜드의 데이터를 파괴하는 것이 없다. 비파괴적인 형식이다. 그에 대한 3 오퍼랜드 포맷에서는 반드시 피연산자 중 하나의 데이터가 파괴되어 버린다. 파괴적인 포맷이다. 따라서 3 피연산자 형식은 레지스터의 값을 옮겨야 하는 조작이 필요한 경우가 나온다.
(FMA4 예 : a = b x c + d)
AMD는 FMA4가 우위에 있다고 확신을 가지고 있는 것 같다. 참고로, Intel의 CPU 로드맵에서는 FMA 명령은 AVX 명령보다 늦게 지원할 계획이다. FMA 명령의 지원시기라도 AMD는 선행 할 수 있기 때문에, FMA4가 지지하는 것으로 보고 있는지도 모른다.
우습게도, 이 관계는 당초의 포맷과는 역전되어 있다. 처음에는 AMD의 SSE5는 3 오퍼랜드로, Intel의 FMA는 4 오퍼랜드 였다. Intel은 3 오퍼랜드의 Larrabee New Instruction에 끌려가는 것처럼 형식을 변경하고 AMD는 명령 인코딩을 바꾸는 것과 동시에 4 오퍼랜드가 되었다.
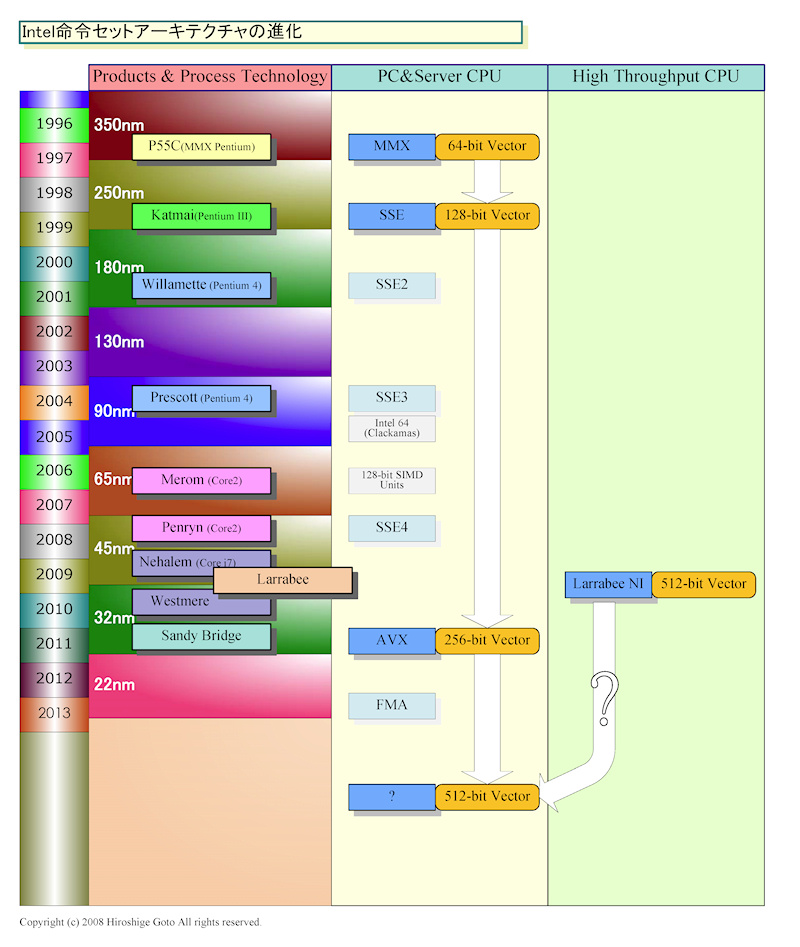
Intel 명령 세트 아키텍처의 진화
Bulldozer의 개발에 큰 영향을 준 AMD의 결정
AVX 지원은 SSE5를 구현할 예정이었던 2011년의 차세대 CPU Bulldozer 아키텍처의 개발에 영향을 주었다. 어떤 AMD 관계자는 2008년 봄에 Bulldozer의 계획이 2010년에서 2011년으로 후퇴한 한 요인이 AVX 발표를 받아, 명령 세트의 재검토에 있다고 시사했다. AMD는 그 시점에서 새로운 벡터 연산 유닛의 프론트 엔드 명령 세트를 어떻게 하는지, 진지하게 검토를하고 있었다고 볼 수 있다. 그러나 AMD는 극히 최근까지 SSE5라는 명칭을 고객과의 미팅에서도 사용하고 있었다.
