Intel 최초의 듀얼 코어 CPU는 Montecito
intel이 드디어 듀얼 코어 CPU의 라이브 데모를 실시한다.
intel은 이번 주 개최되는 개발자 컨퍼런스 "Intel Developer Forum (IDF)"에서 멀티 코어를 전면에 내보낸다. IDF에서 엔터프라이즈 솔루션의 키 노트 연설에서 듀얼 코어 CPU의 데모를 행할 예정이다. 아마도 데모가 행해지는 듀얼 코어 CPU는 차기 IA-64 프로세서 "Montecito (몬테시토)"가 될 것이다.
Montecito는 2005년 중반에 투업될 예정인 차세대 Itanium 기반 듀얼 코어 CPU. Intel의 2005년 듀얼 코어 CPU 러시의 1번타자(1번수 의역임)가 될 것으로 예상되고 있다. Intel은 8월의 칩 업계 컨퍼런스 "Hotchips 16"(8월 22 ~ 24일)에서 이미 Montecito의 개요를 밝혔다. 프레젠테이션을 보면 Montecito가 Intel 계열 CPU 중에서는 가장 괴물이라는 것을 알수 있다. 또 Montecito에는 IA-32 계 CPU도 포함한 향후 Intel CPU가 추진하는 기술적인 트렌드도 비춰진다.
Montecito는 Prescott (프레스컷) 같은 90nm 공정으로 제조하고, Itanium2 계 CPU 코어를 듀얼로 탑재한다. 캐시를 합계 27MB 이상 탑재하기 때문에 트랜지스터 수는 17억 2000만에 달한다. Prescott의 10배 이상이다.
CPU 코어 자체도 강화되고 있으며, 멀티 쓰레딩 기술 "Coarse-Grain Multithreading" 기술을 채용해, 각각의 코어가 2스레드를 바로 실행이 가능하다. 즉, 합계 4쓰레드의 스레드 병렬성 (TLP : Thread-Level Parallelism)이 있다.
아래가 Montecito의 블록도 이다. L3 캐시까지 깨끗하게 나뉜 2개의 코어가 하나의 CPU에 탑재되어 있다. 코어간 캐시의 공유는 행하지 않고, 2개의 코어가 공유하는 것은 시스템 버스 뿐이다. 이 구성은 AMD의 듀얼 코어 구성과 비슷하다. AMD도 L2 캐시를 2개의 코어에 분리해 갖춰 듀얼 코어를 취했다.
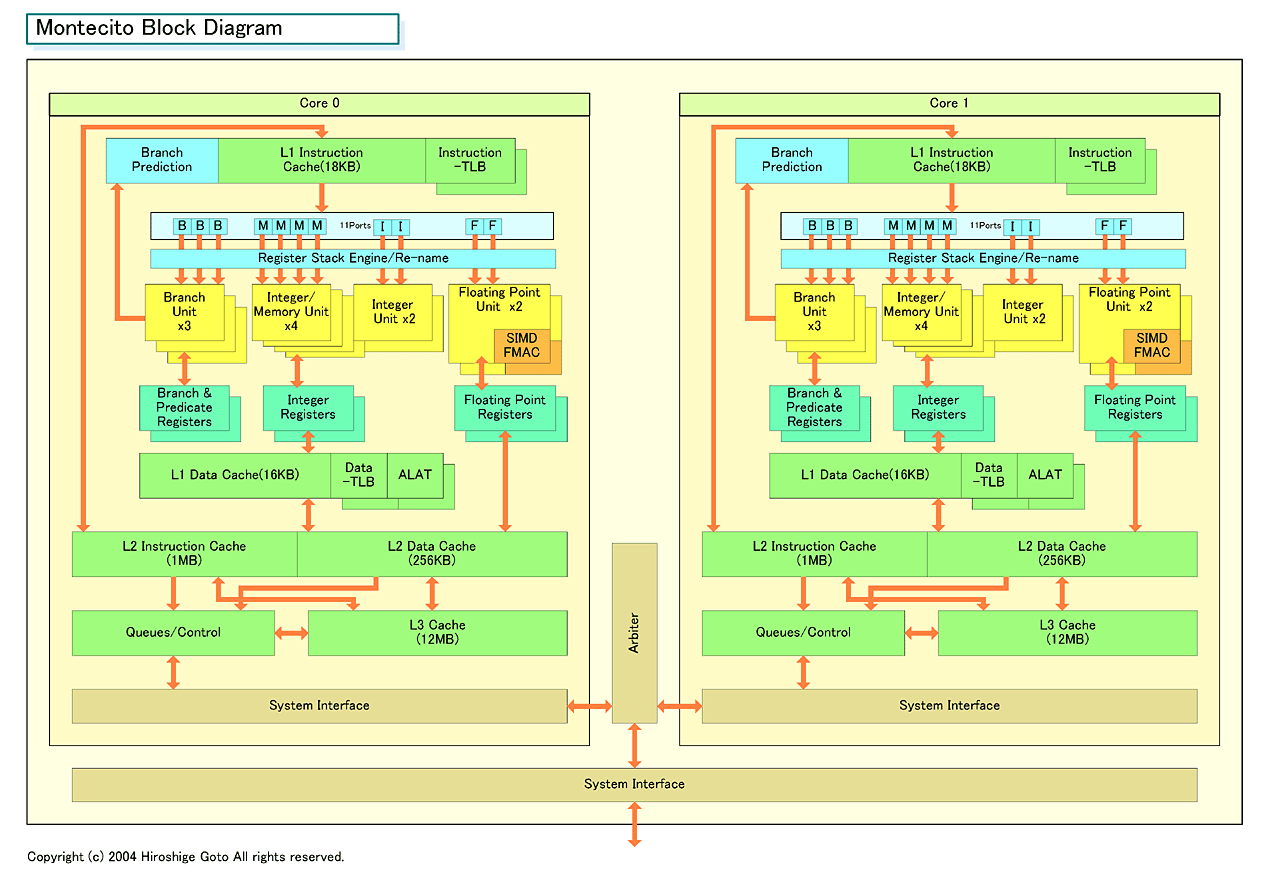
Montecito의 블록 다이어그램
