PCI Express x16이 AGP 8X의 후계
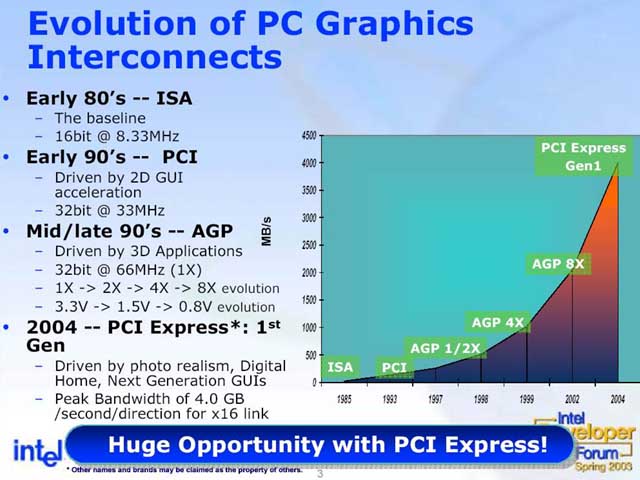
그래픽 인터페이스의 진화
Intel은 2월 18일부터 미국 산호세에서 개최하는 "Intel Developer Forum (IDF)" 에서 그래픽 용 PCI Express 플랫폼 디자인의 개요를 발표했다.
Intel은 2004년의 칩셋부터 칩셋에 새로운 시리얼 버스 "PCI Express"를 도입한다. PCI-SIG의 Tony Pierce 씨 (Chairman of the Board)에 따르면, 최초에 PCI Express를 끌고 가는 것은 그래픽이 될 것이라 했다. 실제 Intel은 우선 GPU의 연결에 PCI Express를 도입 할 전망이다. 따라서 GPU와 비디오 카드는 앞으로 1년 정도 단숨에 PCI Express 향해 이동을 시작하게 될 것 같다. 이미 이를 위한 초읽기가 시작되고 있다.
PCI Express는 상향 하향 1쌍의 통신 채널 (레인)을 기본으로 구성한다. 1쌍의 x1부터, 레인 수를 늘려 확장 대역을 늘리는 것이 특징이다 (인터넷에는 1배속은 단방향이고, 1배속이 2개인 2배속이 양방향이다 라고 잘못 알려져 있기도 합니다. 엔비디아 GPU 400 (페르미 아키텍처) 시리즈 부터 PCI-E의 양방향 인터페이스를 제대로 쓸 수 있게 CPU -> GPU, GPU -> CPU 데이터 전송을 동시에 수행 합니다. 엔비디아는 이것을 GigaThread Streaming Data Transfer (SDT) Engine 라고 부르구요..).
[PCI Express 및 AGP의 대역]
| 명칭 | 대역 (양방향) | 대역(단방향) | ||
| x1 (1배속) | 500MB / Sec | 250MB / Sec | ||
| x2 (2배속) | 1GB / Sec | 500MB / Sec | ||
| x4 (4배속) | 2GB / Sec | 1GB / Sec | ||
| x8 (8배속) | 4GB / Sec | 2GB / Sec | ||
| x16 (16배속) | 8GB /Sec | 4GB / Sec | ||
| AGP 4X | 1GB / Sec | 1GB / Sec | ||
| AGP 8X | 2GB / Sec | 2GB / Sec | ||
GPU의 연결에 사용되는 것은 이 가운데 "PCI Express x16"이다. AGP 8X의 전송 속도는 피크 2.1GB / sec. 이에 비해 PCI Express x16에서는 단방향 피크 4GB / sec, 양방향이라면 8GB / sec 이다. 칩셋부터 GPU로의 데이터 전송만을 생각한다면 AGP 8X의 2배, 양방향 데이터 전송이라면 4배의 피크 대역이다.