또, 어떤 AMD 관계자는 AVX의 256-bit SIMD 연산의 하드웨어 구현은, Bulldozer에서는 볼수 없을 것이 라고도 말하고 있었다. 이것도 이해할 수 있는 얘기다. 이유의 하나는 Bulldozer의 설계는 벌써 꽤 진행됐기 때문에, 연산 유닛 자체를 재 설계하는 것은 어렵다고 추정되는 것. 2011년에 CPU의 출시를 늦춰도 2010년에 CPU의 실리콘 샘플을 완성해야하며, 2008년 봄 부터 검토를 시작해 변경 하는 것에는 시간적인 여유는 그다지 없다. 일반적으로 실리콘의 완성 전에 4년의 개발 기간이 있다.
여기에 또 하나는 AMD가 범용 CPU 코어 안에서의 SIMD 연산 유닛은 비교적 벡터장이 짧게 구현하기 쉬운 것에 멈추고, 어느 정도 이상의 데이터 병렬은 범용 CPU 코어의 밖으로 오프로드 하는 것을 생각 한것. AMD의 전 CTO였던 Phil Hester (필 헤스터) 씨는 최종적으로 SSE5 확장 명령을 CPU에 융합시킨 벡터 엔진에 매핑해 끝낼 가능성도 보여주었다. 벡터 엔진과 범용 CPU의 통합이 진행되면, 그러한 구현 형태도 생각할 수 있다. Intel과 비교하면 AMD 쪽이 범용 코어에서 벡터코어로 오프로드 하는데 적극적인 비전을 가지고 있으며, 이 때문에 범용 CPU 코어 안의 벡터 연산 유닛의 벡터 길이의 확장에 대한 동기 부여는 상대적으로 낮은 것으로 추정된다.
실제로 AMD는 AVX의 256-bit SIMD를 지원해도, 최초의 구현은 연산 유닛 자체는 128-bit 폭대로 멈출 가능성은 있다. 과거에도 AMD와 Intel 모두, SSE의 구현에서는 128-bit SIMD 연산을 64-bit 폭의 연산 유닛으로 실행한 예가 있다. 성능면에서의 이점은 없지만, 연산 유닛 자체는 128-bit SIMD 인 채 크게 변경하지 않고 지원이 가능하다. 256-bit SIMD 명령을 명령 디코드 시점에서 128-bit SIMD의 uOPs 쌍으로 변환하면 대응할 수 있기 때문이다. 물론, 레지스터는 256-bit 폭으로 확장할 필요가 있으며, 레지스터 셔플 엔진 등도 확장 할 필요가 있다고 추정된다.

Intel AVX의 개요
Bulldozer는 클러스터화 된 마이크로 아키텍처?
Bulldozer는 클러스터 (Clustered) 형 마이크로 아키텍처를 갖는다 추정되기 때문에 미래에 좀 더 유연한 구현도 가능하다.
어떤 업계 관계자에 따르면, Bulldozer의 CPU 코어는(모듈) 멀티 스레드를 병렬로 실행시킬 수 있지만, Intel의 멀티 스레딩과는 크게 다르다, AMD가 설명했다고 한다. Intel의 멀티 스레딩과 같이 2개의 스레드가 하나의 CPU 코어의 실행 자원을 완전하게 공유하는 것이 아니라 각 스레드가 각각 실행 파이프를(코어) 가진다. 따라서 서로 자원을 서로 빼앗는 일없이, 스레드를 병렬로 실행시킬 수 있다. 그러나 멀티 코어와 같이 완전히 독립된 코어로 스레드를 병렬화하는 것이 아니라, 코어 안에서 어떤 의미로 공유되고 있다고 설명했다고 한다.(모듈내 2코어가 FPU를 공유) (이때는 자세한 모듈구조 이런게 나오지 않았기 때문에..)