Montecito의 경우, 코어의 캐시 구성을 바꾸지 않은 것은 기존의 IA-64 프로그램의 최적화와의 호환성도 고려했기 때문으로 추측된다. IA-64의 경우 정적 컴파일러에서 명령 수준의 스케쥴링을 하기 때문에 캐시 구성의 변화 등은 최적화에 영향을 주는 것으로 생각된다. 먼저 Montecito 코어 L2 캐시는 기존의 McKinley / Madison 코어와 약간 다르다. 지금까지 그간 통합이었던 L2 캐시가 명령과 데이터로 분리 되었다. 1MB의 L2 명령 캐시와 256KB의 L2 데이터 캐시의 구성이 되었다.
Montecito는 시스템 버스도 기존 Itanium2계와 호환성을 갖는다 (533MHz의 고속 버스도 도입되지만 아키텍처는 동일). 지원 칩셋도 Intel E8870로 지금까지와 다르지 않다.
Montecito에서 멀티 쓰레딩 기술을 도입
Montecito의 CPU 코어는 기본적으로 Itanium2 (McKinley / Madison) 계의 아키텍처로 되어 있다. 명령 발행 포트와 실행 유닛은 Itanium2 같은 11이다. 그러나 Itanium2와 다른 점도있다. 눈에 띄는 것은 레지스터 등 자원의 이중화. 정수 레지스터, 부동 소수점 레지스터, 분기 레지스터, 예측 레지스터 등, 아키텍처럴 자원이 모두 이중화 되어있다. 또한 L1 캐시의 TLB도 확장되어 있다. 이것은 멀티 스레딩 때문이다. (보통의 (단일 스레드 = 물리1코어 논리1코어) CPU는 하나의 스레드 상태만을 가집니다. 그래서 여러개의 작업을 시키면 각 작업마다 전환을 해가며 번갈아 실행을 합니다. 스레드 상태를 1개밖에 가지지 못하니까요. 일반적인 CPU도 물론 그럼에도 여러개의 스레드를(태스크를) 우리가 보는 눈으로는 동시에 실행이 됩니다. 1코어 CPU에 멀티스레딩이 안되는 펜3로도 멀티태스킹을 잘했죠. 노래 틀어놓고 인터넷하기라던가, 노래 틀어놓고 게임이나 문서작성하기 등 처럼요. 그러나 멀티 스레딩을 지원하는 것과 아닌 것은 실제 CPU 내부에서 처리하는 것은 다릅니다. 하드웨어적으로 엄밀하게 정말 동시에 실행하려면 코어수 자체가 많던가, SMT를 지원해야 합니다. 일반 CPU들은 보기에는 동시 실행이지만, 실제로는 번갈아 실행을 하는 거죠. CPU의 성능이 괜찮다면 번갈아 실행을 해도 끊김이 없죠.)
