CPU의 속도에 따라갈 수 없는 메모리의 속도
이번에는 "캐시"의 이야기이다. 캐시의 목적은 "지연의 은폐"에 있다. 불쑥 고자세의(수준높은) 말이 통하지 않기 때문에, 옛날 이야기에서 시작하자.

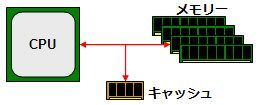
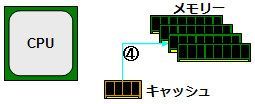
[그림 1] 초기 CPU와 메모리의 조합
초기 PC의 경우 그림 1과 같이 CPU와 메모리가 직결 (엄밀히 말하면 메모리 컨트롤러를 통한)되어 있었다. 초기라는 것은 대개 i386 내지 호환 칩셋이 사용되고 있었을 무렵까지 이야기이다.
이때는 CPU의 속도가 빨라도 30MHz 정도. 메모리 칩의 속도는 100ns (10MHz) ~ 80ns (12.5MHz) 정도. 가끔 70ns 제품 (≒ 14.3MHz) 및 60ns (≒ 16.7MHz) 제품이 고가로 판매된다는 어떤 의미의 한가로운 시대였다.
물론, 이것도 CPU의 속도에 따라 가지 못하고 있지만, 예를 들면 2 ~ 4 웨이 인터리브에서 사용하는 경우, 40 ~ 50MHz 상당으로 유효하다. 이러한 동작을 지원하는 메모리 컨트롤러 (칩셋)도 있었기 때문에, 성능면에서의 괴리는 크지 않았다.
그런데 그 후, 486 이상 (정확히 말하면 i486DX2 이상)은 괴리가 갑자기 커진다. 먼저 코어의 동작 주파수와 FSB의 속도가 일치하지 않게되었다. 그 시작은 486DX2/40 ~ 66이다. FSB는 20 ~ 33MHz인데, CPU 코어는 40 ~ 66MHz에서 작동하기 때문에 아무리 빠른 메모리를 가지고 와도, 메모리 액세스는 코어의 절반 속도로 밖에 할 수 없게되었다.
당초 이 차이는 2배 정도 였지만, 486 세대에서도 AMD CPU는 차이가 4배로 늘었다. 또한 가장 극단적이었던 Pentium 4기반 Celeron / Celeron D의 경우, 400MHz FSB에서 2.8GHz 구동 (7 배) 라든지, 533MHz FSB에서 3.6GHz 구동 (6.75 배)의 제품도 존재했다. 이렇게 되면 메모리 액세스가 발생한 순간 이 차이가 병목이 된다.
다른 문제도 있다. 386까지 내부 처리에 마이크로 코드를 많이 이용해 명령의 대기 시간이 꽤 컸기 때문 메모리 액세스에 여분의 대기가 들어가도 성능면에서 큰 영향은 없었다. 그런데 486 이상은 와이어드 로직에 의한 명령의 대기 시간을 크게 개선했기 때문에, 반대로 메모리 액세스 지연 시간이 매우 큰 문제가 되기 시작했다. 프로그램의 로드와 연산 결과를 내보내기에 메모리 액세스는 필수이므로 CPU 만 가속화 하고 이를 가속화하지 않으면 의미가 없다.
([분석정보] 차세대 CPU 힌트가 나왔다 IDF 486 자체 얘기는 아니지만.. 그래도 블로글중 486시대 얘기가 조금 있는 글;;;;;;;;;)
로드시 캐시의 기본 동작
[그림 2] CPU와 메모리 사이에 캐시를 배치
그래서 생각한 것이 캐시이다 (그림 2). 당초 캐시는 CPU 내부에 놓여 있었지만, CPU의 외부에 있어도 안에 둔것과 기본적인 움직임은 변하지 않는다. 로드의 경우를 생각해 보자. 먼저 CPU는 메모리에 대한 읽기 요청을 발행하는 (①).
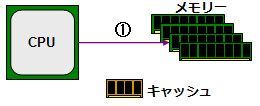
① CPU에서 메모리에 로드 요청 발행
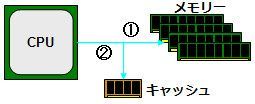
이에 따라 메모리는 지정된 주소의 데이터를 CPU에 발송만 (②)이 때 캐시에 동일한 데이터를 발송할 (③).

② 메모리에서 CPU로 데이터를 보낸다. ③ 동시에 캐시에도 동일한 데이터 쓰기
이후 동일한 데이터를 CPU가 요청하는 경우는 메모리가 아닌 캐시에서 읽기 (④)하여 메모리보다 고속으로 판독 할 수 있다는 것이다. 즉, "1 번째 읽기는 느리지만, 2 번째 이후는 빠르게 읽는" 라는 것이 캐시의 구조이다.