이 설명은 AMD의 미국에서의 특허 군 (United States Patent Application 20090006814, 20090024836)으로 부터 추정되는 Bulldozer 마이크로 아키텍처의 모습과 일치한다. CPU 코어 자체가 클러스터화 되어 있어 2개의 분할된 자원이 별도의 스레드를 달리게 할 수 있지만, 자원을 결합해 단일 스레드를 실행시킬 수도 있을것 같은 구조이다. 간단한 예에서는 2 명령 발행의 CPU 코어를 2 개 클러스터 화하고, 최대 4 명령 / 스레드 발행을 가능하게 한다고 구현을 들수 있다.
Intel의 SMT (Simultaneous Multithreading)와 비교하면 필요한 트랜지스터 수는 많지만, 멀티 스레드 성능도 더 높아진다. 비교적 간단한 제어로 높은 멀티 스레드 성능과 높은 싱글 스레드 성능을 효율적으로 양립 할 수 있는 것으로 보인다. 클러스터 형 마이크로 아키텍처 관련 특허의 발명자 리스트에는 과거에 K8 아키텍처 발표 때의 프레젠테이션 등에 나온 개발자의 이름이 보인다. (방식에 따른 성능을 얘기하는 것이지, 실제 제품의 성능을 말하는 것은 아닙니다. K10 이상의 정수 2코어에 1개의 FPU가 결합되면 인텔의 고성능 1코어에 SMT 보다 멀티스레드 성능이 더 높겠지만, 저성능 코어 2개에 1개의 FPU가 결합되면 멀티스레드 성능도 높다고 장담할 수는 없겠죠.).
클러스터드 마이크로 아키텍처를 벡터 연산 유닛에 적용 시키면 다음과 같은 예상이 있다. CPU 코어에 1개의 256-bit SIMD 유닛을 갖춰 256-bit SIMD 명령이 왔을 때 1개의 256-bit SIMD 유닛으로 일하고 128-bit SIMD 명령이 왔을 때, 2 개의 128-bit SIMD 유닛에 분할 해 2 스레드로 병렬에 사용한다고 구현이 있을 것이다. 이것 이라면, 256-bit시가 아니더라도 벡터 연산 유닛을 풀 가동시키기 쉽다.
Bulldozer가 추정되는 마이크로 아키텍처라면, 이러한 유연성을 가지게 된다.
무엇보다, Bulldozer 세대 CPU의 본질적으로 중요한 부분은 CPU 코어 내부보다 오히려 점차 CPU에 시스템 레벨 통합으로 다양한 기능을 통합하고 이를 연계시켜 나가는 것이다. 벡터 연산으로 말하면, 오프로드 엔진과 어떻게 연계시킬 것인가가 관건이 된다. x86 명령 스트림 안의 벡터 연산의 인터페이스가 SSE5에서 AVX + XOP로 바뀐 지금도 그 점은 변하지 않을 것이다.
AMD는 Bulldozer 코어 CPU로 서버에서는 "Interlagos (인테르라고스)"를, 퍼포먼스 데스크탑 PC에서는 "Orochi (오로치)"를 2011년에 출시할 것을 밝힌바 있다. 그러나 AVX + XOP + FMA4가 Bulldozer 코어 CPU의 등장 시점부터 적용 될지는 모른다. Intel은 2011년 Sandy Bridge (샌디 브릿지)부터 AVX를 구현할 예정이다.