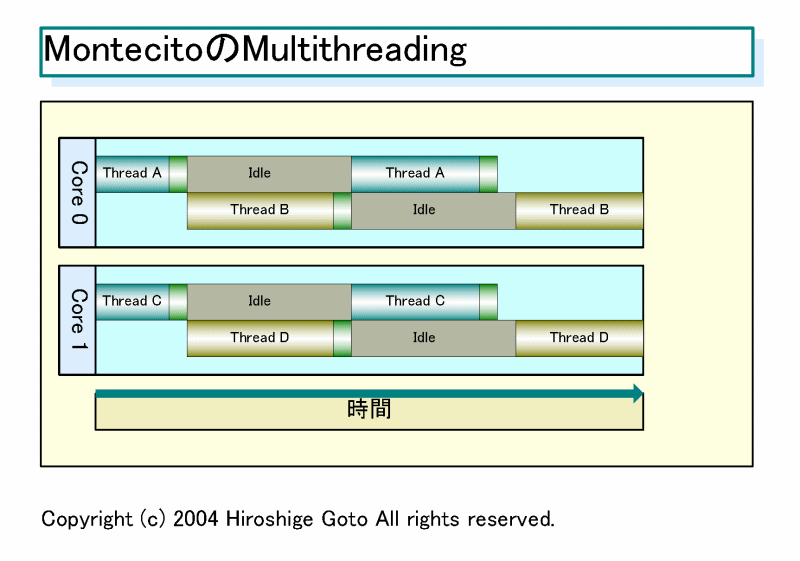
Montecito의 멀티 스레딩
우선, Montecito가 채용한 Coarse-Grain Multithreading은 비교적 간단한 멀티 스레딩 기술이다. Hyper-Threading 등의 SMT (Simultaneous Multithreading) 기술은 여러 스레드의 명령을 동시에 실행하는 것이 가능하다. 반면, Coarse-Grain에서는 여러 스레드에서 파이프 라인의 시분할을 행한다. (대부분 보통 그냥 멀티 쓰레딩 이라고 써있으면.. SMT가 아닌 경우가 많습니다. 하이퍼쓰레딩 = SMT는 동시에 실행 합니다. 다시 말하면 멀티 스레딩이 있으면, 그 안에서 SMT 같은 멀티 스레딩도 있고, 몬테시토 같은 멀티 쓰레딩도 있는거죠. 보통의 명칭이 SMT 이지만, 인텔은 자사에 어떤 것을 넣으면 이름을 붙이는 경우가 많습니다. 그래서 SMT라 하지 않고 하이퍼 스레딩 이라고 붙였습니다.)
통상 L3 오류나 캐싱이 불능인 액세스가 발생하는 경우, CPU 코어는 메인 메모리까지 접근해야 하기 때문에, 매우 긴 레이턴시가 생긴다. 기존의 단일 스레드 CPU는 이러한 경우 데이터 로드를 기다리며 처리를 재개, 그뒤에 다음 스레드로 전환한다. 따라서 액세스 대기간 CPU 코어는 아이들 상태가 되어 버린다. Intel에 의하면, 응용 프로그램에 따라서 이 아이들 상태가 CPU 사이클의 대부분을 차지 한다고 한다.
그래서 Coarse-Grain 멀티 스레딩에서는 메인 메모리 액세스 같은 긴 레이턴시의 이벤트가 발생한 시점에 다른 스레드 처리를 전환한다. 그때 액세스 대기하고 있는 쪽 스레드의 아키텍처럴 스테이트 (레지스터 내용 등)은 그대로 유지한다. 두번째 스레드를 다른 독립된 아키텍처럴 스테이트로 실행한다.