④ 동일한 데이터의 요청에 대해 캐시에서 CPU에 데이터 쓰기
속도를 담보하기 때문에 일반적으로 캐시는 SRAM으로 구성된다. 이것은 CPU의 내부 회로와 같이 논리 회로만으로 구성되기 때문에, 고속화 된 FSB는 물론, CPU의 내부에 통합이 충분히 기능하다. 문제는 SRAM은 비용이 많이 드는 (= 필요로 하는 트랜지스터가 많다)이다.
기술적으로는 최소라면 4T SRAM (트랜지스터 4 개로 SRAM 1bit 분)이 가능하지만, 현실적으로는 6T 및 8T SRAM이 많이 사용되고 있었다. 최근에는 8T 구성은 거의 볼 수 없다, 6T SRAM이 주류를 이루고 있지만, 트랜지스터 1개 (와 캐패시터)로 구성된 DRAM에 비해 훨씬 비용이 든다. 지금처럼 윤택하게 트랜지스터가 남는 시대는 차치하고, 일단 조금이라도 트랜지스터의 수를 줄이고 싶었기 때문에, SRAM에 많은 트랜지스터를 할애 여유는 없었다. (당연히 8T SRAM이 용량에 비해서 회로 크기가 당연히 더 큽니다. 이 글의 당시에는 8T가 아닌 6T를 많이 쓴다고 하는데... 이후에 보면 또 인텔은 8T SRAM을 씁니다. 이쪽이 더 저전력에 적합하다고.. 8T SRAM을 사용).
(이 기사가 작성되는 시기에 각 회사마다, 같은 회사에서도 구성이 바뀌기 때문에, 각 아키텍처 기사 필독)
라이트 백 캐시의 채용으로 메모리 쓰기 대기도 단축
그리하여 486에는 8KB의 캐시를 코어에 내장되게 되었다. i486DX의 경우 총 트랜지스터 수는 120 만개. 8KB 캐시는 6T SRAM 구성의 경우, 트랜지스터 수는 다음과 같다.
6 (T SRAM) × 8 (bit) × 8K (Byte) = 38만 4천개
즉, 총 트랜지스터의 32%의 비율을 차지하게 된다 (실제로는 그 밖에도 회로가 있으므로 차지하는 비중은 좀 더 커진다). 고작 8KB에도 이만큼 큰 영향이 있다는 점에 주의 하라. (SRAM은 이렇게 회로가 크기 때문에, DRAM과 같이 고용량이 나오지 못하죠. 예전 펜티엄 시절까지 L2 캐쉬는 전부 메인보드에 붙어 있거나 또는 슬롯형 캐쉬를 끼워야 했구요. 최초로 펜티엄 프로 에서 L2 캐시까지 넣긴 했지만 태생자체가 후에 나온 펜티엄MMX나 펜티엄2 처럼 MMX명령 같은게 없기도 했고... 그때도 많이 쓰이던 16bit 성능이 떨어져서 더 개인용으로 쓰이지 못하기도 했지만, L2 캐쉬 덕에 패키지 크기가 커지고 수율이 좋지 않았다고 하죠. 펜프로는 공정의 진화에도 줄어들지 않는 크기인 많은 트렌지스터 수 + 추가로 더해진 캐쉬 다이 MCM으로 수율이 매우 좋지 않았습니다. 3다이 (2다이 캐시, 1다이 CPU) 펜프로도 있죠. MCM 이니까 대형 1다이가 수율이 낮아지는 것과 달리 수율이 좋은거 아니냐? 라고 할 수 있는데, 다이상태로 완전한 검증이 가능한 것은 펜D 시절부터라고 합니다. 이전 시절까지는 패키징을 한 이후에 완전한 검증이 가능했기 때문에, 수율이 높아지지 않았다고 합니다. 수율을 높이는 방법은 결국 슬롯형 이어야만 가능하다는 얘기죠. 패키징된 정상 CPU를 기판에 붙이고, 패키징된 정상 캐시를 슬롯에 붙이는 거니까요. 그러니까 스롯1의 기판비용이 추가되도 그 쪽이 더 비용상 유리하던 시절이라는 얘기 입니다. (슬로컨버터의 경우 여러가지 전압관련 회로까지 다 붙어 있어도 싼건 개인이 사는 가격이 몇천원 수준이니.. 그런거 없는 간단한 기판에 대량으로 쓰는 인텔이라면 더 쌌겠죠. 또 초기 셀러론 처럼 CPU코는 펜2와 같지만 슬롯 기판에 L2만 빼서 저가형 제품으로 판매도 쉽죠. MCM에 대한 내용 아래 글을 보세요.)