FSB와 균형이 잡히는 PCI Express x16
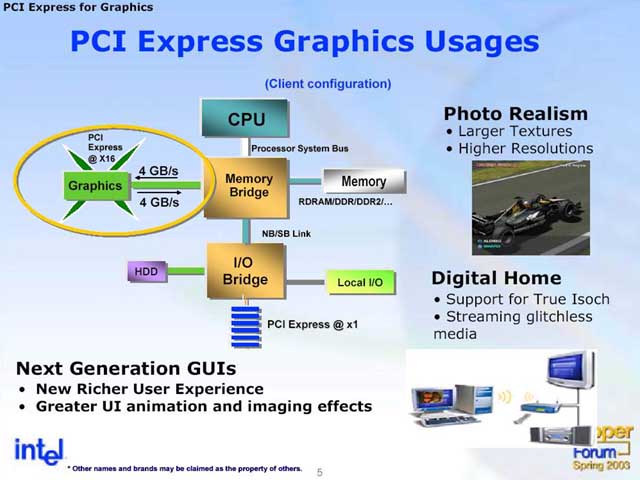
PCI Express 그래픽
PCI Express가 단방향 전송이면 대역이 반이 되어 버리는 것은, 1 레인이 상향 하향으로 나눠져 있기 때문. 즉, 1레인의 한쪽은 상향 전용, 또 1레인의 다른쪽은 하향 전용이다. 이에 비해 AGP는 양방향 버스이므로 칩셋에서 GPU에 그냥 단방향 전송만으로도 충분히 대역을 사용할 수 있다. 즉, 칩셋에서 GPU에 대해 단방향 데이터 전송으로 치우친 그래픽의 연결에서는 PCI Express는 다소 아까운 사용법이다.
다만, 단방향으로도 AGP 8X의 2배에 달하는 PCI Express x16 대역폭은 지금으로는 "오버 킬"(과잉)이다. 지난해까지의 AGP 4X와 비교하면 4배되는 것으로, 당장은 많은 응용 프로그램이 대역을 쓸수는 없을 것이다.
하지만 PC 시스템 전체에서 보면, PCI Express x16은 특별히 오버 킬은 아니다. 오히려 겨우 다른 버스를 따라 잡았다고 말할 수 있다. 예를 들어, PCI Express 도입시에는, FSB (Front Side Bus)는 1,066MHz에서 대역은 8.5GB / sec로 메모리는 듀얼 채널 DDR2-533에서 마찬가지로 8.5GB / sec에 달할 것으로 보인다. 그렇게 되면 양방향으로 8GB / sec의 PCI Express x16은 대역으로 꼭 맞는 모습이다. 단방향의 4GB / sec로 비교하면 3개의 버스 대역이 맞는 것은 AGP 4X와 133MHz FSB, PC133 SDRAM로 균형했던 때 이후 (처음)이다. 즉, FSB와 메모리의 대역 향상과 비교하면, 속도가 늦었던 그래픽의 대역이 이제 겨우 따라 붙었다는 견해도 있다.
그럼에도 Intel은 최초의 PCI Express x16은 아직 시작에 지나지 않는다는 것이다. PCI Express의 링크의 전송을 현재의 2.5Gb / sec 에서, 2배인 5Gb / sec 및 4배인 10Gb / sec로 미래 고속화해서 AGP처럼 광대역 화 할 수 있다고 설명한다. 아직까지, 헤드룸이 있다는 것이다. 다만 그 시점에는 FSB도 고속화 할 필요가 있다. (2.5Gb 라면 2.5G / 8 (Byte 변환) = 단반향 312MB/s 가 나와야 하는데, 250MB/s 인 이유는 8/10 인코딩으로 실제 데이터는 80% 이기 때문 입니다. PCIe 2.0은 5Gbps 로 그대로 2배가 되어 500MB/s 이며, 3.0은 10Gbps 이 아닌 8Gbps 인데, 3.0에서 128/130 인코딩 방식 변경으로 98.4% 이상이 실제 데이터로, 거의 10Gbps 전부의 실제 전송 효율을 갖습니다. 10Gb/s 면 /8 (바이트 변화) 해서 1GB/s 인데, 인코딩 128/130 98.4%가 실 데이터이니까 0.984 GB/s 가 되죠. 3.0이 정확하게 2.0의 2배는 아니지만, 그냥 2배라고 해도 무방한 정도죠.)
GPU 벤더도 대응
GPU 벤더도 이미 PCI Express 지원을 발표하기 시작했다.