Montecito가 레지스터 세트 등을 이중화 하고 있는 것은 그 때문이다. SMT와 마찬가지로 2개의 스테이트가 유지되기 때문에 Coarse-Grain 멀티 스레딩도 외견상 1개의 물리 CPU 코어가 2개의 논리 프로세서로 보인다.
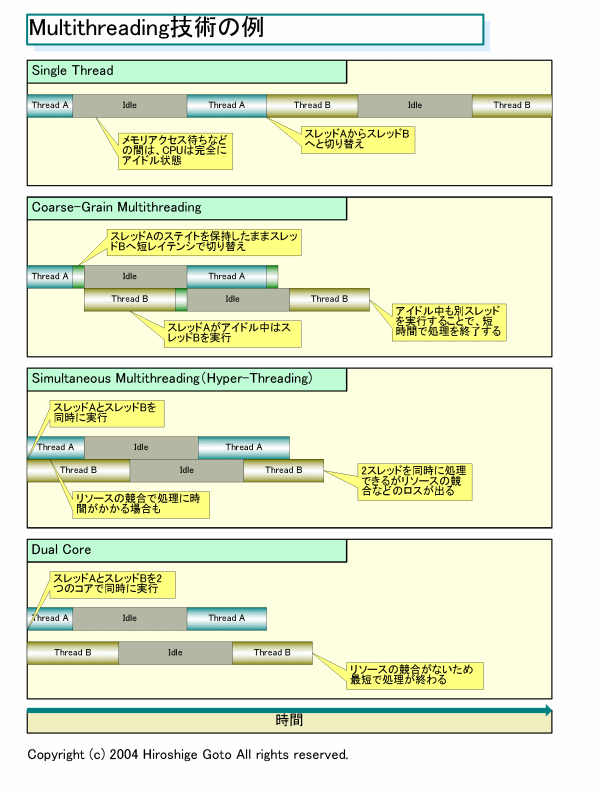
멀티 스레딩 기술의 예
(주의 위 그림은 각 스레드를(태스크,작업) 설명하는 것이지, 스레드 안의 명령을 동시에 여러개 실행하는가? 와는 다른 문제 입니다. 슈퍼스칼라 아키텍처 위에서 구현되었다면 , Coarse-Grain 멀티 스레딩도 각 스레드는 돌아가면서 실행하지만, 각각의 스레드의 여러 명령을 동시에 실행 합니다. 동시 멀티 스레딩인 하이퍼스레딩은 반드시 슈퍼스칼라에 구현되어야 함. 1코어에서 2개의 스레드(작업)의 명령을 1코어안에서 동시에 실행하려면 당연히 여러 명령을 실행 가능한 슈퍼스칼라 아키텍처야 하겠죠. 그냥 슈퍼스칼라 이기만 하면 1스레드의 명령 안에서 동시에 여러 명령을 1코어에서 실행하는 것이고, SMT는 2개의 스레드의 명령을 1코어에서 동시에 실행 하는 겁니다.
또 3번 그림의 SMT CPU는 2번 처럼 작동하는 순간도 당연히 있습니다.)
(가장 위가 일반 CPU들 작동방식. 2번째가 아이테니엄 방식. 3번째가 하이퍼쓰레딩.
4번째가 듀얼코어. 프로그램 실행 입장에서는 하이퍼쓰레딩과 듀얼코어는 같음. 1번째와 2번째는 각각의 쓰레드가 돌아가면서 실행되지만, 몬테시토와 같은 멀티쓰레딩 방식은 2개의 쓰레드를 다룰수 있기에 각각의 쓰레드를 빠른 시간에 전환하며 실행가능. 3번째와 4번째는 동일하게 2개의 쓰레드(태스크)를 동시에 실행하지만, 하나의 코어의 자원을 공유해서 나눠쓰며 2개의 쓰레드를 동시에 실행하는 SMT 방식과 별도의 코어에서 코어마다 각각 1스레드씩 2코어니까 2개의 쓰레드(태스크)를 동시에 실행하는 것의 차이.
2번째의 멀티스레딩 방식을 파이프 라인의 처리에서의 단계별 연속 실행이나 슈퍼스칼라 실행, 또는 SMT가 아닌 멀티스레딩과 혼동 금지.