[분석정보] 2008년 중에 95%를 듀얼 코어로 하는 Intel CPU로드맵의 비밀
이런 이유로 펜티엄2 에서는 슬롯1 (제온은 슬롯2)형태의 제품으로 바뀌고 슬롯의 기판에 CPU와 L2캐쉬가 나란히 놓이게 되죠. AMD쪽도 사정은 마찬가지라 AMD는 독자적인 슬롯A를 내놓게 되구요. 어쩔수 없는 과도기 적인 제품이 되는 것이죠. 공정이 진화 하면서 다이 내부에 L2캐쉬까지 모두 넣을 수 있게 된 후에 다시 소켓형태로 돌아오니 말이죠. 이것도 잘 보면, 캐시도 슬롯형 펜2,3 의 512kB 에서 256kB로 줄어들어서 소켓형(1다이)으로 들어가죠. 또한 캐시는 줄어들었어도, CPU와 동클럭이 되면서 CPU성능은 더 올라가게 되는데, 256kB 캐시의 펜3는 훨씬 늦게 출시가 되고, 128kB의 셀러론이 훨씬 빠르게 출시가 되죠. 캐시가 그만큼 적은 용량이라도 크기가 거대하다는 것이죠. 캐시가 작은 셀러론이 우선적으로 소켓화 되고(수율이 괜찮으면 오히려 이제 슬롯형 기판값이 더 비싸지게 되죠), 뒤 늦게 256kB 캐쉬를 가진 펜티엄3가 뒤에 소켓화가 되구요.)
[고전 1997/08/19] 인텔, 1MB의 L2캐시를 탑재한 Pentium Pro 200MHz를 출하
1995년 2월 24일 매일경제 P6 가격
[고전 1997/05/07] 인텔, 차세대 주력 CPU Pentium II를 공식 발표



(원래 기사에는 없지만... 슬롯형 CPU는 이렇게 생겼습니다. 나이드신 분들은 알겠지만 모르는 분들도 계실테니... AMD의 슬롯 A CPU도 비슷하게 생겼습니다. 뒷면의 쿨러가 자연스럽게 일체형으로 된건 박스 정품이고, 방열판이 튀어나오고 쿨러가 달린건 트레이 제품 입니다. )

인텔의 슬롯1과는 다른 슬롯A를 사용하는 애슬론.
(슬롯은 물리적으로는 같은데, 슬롯을 돌려서 사용하고 (같은 부품을 써야 부품비 절감. 점유율이 적은 AMD가 새로운 슬롯을 만들면 아무래도 가격이 조금이라도 비싸짐.), 물리적으로 같을 뿐 돌려서 사용하는데다, 각각의 핀은 서로 다르고 (전원이냐, 버스냐 등), 버스도 (쉽게 얘기하면, USB와 IEEE1394가 상호 호환 불가이듯.. 인텔 P6 계열은 P6버스, K7은 EV6 버스) 다르기에 호환성은 당연히 없습니다. 핀 수가 같다고 호환되는게 아니에요. 설사 슬롯을 안돌려서 쓴다고 해도요.
또 인텔이 슬롯1으로 간 이유는 AMD가 못 쓰게 하려는게 아니라 (국내 기레기 문제) 캐시 메모리 때문 입니다. k6보다 거대한 코어를 갖는(그래서 성능이 높은) k7도 마찬가지로 슬롯으로 간 이유죠. 어짜피 P6 아키텍처의 버스 자체가 인텔 특허 입니다 (자신들이 개발한 기술에 특허를 거는 것은 당연한 권리 입니다. 각자 본인한테 본인들이 개발한 기술 그냥 내놔라 하면 내놀건지?). 그래서 펜티엄 프로가 쓰는 소켓8 로는 AMD CPU가 없죠. 소켓8과 Slot1은 버스가 똑같습니다. 물리적 형태가 바뀐 것 뿐이죠. 버스가 특허라 AMD가 못 쓰는 겁니다. 슬롯이냐 소켓이냐 문제가 아니라요. 국내는 기레기 때문에 슬롯이라서 못 쓰게 한거다 라고 알려짐.
다른 것으로 설명하면 usb가 기본적인 type A 형태이든 앞뒤가 똑같은 Type C이든 물리적 모양만 다르지 똑같은 USB 라는 것과 같습니다. 같은 거니까 그냥 단순 모양만 바꿔주는 젠더 사서 끼우면 사용이 되죠. 똑같은 겁니다. 그래서 소켓 370 CPU를 슬롯1으로 바꿔주는 라이저 카드가 있는 거구요. usb 젠더 같은거랑 같은 겁니다. 다만 라이저 카드의 경우는 CPU 전압등이 다름을 커버하기 위해 별도의 전원부 회로가 추가 되었다 정도의 차이. (이런게 아니라면 라이저 카드는 별도의 버스 변환 칩까지 갖춰야 해서 가격이 훨씬 바싸졌겠죠. 싼 라이저 카드가 1만원 미만의 몇천원 짜리는 존재가 불가능.)