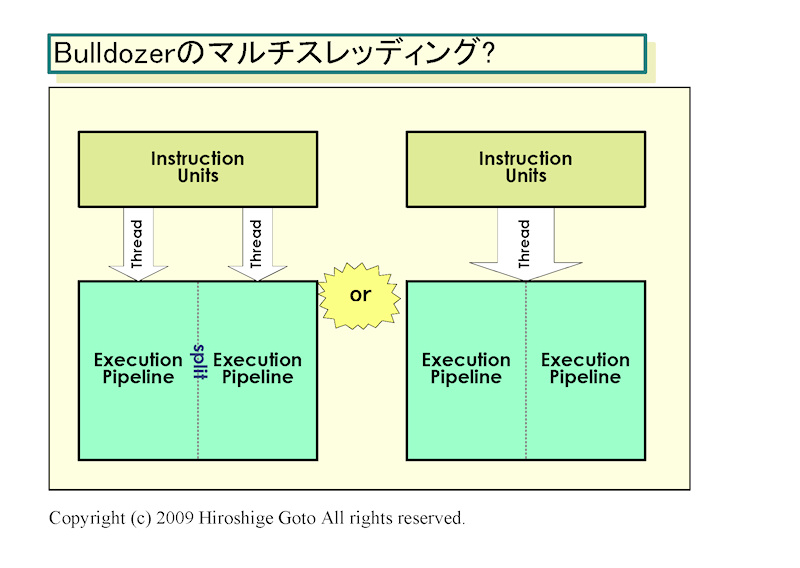
Bulldozer의 멀티 스레드 구조의 추측
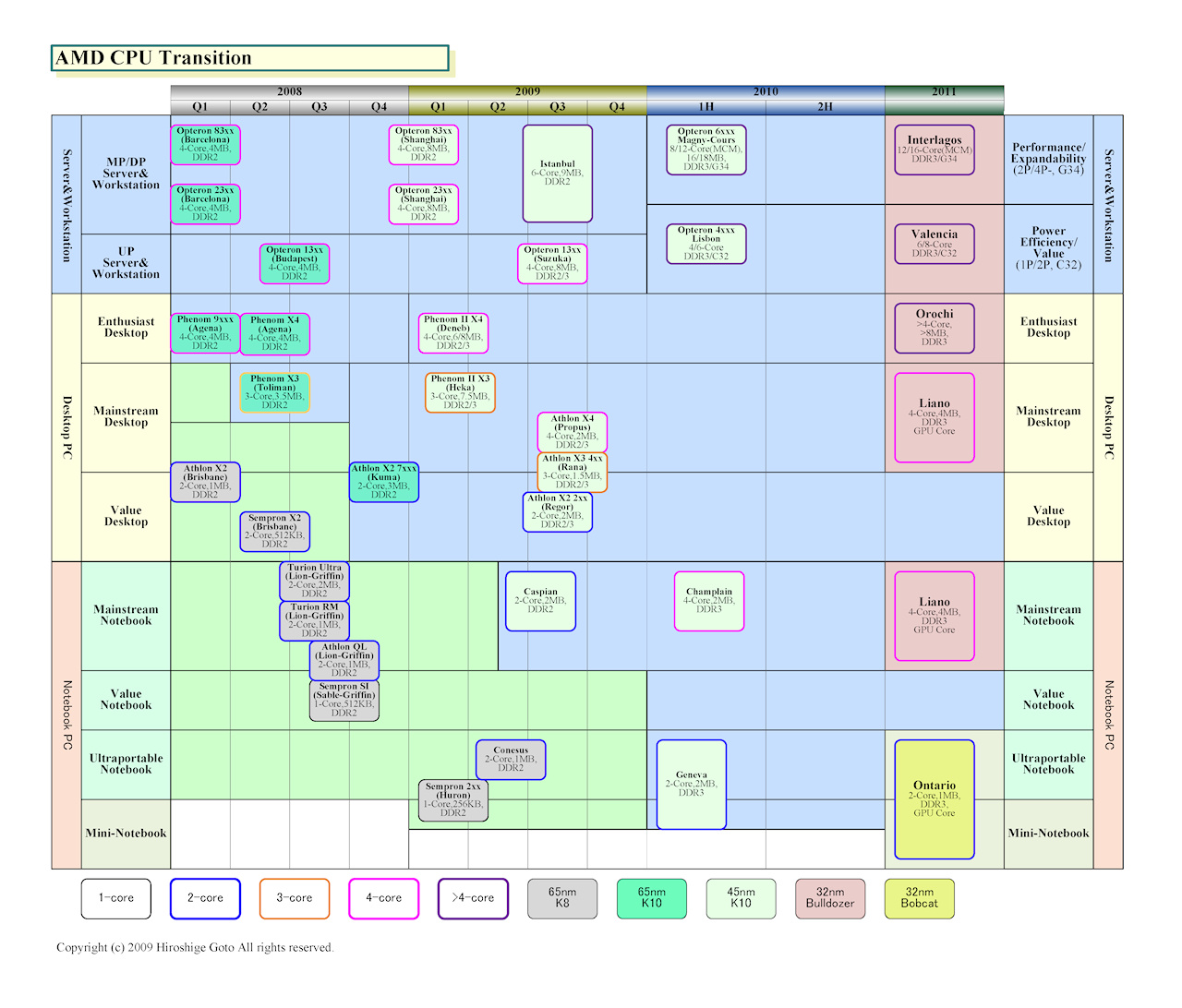
AMD CPU 이행 예상도
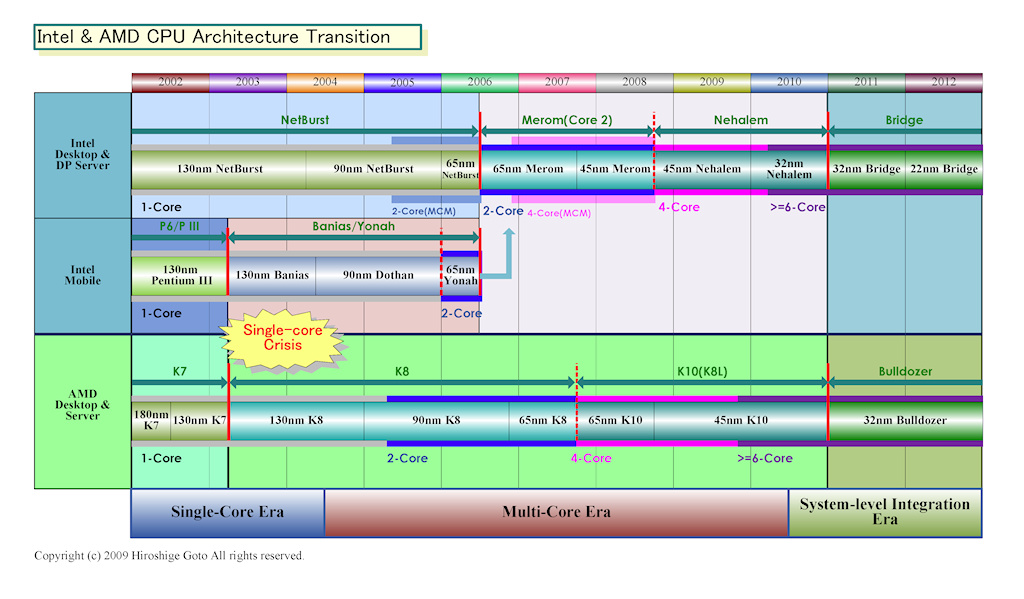
Intel과 AMD의 CPU 아키텍처 이행 예상도
명령 인코딩 방식의 변경
SSE5에서 AVX의 변경으로, 하드웨어 설계에 미치는 영향이 크다고 생각되는 것은 명령 인코딩 방식의 변경이다. Intel은 2008년 봄 Intel Developer Forum (IDF)에서 AVX의 설명시 AVX에서 중요한 점은 명령 인코딩의 개혁에 있다고 강조했다. AVX는 "VEX (Vector Extension)"라는 새로운 명령어 인코딩 제도를 채용하고 있다.
x86 명령은 가변 길이 이기 때문에 명령어 세트를 확장하는 것이 용이하다. 지금까지는 새로운 명령 확장을 추가하거나 새로운 데이터 유형을 추가 할 때마다 1 byte 분의 접두사를(prefix) 추가해 왔다. 그러나 그 방식은 명령 세트의 복잡화와 명령 길이의 늘어남 이라는 폐해를 가져왔다고 Intel은 설명했다. 그 결과로, 바이너리의 비대화와 CPU의 명령 디코드 & 디코드 하드웨어의 복잡화를 초래했다.