슈퍼스칼라는 하나의 작업의 명령을 여러개 동시에 실행하는 것이고, SMT는 여러 명령을 동시에 실행 할 수 있는 슈퍼스칼라 아키텍처에서 2개의 작업안에서(스레드) 동시에 처리가 가능한 명령을 동시에 실행하는 겁니다.
SMT가 아닌 비동시 멀티스레딩은 스레드를 번갈아 가면서 실행하기 때문에 동시에 여러 명령을 실행 할 수 있는 슈퍼스칼라여도 아니어도 가능 합니다. 어짜피 각 스레드를(작업) 동시에 실행하지 않으니까요. (눈으로 보기에는 체감으로는 동시에 실행 되지만.. 이건 멀티스레딩이 아닌 펜3에서도 실행해도 보기에는 동시에 실행.)
무나 위키의 설명은 정체 불명으로 되어 있죠. 파이프라인화에 대해서 설명하는거 같기도 하고... 명령의 종속성을 얘기하는거 보면 아웃 오브 오더를 설명하는거 같기도 하고.... SMT가 없으면 하나의 명령만 실행 가능하다고 하는거 보면 슈퍼스칼라 설명도 아니고... 2개의 작업을 동시에 실행하는게 아니라고 하는거 보면 SMT가 아닌 비동시 멀티스레딩에 슈퍼스칼라도 아닌 CPU를 말하는거 같기도 하고 (나이아가라 같은)..
짬뽕으로 설명...... 무엇보다 SMT(동시멀티스레딩/ 하이퍼스레딩 )인데 동시에 2작업을 실행하지 못하는 진정한 멀티태스킹이 아니라니....
무엇보다 (동시든 아니든) 멀티 스레딩이 지원되는 경우와 안되는 경우는 동시에 2개의 스레드 상태를 가질 수 있냐 없냐의 차이부터가 크고, 동시에 2개의 작업을 실행하기 때문에 동시 멀티 스레딩(SMT)인 것인데..... 다른 글은 몰라도 최소한 무나 위키의 SMT (하이퍼스레딩) 글은 믿고 거르세요. (SMT라고 해서 꼭 2개만 가능한건 아니지만.. 만들기 나름으로 4스레드 동시 멀티 스레딩도 가능. 하이퍼 스레딩으로 말하다 보니..)
. 하이퍼스레딩은(SMT) 여러 명령을 동시에 실행 가능한 슈퍼스칼라 아키텍처 위에 구현되기 때문에 비어있는 시간에 다른 스레드를 실행하는 것이 아닙니다. 2개의 스레드의 명령을 동시에 실행합니다. 슈퍼스칼라는 기초는 가장 아래의 링크 글을 읽으세요.
메모리 레이턴시의 은폐에 주안점을 둔 기술
다만 SMT는 여러 스레드의 명령을 완전히 혼재시켜 실행 할 수 있지만, Coarse-Grain 멀티 스레딩은 그렇지 않다. 스레드 0이 스톨하는 동안 스레드 1을 달리게 하는 정도로, 동일 사이클에서 2개의 스레드의 명령을 혼재시켜 실행 할 수 없다. 즉, 2스레드 / 사이클은 불가능 하다. 각 스레드는 같은 사이클에서 다른 스레드와 실행 자원을 공유하지 못한다는 의미다.
그러나 액세스 대기로 CPU 코어가 스톨하고 있는 시간에 다른 스레드를 실행할 수 있으므로 CPU 코어를 더 바쁘게 할수 있다. CPU 코어 측에서 보면 메모리 대기의 아이들 상태를 어느정도 해소 가능하기 때문에 외견상 메모리 레이턴시가 은폐된다.
IA-64의 경우 정적 스케줄링으로 명령 병렬성 (Instruction Level Pararelism : ILP)을 높이고 있기 때문에, SMT처럼 여러 스레드로 부터 병렬 가능 명령을 추출해 명령 슬롯을 채울 필요가 적다. 그러나 메모리 레이턴시의 페널티는 IA-64에도 근본적으로 해소 할 수없다 (로드 명령을 저장 명령이나 분기 명령 전에 실행하는 것은 가능하다). 따라서 메모리 레이턴시의 은폐에 효과가 있는 Coarse-Grain 멀티 스레딩을 채용한 것으로 보인다.