이후에 AMD나 인텔이나 공정이 2세대 바뀌면서 더 많은 회로를 적은 크기로 만들 수 있을 때에, 그래서 아예 코어에 내장이 가능해진 때에 양쪽 모두 다시 소켓으로 간 것도 똑같죠 (인텔은 소켓 370. AMD는 소켓A). 단순히 AMD가 못 쓰게 하려고 slot1으로 간거면 AMD는 slotA로 갈 필요가 없죠. 그냥 처음부터 소켓A를 만들어서 그걸 쓰면 될텐데 말이죠. 버스에 대한 기술이 없는 AMD는 알파 EV6 버스를 사와서 쓰게 되는 거구요. 그와 달리 비아는 떼쓰는게 아닌 인텔에서 직접 라이센스를 받습니다. 알파한테 EV6 버스를 돈주고 쓰는건 하겠지만, 인텔한테는 그냥 공짜로 쓰게 해달라?)
[고전 1998.11.30] VIA, Slot 1의 라이센스를 정식으로 취득
[고전 1999.07.01] VIA가 Cyrix 인수로 정말 원했던 것은 무엇인가?
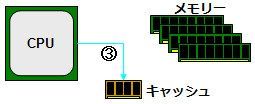
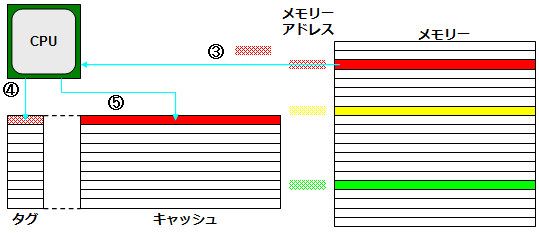
한편 기록은? 이라고 하면 먼저 실용화 된 것이 그림 3 "Write Through"(write-through)라는 방법이다. 즉 메모리와 캐시 모두에 동시에 기록하는 방법이다. 그러나 이 방법이라고 메모리에 쓰기 완료까지 CPU는 가만히 기다려야 하며, 효율이 나쁘다.
[그림 3] 연속 기입 캐시의 기본 구조. ① 메모리에 기록합니다. ② 동시에 캐시에 기록
그래서 "Write Back"(write-back)이라는 방법을 짜냈다. 이것은 CPU는 먼저 캐시에 기록 (③),이어서 캐시에서 메모리에 다시 (④)라는 방법이다.
③ CPU에서 캐시에 데이터를 기록
④ 다음 캐시에서 메모리에 데이터를 기록
SRAM의 경우, 쓰기도 원칙적으로 1사이클로 종료되기 때문에, DRAM 메모리에 비해 상당히 빠르다. 물론 상시 메모리에 기입이 발생하는 경우에는 늦어진다 (캐시 용량이 부족) 그래서 결국은 메모리 쓰기가 완료 될 때까지 기다려야 한다. 하지만, 어느 정도 크기의 프로그램에서는 이런 일은 일어나기 어렵기 때문에 메모리에 쓰기도 가속화되는 셈이다.
여담이지만, 그럼 그 "어느 정도 크기의 프로그램" 이 만족하는 캐시 용량은 어느 정도인가? 라고 하는 것은 이론만으로는 결정하기 어렵고, 실제로 다양한 프로그램을 달리게하고, 그 때에 필요한 캐시 용량을 확인한다. 그러기 위해서는 몇 가지 크기의 캐시를 시뮬레이션에서 준비하고, 그 위에 실제 프로그램을 실행시켜 성능과 캐시 미스 비율을 확인해야 한다.
이러한 작업은 CPU의 다양한 매개 변수 모두 말할 것이며, 이것에 따라서 새로운 아키텍처를 동작에 시간이 걸리는 이유 이기도 하다. 다양한 아키텍처의 손익을 모두 시뮬레이션 등으로 확인하지 않으면 안되는 것이다.
https://youtu.be/vIob0r6GjSU?t=423
인텔 486과 AMD 486 기타 486의 성능과 인텔 AMD 486의 라이트 백 캐쉬 CPU와
라이트 스루 캐시의 CPU 성능 차이. 앞은 설명 7분 3초 정도 부터 성능.
486 초기 버전은 라이트 스루이고, 후기는 (인텔 1994년) 라이트 백 입니다.
(초기는 8kB 캐시 내장, 후기는 16kB 캐시 내장. 지금으로 보면 보잘것 없는 용량이죠)
참고로 인텔 80486은 1989년 첫 출시이고, Am486은 1993년 첫 출시 입니다.
생산량이나 업계 전체를 끌고 나갈 힘이 없던 AMD의 예전은 더 새로운 CPU 출시로 그쪽에 생산을 인텔이 집중하면, 더는 발전이 없는(한동안 생산은 하지만 더 높은 클럭 등으로는 발매 안함. 해당 제품의 클럭 한계치 (오버가 아니고, 완전 안정된 상태) 이상으로 클럭을 더 높이려면 물리적 설계를 다시 해야 하고, 샘플 생산 테스트와 수정, 다시 샘플 생산 이후 대량 생산으로 가기 때문에 이것도 다 돈과 시간이 들어 갑니다.) 인텔의 기존 소켓 제품에 비해 더 높은 클럭의 제품을 파는 것이 전략. 동급 제품이 늦게 나온 만큼 당연히 늦게까지 팔아야 하죠.1년 팔고 말거면 공장 건설 비용도 문제가 되구요. 늦게까지 팔아준게 아니라, 늦게 까지 팔아야만 하는 상태.