ATI Technologies가 IDF에서 행한 프레젠테이션에서는 PCI Express 대응 카드의 메카니컬 샘플 사진을 보이며 "전 제품 라인에, 최고에서 최하에 PCI Express를 도입 할 것 "(ATI Technologies, Gord Caruk, Architect, ASIC Design)이라 설명했다.
S3 Graphics도 PCI Express 지원을 서두른다. S3 Graphics는 DirectX 9세대 GPU 코어 "Columbia (콜롬비아)"의 모바일 버전으로 "DeltaChrome"을 발표하고 있는데, PCI Express 버전 "DeltaChrome2"도 올해 4분기 샘플 출하 예정으로 진행한다. Trident Microsystems도 2004년 여름에 PCI Express를 지원하는 DirectX 10세대 GPU를 출시한다고 한다.
칩셋 측은, 동작 검증을 위해 칩셋 출하의 상당히 전에 새로운 인터페이스를 지원하는 GPU가 필요하다. 내년 중반의 PCI Express 칩 세트 용으로, 아마 올해 안에 PCI Express 대등 GPU 샘플이 나오기 시작할 것이다. 참고로, AGP 8X 때에는 ATI가 검증에 사용되고 있었다.
60W까지 전력 공급도 OK
IDF에서 설명한 AGP 8X와 PCI Express x16의 스펙 비교는 그림 1과 같다.
여기서 눈에 띄는 것은 비디오 카드에 공급 전력이 기존의 AGP의 25W에서 60W로 오른 것. 이것은 전력 공급이 AGP와는 크게 다르기 때문이다. PCI Express x16에서는 + 5V 공급은 없어졌다. + 3.3V와 + 12V로 공급한다. 다만 아날로그 출력에는 여전히 5V가 필요하므로 디지털 출력 전용이 아닌 한, 카드 측에서 5V를 생성하지 않으면 안된다. 3.3V에서 3A, 12V에서 4.4A를 공급하는 것으로 카드에 전력 공급은 약 60W가 된다. 12V로 고전압인 전력 공급을 깨끗이 하는 것은 장벽이 높아 보인다.
다만 그 이상으로 문제가 되는 것은, 60W의 전력을 소비하는 GPU의 열 처리. 허용량 한도인 60W 급의 GPU에 이르면, CPU 같은 열을 방출하는 것으로, 원리적으로는 CPU와 같은 열 처리가 필요하다. 실제로 이미 NVIDIA의 "GeForce FX 5800 Ultra (NV30)"에서는, 고 소비전력이기 때문에, 보드에 강력한 팬을 쓰며 본체 외부로 열 처리를 하는 기구를 설치한 형태를 취했다.
그에 비해, IDF에서는 본체에 GPU 용 팬 덕트를 붙이는 방식을 제안한다. 즉, 현재의 Intel의 권장으로 CPU 팬 덕트를 달고 있는 그 아래에 GPU 용 팬 덕트를 내겠다는 것이다. 그림 2가 그 것이다. CPU 같은 뜨거운 GPU에는 같은 솔루션 이라는 것이다.
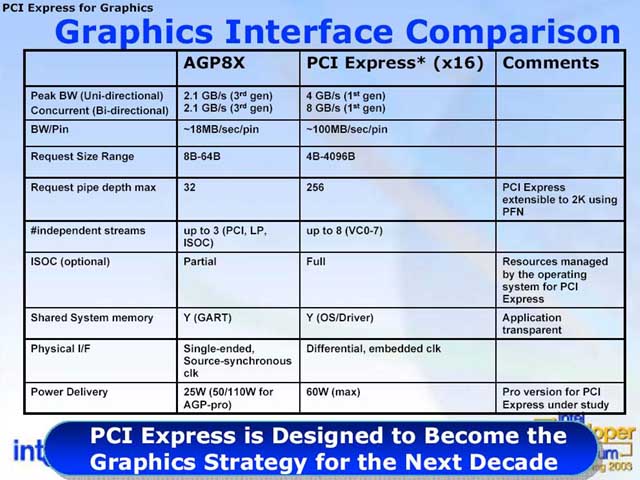
[그림 1] PCI Express x16와 AGP8x 비교

[그림 2] GPU 덕트 디자인
미래 비디오 카드의 소비 전력은 150W?