또 IA-64 프로세서는 스케쥴링을 컴파일러가 행하기 때문에, 동적 명령 스케줄링 기구를 가지지 않는다. 따라서 SMT에서 여러 스레드를 명령 수준에서 혼재 시키기 위해 동적으로 스케줄링을 행하는 리소스의 추가가 필요하게 된다. Intel에 의하면 Montecito에서는 코어를 2% 늘린 것만으로 Coarse-Grain 멀티 스레드가 실현됐다고 한다. Coarse-Grain 멀티 스레딩은 최소의 비용으로 IA-64에서 어느정도 유효한 멀티 스레드를 실현하는 수단이었다고 말할 수 있다. 또한 IA-64에 SMT를 도입하는 경우, 모처럼 종속관계가 없는 명령을 추출해 명령 그룹 "Bundle (번들)"단위로 정리한 것을 어느정도 흐트려 스케쥴링하는 하는 것이 된다. (IA-64쪽은 하드웨어 스케줄러에 써야할 회로 자원을 전부 실행 유닛 증가로 돌리고, 컴파일러에 의해서 최대 동시 실행을 얻어서 성능을 높이자 라는 사상으로 개발. x86 쪽은 CPU 내부에서 하드웨어 적으로 별도로 스케쥴링을 하게 됩니다. 물론 x86쪽도 아무리 CPU 코어 내부에서 하드웨어적으로 최적화를 한다고 해도, 컴파일러에 따른 성능 차가 꽤 나옵니다. 인텔 컴파일러를 사용하는 경우가 GCC를 쓴 경우보다 많게는 40% 정도 더 빠르게 실행 됩니다. 인텔 CPU이던, AMD CPU이던 간에요. (GCC대비 인텔쪽이 약간 폭이 더 차이나는 부분도 있고, AMD쪽이 약간 더 차이나는 부분도 있고 그런식. 같은 명령을 처리가 가능한 것이지 서로 마이크로 아키텍처는 다르기에. 이말은 같은 인텔 CPU라도 아키텍처 마다 차이가 다를 수 있다는 것과 같은 뜻이죠.) 물론 이런 성능 차이는 각각의 컴파일러 개발에 의해 시대에 따라서 변하겠지만요.)
멀티 스레딩은 이밖에도 여러 스레드의 명령을 1 사이클마다 바꿔 실행하는 "Fine-Grain 멀티 스레딩" 기술도 있다. IA-64 아키텍처의 경우에도 Fine-Grain 멀티 스레딩은 비교적 쉽게 구현할 수 있는 것으로 추측된다. Fine-Grain은 Coarse-Grain보다 효율적으로 아이들 상태를 해소 할 수 있지만, Montecito에서는 채용하지 않았다. 그 이유도 IA-64 바이너리의 최적화를 무너 뜨리지 않으려 하기 때문이라 생각된다. IA-64에서는 레이턴시를 고려해 스케쥴링을 하기 때문에 어느정도의 입도를 유지하지 않으면 모처럼의 최적화가 무너져 버린다.
Montecito는 듀얼 코어와 Coarse-Grain 멀티 스레딩에 의해 스레드 병렬성 (TLP)을 강화한다. 기존 Itanium2가 1CPU 코어였던 반면 Montecito는 물리적으로 2CPU 코어, 논리적으로 4CPU 코어가 된다. 물리적 리소스를 늘려 멀티 스레드 성능을 향상시키기 위해 듀얼 코어를 도입하고, 메모리 레이턴시의 은폐에 코어 내에서 멀티 스레딩을 쓴다 라는 배치다.
아마도 이것은 향후 CPU의 큰 트렌드가 될 것이다. Intel의 데스크탑용 듀얼 코어 CPU "Smithfield (스미스필드)"는 현재는 Hyper-Threading이 활성화 여부는 모른다. 그러나 장기적인 트렌드는 아마도 멀티 코어 + SMT로 향하는 것이다. 듀얼 코어만으로는 메모리 레이턴시에 의해 각 코어의 실행 효율이 떨어져 버리기 때문이다. (펜티엄D 계열에서는 스미스필드(90나노) 프레슬러(65나노) EE 버전만이 듀얼코어 + SMT 제품 입니다. 그냥 D 제품들 800(스미스필드), 900(프레슬러) 시리즈는 듀얼코어 CPU)
Pentium Extreme Edition 965 @ 4,8GHz vs. DOOM (2016)
SpeedStep 비슷한 절전 기술도 도입
Montecito에는 이 외에도 새로운 기술이 일부 도입 된다. SpeedStep 비슷한 전압 및 주파수의 동적 전환 기술 "Foxton (폭스톤) "기술, 가상 머신 지원 하드'Silvervale (실버 베일)"기술, 캐시 오류 검사 메커니즘 "PELLSTON (펠스톤)"기술 등이다.