(인텔이라고 해서 FAB이 무한대가 아니기 때문에 당연히 신기종 나오면, 기존 제품은 1~2년 정도 까지만 생산하고 단종 됩니다. 아예 새로운 FAB을 추가로 건설하는 것도 있지만, 신기종 생산에 필요한 FAB을 모두 새로 건설하는게 아니라, 이후에 구제품 생산하던 공장을 일단 닫고 그 공장을 업그레이드 해서 신기종을 출시하는 공장이 되기 때문에, 구기종을 계속 생산 할 수가 없습니다. 하드웨어는 소프트웨어가 아니다 라는 얘기죠. 간혹 이런 생산 문제를 생각 안하고, 신제품 나오면 팔아먹으려고 구제품 단종한다고 하는데, 사회생활을 전혀 안해본 소리죠. 구제품 신제품 다 원래 대로 생산하려면 공장을 계속 짓고 직원을 계속 뽑아야 합니다. 그리고 구제품이 예전처럼 팔리지도 않죠. 군수품 같은 경우도 (특히 복잡한 무기들, 비행기나 탱크 같은) 초기 저율생산 이후에 대량 생산을 한다고 해도 마구 만드는게 아니라, 약간 더 늘어난 정도로 만드는 것도 같은 이유구요. 보급품의 경우도 뭐 5년에 걸쳐서 10년에 걸쳐서 보급하는 이유도 마찬가지 이니다. 공장이 무한대가 아니고, 직원도 무한대가 아닙니다. 그리고 보급 다 했을 때 공장 놀면 그걸 정부가 책임져 주지도 않고, 마구 뽑은 직원을 지금은 필요없는데 정부가 책임져 주지도 않고, 다 자를 수도 없죠.
이 시절에는 새 제품이 나오면 구 제품은 한동안 보급형으로 쓰이기에 그래도 구제품도 한동안 출하가 되는데, 셀러론이 나온 이후부터는 같은 신제품에서 보급형,메인,고급형이 다 나오기 때문에 더욱 예전 제품은 얼마 안가서 단종이죠. 다만 임베디드 옵션을 달고 있는 제품은 장기간 공급을 해주죠. 인텔 486은 2007년 마지막 주문 받고 단종 됐습니다.).
물론 인텔도 구형 소켓에 신형 아키텍처 CPU를 사용 할 수 있는 오버드라이브 프로세서가 있기는 했죠. 또 그런 것과 별개로 486의 경우도 꾸준히 DX4까지 만들기도 했구요.
외국 뉴스를 보면 타사에서 CPU만 제조사에서 받아서 직접 오버드라이브 프로세서 같은걸 만들기도 했구요.
1993년에 인텔에서는 펜티엄이 (일명 586) 출시 됩니다.
(펜티엄 초기는 (486 초기 때도 마찬가지 386과의) 워낙 비싸기도 해서 고가의 웍스테이션에 주로 쓰이는게 이유가 있기도 하고, 한편으로는 미국같은 나라와 당시 우리나라와의 소득차이가 크기 때문에 가격적 문제가 더 크게 다가와서 (CPU만의 가격이 문제가 아닌 메인보드 가격, 메인보드 칩셋 가격, VGA 가격, 사운드 카드 가격, 메모리 가격도 문제. 인텔이 직접 칩셋 제조 및 자사 브랜드 보드를 출시하면서 가격의 하향 평준화) 훨씬 뒤늦게 486을 구입하고 나니, 금방 펜티엄이 나온게 되버려서 486 유저 입장에서는 버렸다는 생각이 들수도 있겠죠. 여러 과거 신문 기사를 찾아봐도 94년 95년 까지도 486을 사는데, 펜티엄이 94년 말 95년 초에 상당히 싸져서 PC 본체가격으로 94년 말 95년초 정도면 30만원 정도 차이가 나죠. 아무튼 이 시기에는 펜티엄 보드 가격만 해도 40~60만원 하던 시절 입니다. 펜티엄이 싸졌다 라고 하는 시기가 인텔 브랜드로 나온 보드가 20여만원 수준. 요즘하고 물가 생각하면 엄청난 가격이죠.)
A Comparison of Different Amounts of L2 Cache on a 200MHz Pentium
(L2 캐시가 보드에 있는 펜티엄을 가지고 L2 캐시별 성능 비교. 가장 마지막은 내부 캐시인 L1 캐시까지 바이오스에서 꺼버린 경우. 보드에 따라서 다른데 펜티엄4 보드에서도 L2 캐쉬를 끌 수 있는 옵션을 제공하는 경우도 있습니다. 대부분은 없죠.