특히 가변 길이 x86 명령은 명령의 길이를 판정해 다음 명령의 머리를 찾아 내기 어렵다. 고정 명령 길이의 RISC (Reduced Instruction Set Computer)에서 결정한 다음 명령의 머리를 찾아 낼 수 있는 것과 비교하면 큰 차이다. 실행 유닛에 대한 명령 발행 수를 늘리면 복수 명령을 1 사이클에 디코드 해야 하기 때문에 단시간에 명령 단락을 찾을 필요가 있다. 명령의 복잡화는 이러한 x86 CPU에 있어서 큰 문제였다.
VEX는 이 문제를 해결하기 위해 새롭게 만들어진 인코딩 방식이다. VEX는 2bytes 또는 3bytes의 VEX 접두사 안에 복수의 기존 접두사의 정보를 압축해 인코딩 했다고 Intel은 설명했다. 구체적으로는, VEX에서는 선두 바이트가 "C4h"또는 "C5h"(64 bit 모드에서는 비어있다.)에서 C4h에 이어 2bytes, C5h에 이어 1byte가 명령의 정보를 포함하는 페이로드가 된다. 페이로드 부분에 기존의 접두사에 포함된 정보와, 그 위에 256-bit 길이 데이터 유형 등 새로운 정보도 포함된다. VEX는 명령어 압축 기법이다.
또 Intel은 VEX가 향후의 명령 확장을 포함할 만큼 여유가 충분히 있는 인코딩 방식이라고 설명했다. C4h의 페이로드에는 아직 3bits 분의 예약 비트가 1,000 개 이상의 새로운 명령이나 데이터 유형을 추가 할 수 있다고 말한다.

AVX의 구조
VEX 인코딩을 사용 접두사를 독자적으로
VEX의 또 다른 장점은 접두사 부분의 명령 포맷이 고정되는 것. 이에 따라 명령 디코드가 기존보다 쉽게 될 것이라 한다. C4h라면 4bytes 째에, C5h라면 3bytes 째 반드시 ModRM이 있어, 비교적 쉽게 전체의 명령 길이를 산출 할 수 있다. 포맷이 이후의 확장 명령의 추가도 동일하기 때문에, 디코더를 복잡하게하지 않고 명령 확장을 계속할 수있다.
실제로는 AMD의 SSE5의 포맷도 어느 정도는 비슷한 생각으로 만들어져 있었다. 이곳은 3-byte 작동 코드 방식으로, 최초의 2bytes 분이 새로운 접두사가 되고 있고, 명령 길이의 예상이 붙기 쉽도록 되어있다.
그러나 SSE5의 3-byte 작동 코드 방식은 Intel의 VEX와 다른 인코딩 방식이기 때문에 AMD에게 어려운 문제가 발생했다. 만약 명령 디코더를 SSE5와 AVX의 두식에 호환으로하려고 하면 디코더가 복잡하게 되어 버리기 때문이다. 양 대응은 가뜩이나 크고 소비 전력이 많은 디코더의 복잡함을 초래한다. 따라서 AMD는 만약 SSE5가 보급되지 않으면, SSE5와 AVX 양쪽을 호환하는 등의 대응을 잡기는 어렵다.
AMD는 이러한 요소를 생각한 결과 또는 SSE5의 인코딩을 완전하게 버리고, VEX 인코딩 방식으로 이행했다. 그것은 AMD의 독자 확장인 XOP 명령 군에 대해서도 마찬가지로, XOP를 SSE5의 인코딩 방식으로 구현하는 것은 하지 않고, VEX에 가까운 방식으로 했다. 즉, 이번 이행으로, CPU 하드웨어 측에게는 명령 디코드 알고리즘이 크게 바뀌었다.
Intel의 VEX 인코딩에는 여유가 있기 때문에 AMD는 VEX의 리저브 비트를 사용해 자사의 XOP 확장을 맵하는 것도 가능했다. 그러나 AMD는 Intel의 VEX 스페이스 안에 XOP를 저장하는 방법은 피했다. 이것은 Intel 자신이 향후의 명령 확장을 사용하면 작동 코드 스페이스가 간섭해 버릴 가능성을 피하기 때문이라고 생각된다.