Foxton는 동적으로 CPU의 전압과 주파수를 바꾸는 기술로, 기본적으로 SpeedStep과 같다. 디만 모바일 CPU의 SpeedStep이 평균 소비 전력을 낮추기 위해 사용되는 반면, Foxton는 CPU의 소비 전력 한도 (Power Envelope)를 내리거나 제어하기 위해 사용된다. 이 점은 Intel 데스크톱 CPU의 Pentium 4 6xx에 도입하는 "Enhanced Intel Speedstep Technology (EIST)"에서도 마찬가지라고 생각된다.
Foxton의 구조는 비교적 단순하다. CPU의 소비 전력이 규정의 테두리 (Power Envelope)를 초과하거나 CPU 온도가 기본값을 초과하면 Montecito는 자동으로 전압 (& 주파수)을 낮추기 시작한다. 전력 소비가 Power Envelope까지 내려 가면 그 상태를 유지 가능한 전압을 유지한다. CPU의 부하가 낮아 소비 전력이 Power Envelope을 밑돌기 시작하면 어느 정도의 지연 시간 후 전압을 상승시킨다. 그리고 보통 상태에서는 최고 주파수를 유지할 수 있는 최저 전압을 유지한다.
Foxton의 도입에 의해 Montecito에서는 Power Envelope을 기존 Itanium2의 130W에서 100W로 낮췄다 (Montecito에서 Power Envelope는 OEM이 설정 가능하기 때문에 100W는 어디 까지나 Intel의 규정 값). 즉, 0.13μm에서 싱글 코어 Itanium2이 130W인 반면, 90nm의 Montecito 코어가 듀얼이 되었음에도 불구하고 100W로 억제된 것이다. 이것을 보면, EIST 의해 Smithfield의 TDP도 상당히 낮아질 가능성이 있다. 전회 칼럼의 예상은 틀렸을지도 모른다. 또한 Power Envelope이 100W라는 것은 결국, Itanium 시스템이 Pentium 4계 보다 소비 전력이 내려간 것을 의미한다.
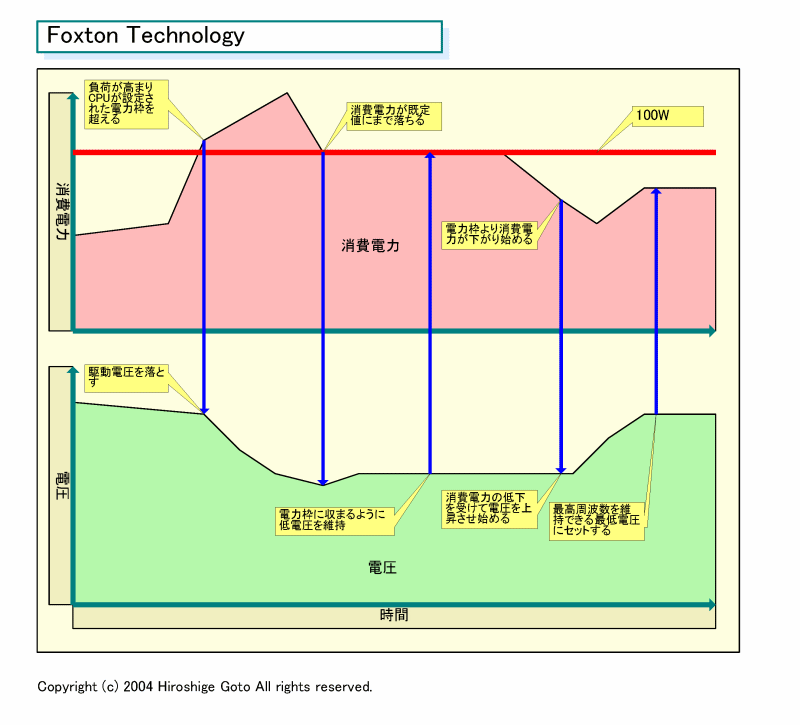
Foxton Technology
Silvervale는 Intel 데스크톱 CPU에 도입하려 하고 있는 "Vanderpool (벤더풀 = 인텔 VT-x)"과 유사한 기술이다. 가상 머신 매니저 (VMM : Virtual Machine Manager) 소프트웨어를 하드웨어로 지원한다. 다만 이전 Intel 관계자는 Silvervale은 Vanderpool보다 기능적으로는 강화 될 것이라고 말했다. IBM이 메인 프레임 z 시리즈에서 도입하고 있는 등의 고급 가상 머신 기술을 가져 온다 말했다.