대략 펜티엄 시대라면, 가장 용량대비 성능이나, 가격, 당시의 주류로 보드에 끼워져 있던 용량등을 생각하면, 보통이 256kB 정도인데, 이 정도가 가장 괜찮았다 정도가 될 수 있겠죠. 512kB 정도도 256kB에 비해서 어느정도 성능 향상 효과가 있고, 1MB 캐시의 경우는 용량이나 가격대비로 굳이 있을 필요는 없는 성능 향상 정도가 되겠죠. 다만 모든 CPU가 영상과 같은 캐시일 때 동일한 양상일 것이다 라고 생각하면 안되고, 시대별 CPU에 따라, 프로그램에 따라, 시대별에 따라서 양상은 다를 수 있습니다. 많으면 좋지만 무조건 많다고 용량만큼 좋은건 아니구나 라는 대략적인 개념으로 보세요. 아무튼 이 시절 까지는 256kB 정도가 회로대비 최적 성능이라고 봐도 됩니다. 512kB는 성능은 조금 더 높아지만, 용량대비로 보면 미비 합니다. 캐시는 어머어마 하게 크다는 걸 아셔야 하구요. 이 시절의 L2 캐시는 정확하게 말하면, 펜티엄2의 슬롯 보드에 (위에 CPU 알몸 깐 그림) 있는 모양의 L2 캐쉬가 아예 보드에 납땜 되어 있는 형태, DIP 소켓 형태에 여러개의 소형 캐쉬 칩이 끼워져 있는 형태, 아예 펜2 슬롯이나 램 소켓과 비슷하게 생긴 긴 슬롯에 램 모듈 같이 생긴 캐쉬를 끼웠다 뺐다(용량 업그레이드 쉬움) 할 수 있는 형태로 나뉩니다.
좀금 다른 얘기지만, 이런 경향이 있기 때문에 펜티엄2 시절 초기 L2 캐쉬가 없는 셀러론이 욕을 좀 많이 먹었습니다. 물론 실제 성능이 모든 소프트에서 꽝은 아니었고, 보통의 사무용 소프트는 꽤나 빨랐습니다. 게임 같은게 망이라서... 그래서 셀러론은 사무용 이라는 말이 생긴거구요. 물론 이후로도 비슷해서 펜4 시대에도 512kB의 노스우드 펜티엄과 128kB의 노스우드 셀러론의 성능도 역시 사무용이나 인코딩이라면 셀러론도 꽤 좋은 성능을 내지만, 게임은 차이가 꽤 났죠. 이때는 둘다 똑같은 풀 스피드 L2 캐시. 셀러론 쪽이 용량도 작은 만큼 웨이 수가 낮았었구요.
또 이렇게 할 수 있던 것은.. 펜티엄은 L1 캐쉬가 데이터8kB 명령 8kB 이지만, P6 아키텍처에서는 L1 캐시가 각각 16kB로 두배로 늘었다는 것. 동기식 D램 (SDRAM) 으로 램 속도가 좀더 빨라졌다는 것. 그래도 L2 캐쉬가 0인건 좀 너무하긴 했죠...;;; 하프 스피드 캐시로 128kB 정도라도 달았더라면.... 그나마 다행인건 최초의 L2 캐시 0인 셀러론 출시 4개월 뒤에 128kB 풀스피드 캐시를 내장한 멘도시노 셀러론이 나왔다는 것 입니다. 그러니까 최초 코빙턴 셀러론은 펜2에서 그냥 기판 L2 캐쉬 안단 제품이고, 멘도시노 셀러론은 기존 펜2와 설계자체가 다른 128kB L2 풀스피드 캐쉬를 내장한 완전 새로운 제품이라는 거죠. 이렇다는 얘기는 최소 1년 이상 전부터 설계및 검증을 끝내고.. 소규모 생산부터 대량 생산으로 옮겨 왔다는 얘기 입니다. (더 고급인 펜티엄2도 L2 캐쉬를 내장하지 않고 팔고 있는데.. 그덕에 하프 스피드 L2 캐시. 고급형 모델은 펜3에 가서야 256kB를 내장하죠. 캐쉬가 그만큼 크기가 거대하다는 것이고, 그래서 대용량 캐시를 넣기가 힘들다는 얘기. 불가능은 아니지만, 생산량 감소, 가격 상승) 이렇게 보면 커빙턴 셀러론은 저가형 모델 시간 벌기용 이라고 할 수 있겠죠. 좀 다른 얘기라고 했듯이.. 본문의 내용과는 조금 다르지만
512kB의 거대용량이지만 CPU클럭의 절반 속도로 동작하는 외부 L2 캐쉬를 가진 펜티엄2 펜티엄3와 128kB로 작지만 CPU 클럭과 동일한 속도로 동작하는 셀러론 300A에 대한 성능은 아래의 링크에서 본문과 아래에 추가한 글들, 동영상을 확인 하세요. 참고로 최고급형 CPU인 당시의 인텔 제온은 펜티엄2와 같이 CPU 기판에 달린 외부 캐쉬지만 속도는 CPU 동일한 인텔 커스텀 고속 캐시를 달았습니다. 물론 가격도 비쌌죠..