대신, AMD가 채용한 것은 VEX와 같은 코딩 방식으로 VEX와 다른 접두어를 사용 것이었다. VEX의 경우 접두사 부분의 선두 바이트가 C4h 또는 C5h이다. 반면, XOP에서는 선두 바이트가 "8Fh"로 되어 있다. 선두 바이트는 다르지만, 연속적인 페이로드 부분의 포맷은 VEX와 같게 되어 있다.
덧붙여서, 8Fh에는 POP 명령을 할당 할 수 있지만, 이것은 8Fh의 다음 바이트의 mmmmm 필드의 값으로, POP 명령 또는 XOP인지를 판정 (8 미만이라면 POP)하도록 되어 있다. Intel의 VEX 정도의 확장성 여유는 없지만 충분한 명령을 맵 할 수있다.
인코딩 방식이 기본적으로 거의 동일하기 때문에, XOP의 명령 디코드는 VEX와 닮은 알고리즘을 사용할 수있는 것으로 생각된다. 선두 바이트가 C4h 또는 8Fh (또한 mmmmm가 8 이상)이라면 다음의 형식이 거의 동일하다고 판명하기 때문에 동일한 알고리즘으로 대응할 수있다. 따라서 XOP 이라고 하는 새로운 명령 군을 더해도, 명령 프리 디코더와 디코더는 상대적으로 간단하게 막을 수 있다.
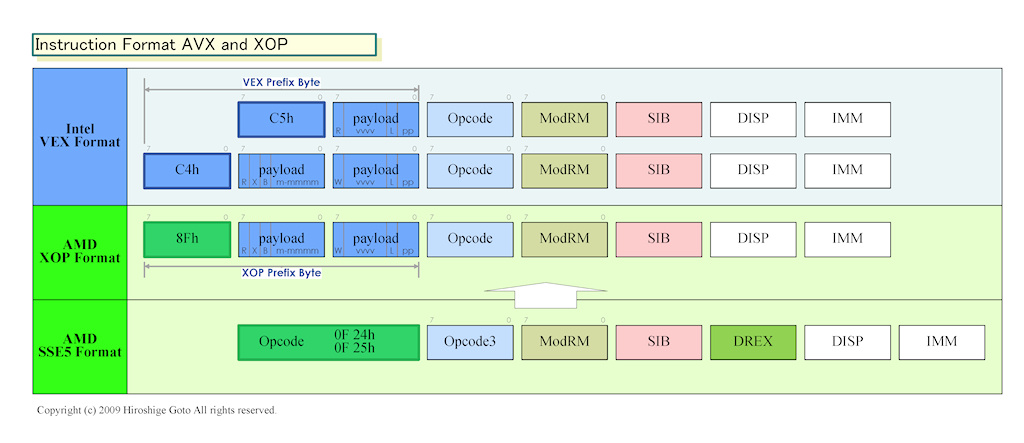
AVX와 XOP 명령 서식
2009년 5월 18일 기사 입니다.
[분석정보] x86에서의 탈피를 도모 Intel의 새로운 로드맵
[분석정보] AMD의 차세대 CPU Bulldozer의 클러스터 기반 멀티 스레딩
[분석정보] AMD가 2009년의 CPU 코어와 통합 CPU의 개요를 발표
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] 메가화 노선을 유지하는 인텔과 팹리스를 목표한 AMD (0) | 2009.09.12 |
|---|---|
| [분석정보] 구글 크롬 OS는 왜 Network computer를 닮았나? (0) | 2009.07.23 |
| [분석정보] Intel의 연구 개발 부문 개편과 그 성과 (0) | 2009.06.22 |
| [분석정보] Intel 울트라 모빌리티 기조 강연 (0) | 2009.06.05 |
| [분석정보] Sandy Bridge와 Bulldozer 세대의 CPU 아키텍처 (0) | 2009.05.14 |
| [분석정보](암달의 법칙) 2010년대 100 코어 CPU 시대를 향해서 달리는 CPU 제조사 (0) | 2009.05.13 |
| [분석정보] 인텔 GDC에서 라라비 명령 세트의 개요를 공개 (0) | 2009.03.30 |
| [분석정보] GDC 2009 드디어 소프트 개발자 정보도 나온 "Larrabee" (0) | 2009.03.28 |