Silvervale도 기구적으로는 아마도 CPU에 새 특권 수준을 만들어 그 수준에서만 사용할수 밖에 없는 기능을 제공하는 것으로 실현하는 것으로 보인다. 따라서 같은 계열의 기능확장 위에 하드웨어 보안 기능도 실장할 것으로 예상된다.
이처럼 Montecito는 듀얼 코어, (코어 내에서의) 멀티 스레딩, 동적 전압 및 주파수 전환, 가상 머신 지원 등 기술을 가득 채운다. 이들 기술은 기본적으로 IA-32 측의 Prescott / Smithfield 세대와 같다. 즉, IA-32나 IA-64와 같은 명령 세트 아키텍처의 차이에도 불구하고, Intel CPU는 같은 방향으로 향하고 있다. 이들 기술이 Intel 전체의 기술 트렌드라는 것이다.
2004년 9월 6일 기사 입니다.
[분석정보] 멀티 코어 + 멀티 스레드 + 동적 스케줄링으로 향하는 IA-64
[고전 2002.10.04] Pentium 8 후보 Nehalem 아키텍처
[고전 2003.10.18] 모든 CPU는 멀티 스레드로, 명확하게 된 CPU의 방향
[정보분석] Penryn의 1.5 배 CPU 코어를 가지는 차세대 CPU "Nehalem"
[고전 2002.09.12] Hyper-Threading Technology를 지원하는 HTT Pentium 4 3.06GHz
[분석정보] AMD의 차세대 CPU Bulldozer의 클러스터 기반 멀티 스레딩
[분석정보] 아이테니엄(Itanium)을 둘러싼 불안과 기대
[분석정보] iAMT, Montecito등 신기술이 공개된 IDF
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 1/2
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 2/2
[분석정보] 슈퍼 스칼라에 의한 고속화와 x86의 문제점은
[분석정보] 명령의 실행 순서를 바꿔 고속화 하는 아웃 오브 오더
[분석정보] x86을 고속화하는 조커기술 명령변환 구조
[분석정보] CPU와 메모리의 속도 차이를 해소하는 캐시의 기초지식
[분석정보] 캐쉬 구현 방식으로 보는 AMD와 인텔이 처한 상황
[고전 1997.10.31] Intel과 DEC 전격 제휴 MPU의 판도가 바뀐다
'벤치리뷰·뉴스·정보 > 고전 스페셜 정보' 카테고리의 다른 글
| [고전 2004.11.05] 폴락의 법칙을 깨뜨리기 위한 멀티 코어 (0) | 2005.12.11 |
|---|---|
| [고전 2004.10.22] 듀얼코어 CPU Smithfield 내년 3분기에 등장 (0) | 2005.12.10 |
| [고전 2004.09.13] 32bit 시스템의 EFI 화는 2006년 (0) | 2005.12.09 |
| [고전 2004.09.10] iAMT, Montecito등 신기술이 공개된 IDF (0) | 2005.12.09 |
| [고전 2004.07.21] 인텔 90nm 펜티엄 M 755 Dothan (0) | 2005.12.06 |
| [고전 2004.06.03] Intel 915에서 AGP에 대응하는 제품이 전시, ATI의 미발표 노스 브리지도 (0) | 2005.12.06 |
| [고전 2004.06.02] Socket 754/939 듀얼 소켓 사양의 제품이 전시 (0) | 2005.12.06 |
| [고전 2004.06.01] AMD Socket 939 대응 Athlon 64 FX, Athlon 64를 발표 (0) | 2005.12.06 |