[고전 1998/09/01] 새로운 셀러론, 그 실력은 어때?
캐시의 명부가 되는 "태그" 영역
캐시 구조면을 좀 더 자세히 설명하자. 그림 2의 설명은 쉽게 "우선 CPU는 메모리에 대한 읽기 요청을 발행한다" 라고 썼지만, 이것이 우선 큰일이다. "어떤 메모리 영역의 데이터가 캐시에 있는지 여부"를 먼저 CPU (캐시 컨트롤러)가 판단해야 한다. 이 때 이용되는 것이 "Tag"(태그)로 불리는 영역이다.
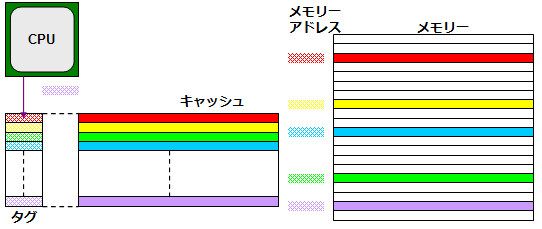
구체적으로 태그를 포함한 사용법을 보자 (그림 4-1). CPU가 메모리 주소 (빨강)을 액세스하려고하는 경우 대상 주소가 태그 안에 들어 있는지 여부를 확인 (①). 물론 처음에는 캐시가 비어 있으므로이 경우 CPU는 캐시 미스 (캐시 영역에 원하는 데이터가없는) 것으로 판단한다. 그렇게되면 CPU는 메모리에 메모리 주소를 지정하여 읽기 액세스를 실행하는 (②).

[그림 4-1] ① 태그에 메모리 주소가 있는지 확인.
② 주소를 지정하여 메모리 로드를 수행
메모리 액세스하려면 그림 4-2과 같이 메모리는 지정된 주소에 대한 데이터를 CPU에 대해 반환 (③). 이와 동시에 이 데이터의 주소 (④)를 태그에 데이터의 내용을 캐시 자신에게 (⑤) 각각 복사 (이것이 캐시 필).
[그림 4-2] ③ 지정 주소 데이터를 CPU에 보낸다.
④ 지정 주소를 태그에 기록합니다. ⑤ 데이터 캐시에 기록
일단 캐시에 데이터가 들어가면 이후 거기에서 참조가 가능하다. CPU에서 메모리 주소를 지정하여 태그를 검색하면 곧바로 히트 (그림 4-3). 따라서 해당 캐시에서 신속하게 데이터를 읽고 완료 할 수 있으므로 상당한 액세스 시간의 경감을 꾀할 수 있다.

[그림 4-3] ① 태그에 메모리 주소가 있는지 확인.
② 데이터를 캐시에서 로드
태그에서 해당 데이터를 어떻게 검색하는지
참고로, "1 회에 데이터를 얼마나 저장할 것인지?" 를 결정하는 것이 "라인 크기"이다. 32bit CPU의 경우 캐시에서 가져올 양은 1회 4Byte 정도라면 메모리 액세스가 번잡하게 발생. 그렇다고 4KB 정도하면 효율은 좋지만 (Windows의 가상 메모리는 1 페이지 4KB이므로 수습이 좋은) 이번에는 캐시 미스가 복잡하게 일어난다. 이것을 감안하여 적당한 크기를 결정하게 된다.
인텔의 경우, 예를 들면 Pentium 및 P6 (Pentium Pro ~ Pentium III)는 라인 크기가 32Byte 이지만 Pentium 4 이상의 CPU는 64Byte 되었다. 또한 일부 제품은 128Byte Sector 라는 관리 단위도 지원하고 응용 프로그램이 최적이라고 생각되는 라인 크기를 선택할 수 있게 되어있다.
그런데 캐시해야 할 데이터가 적으면 좋지만, 캐시 대상이 많아지면, 태그를 검색하는 데 시간이 걸린다. 예를 들어, 그림 5와 같이 태그가 풀로 사용되고 있는 상태라면, 위에서 아래로 검색해 가는 것은 꽤 시간이 걸린다.
[그림 5] 태그가 모두 사용되고있는 경우
Core 2 프로세서의 경우 1차 캐쉬는 32KB로 라인 크기가 64Byte 그렇다면 512 개의 항목 (태그 저장 위치)이 있다. 이것을 일일이 휩쓸어서는 매우 오래걸린다.(참고로 Full Associative 함)
다른 방법은 주소의 하위 부분을 태그와 1:1로 대응시키는 방식이다. 32bit CPU의 경우, 메모리 주소는 당연히 32bit이다. 라인 크기 64Byte (6bit) 항목이 512 개 (9bit)라는 경우 그림 6과 같이 주소의 일부를 그대로 태그 ID 본다.

[그림 6] 메모리 주소와 태그 ID의 관계
이 방식이라면 해당 태그가 고유로 정해지므로 항목을 1개만 확인하면 캐시 히트 또는 캐시 미스를 확인할 수 있어 캐시 액세스는 매우 고속으로 된다. 이 방식은 '다이렉트 맵' 이라고 하지만,주기적인 데이터 액세스에 매우 효율이 떨어진다는 단점도 안고있다. 예를 들어 다음의 5 개의 주소 데이터가 들어 있었다고 하자.
00010000H
00020000H
00030000H
00040000H
00050000H
이 경우 그림 6에 따라 태그 ID를 결정하면, 모든 태그 ID가 "0 0000 0000"이 되므로, 동일한 엔트리를 잡게 되어, 전혀 캐시의 효과가 없는 것이 된다.
이러한 결점도 있고, 다이렉트 맵과 풀 어소시에티브의 퓨전형 이라고 말하는 형태로 널리 이용되고 있는 것이, "n 웨이 세트 어소시에티브" 방식이다. 여기서 'n'은 '몇 개의 태그가 있는 것인가"를 나타낸다.
예를 들어 그림 7은 2 웨이 세트 어소시에티브의 경우이다.
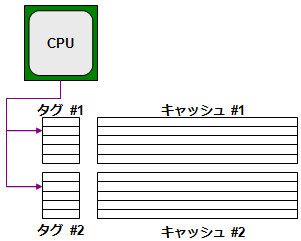
[그림 7] 2 웨이 세트 연관 캐시의 예
각 태그는 모두 다이렉트 맵으로 구성되어 CPU는 먼저 "태그 # 1"을 참조하여 원하는 주소가 있는지 검색한다. 여기에서 히트하면 좋고 없으면 다음 "태그 # 2"를 참조하여 재확인 하는 것이다.
이 방식의 장점은 다이렉트 맵 보다 주기적 주소 액세스에 효과가 높은 것이다. 방금 5개의 주소의 예로 말해 5개의 주소를 순차적으로 참조하는 경우 다이렉트 맵은 처음 "00010000H '만 캐시 할 수 있지만, 2웨이 세트 어소시에티브 라면 "00010000H'와 '00020000H " 2개를 캐시 할 수 있다. 마찬가지로 4웨이라면 4개, 8 웨이라면 5 가지를 모두 캐시 할 수 있다.
인텔의 경우 1차 캐쉬는 4~8 웨이 정도지만, 2 차 / 3 차 캐시는 16 웨이와 24 웨이 (Penryn 기반 Core 2 Duo) 라는 장렬한 수를 구성하고 있는 것도 있다. "어떤 웨이 정도가 적당한가? '라는 것은, 역시 이론만으로는 정해지지 않고 시뮬레이션에서 다양한 테스트를 하면서 실험적으로 결정하는 경우가 매우 많다.
2010년 10월 25일 기사 입니다.
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 1/2
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 2/2
[분석정보] 슈퍼 스칼라에 의한 고속화와 x86의 문제점은
[분석정보] 명령의 실행 순서를 바꿔 고속화 하는 아웃 오브 오더
[분석정보] x86을 고속화하는 조커기술 명령변환 구조
[분석정보] 캐쉬 구현 방식으로 보는 AMD와 인텔이 처한 상황
[분석정보] 5W 이하의 저전력 프로세서의 개발로 향하는 Intel
[분석정보] intel의 듀얼 코어 CPU 1번타자 Montecito
[분석정보] 멀티 코어 + 멀티 스레드 + 동적 스케줄링으로 향하는 IA-64
[정보분석] Penryn의 1.5 배 CPU 코어를 가지는 차세대 CPU "Nehalem"
[고전 2002.09.12] Hyper-Threading Technology를 지원하는 HTT Pentium 4 3.06GHz
[고전 2005.11.30] 마이크로 아키텍처의 변화를 반영하는 "Core"브랜딩
[분석정보] 20년 후인 지금도 곳곳에서 살아남은 펜티엄 아키텍처
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] ARM버전 Windows로 시작된 x86 대 ARM의 CPU전쟁 (0) | 2011.01.24 |
|---|---|
| [분석정보] 범용 컴퓨팅을 강화한 Sandy Bridge의 그래픽 (0) | 2010.12.14 |
| [분석정보] 캐쉬 구현 방식으로 보는 AMD와 인텔이 처한 상황 (0) | 2010.11.15 |
| [분석정보] 보여진 AMD의 차기 CPU Llano의 실상 (0) | 2010.11.04 |
| [분석정보] AMD가 확장판 K10 코어 기반의 APU Llano 를 첫 공개 (0) | 2010.10.21 |
| [분석정보] x86을 고속화하는 조커기술 명령변환 구조 (0) | 2010.10.04 |
| [분석정보] 명령의 실행 순서를 바꿔 고속화 하는 아웃 오브 오더 (0) | 2010.09.27 |
| [아키텍처] 트릭을 거듭한 Sandy Bridge 마이크로 아키텍처 (0) | 2010.09.22 |