하지만 문제는 이것으로는 해결되지 않을지도 모른다. 이말은 향후의 하이엔드 비디오 카드의 소비 전력과 열은 PCI Express x16로 커버 할 수 있는 범위를 초과 할 가능성이 있기 때문이다.
Intel에 이어 프레젠테이션을 진행한 ATI가 IDF 참석자용 Web 사이트에 업로드 한 프레젠테이션에는 하이엔드 GPU의 소비 전력은 향후에도 계속올라, 2 ~ 3년 안에 100W를 초과 할 것으로 예상 된다고 했기 때문이다. 또한 열 처리 기구 때문에 무게가 늘어나는 카드를 지탱하기 위한 지지 기구도 ATI는 제안했다. 아래의 프레젠테이션이 그것이다.
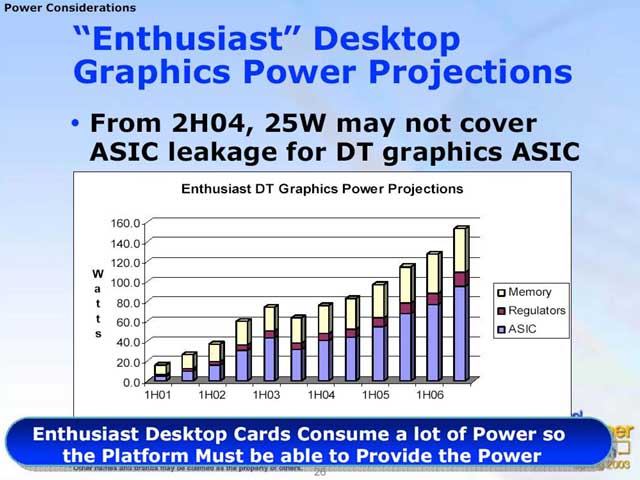
GPU의 소비 전력
지지 기구
여기서 재미있는 것은, 실은 이러한 프레젠테이션 시트는 실제 강연에서는 표시되지 않은 것. ATI의 강연에서, 이 2 개의 시트는 잘렸을 뿐 아니라, 전력 및 열 문제도 PCI Express에서 거의 괜찮다 라는 내용으로 바뀌어 있었다. 또한 프레젠테이션 자체도 실제로 강연 된 것으로 바뀌어 버렸다. 즉, 환상의 프레젠테이션이 되어 버린 것이다.
그 이유는 명백하다. ATI의 첫 번째 프레젠테이션 파일대로라면 PCI Express x16도 전력 공급의 측면에서 단기적인 해결책에 지나지 않고, 바로 플러스 알파의 전력 공급을 보장하는 개선책이 필요하기 때문이다. Intel에서는, 그것은 OEM 업체에 대해 바람직한 설명이 아닌 것이다.
그러나 여기서 흥미로운 것은 ATI가 GPU 비디오 카드의 소비 전력이 이만큼 늘어난다고 예측을 가지고 있다는 것이다. 우선, 2002년 후반에 60W까지 도달하는 선이 RADEON 9700 Pro (R300)라고 생각된다. 그렇다면, 2003년 상반기 70W의 선이 R350이 된다. 다음 선에서 다소 떨어지는 것은 0.13μm로 미세화 하는 R400으로 전환 때문일 것이다. 하지만 그후는 R500에 해당하는 세대에서 80W, R600에 해당하는 세대에서 110W, R700에 해당하는 세대에서 150W로 성장한다고 예측한다.
이 예측은 ATI의 칩 물리 설계 전문가가 말하는 것이기 때문에 설득력이 있다. 즉 ATI가 개발 중에 있거나 향후 개발 예정인 GPU의 게이트 규모가, 이러한 방향으로 증대해 간다는 예특이 있다고 생각한다. 실제로는, TDP (Thermal Design Power : 열 설계 전력)는 이보다 낮다고
해도 소비 전력은 격렬하다.
설계상 주의가 필요한 PCI Express x16

PCI Express x16 커넥터
또 Intel은 PCI Express x16에는 광대역 이외에도 장점이 있다고 설명한다.
포인트 중 하나는 광대역화를 최저 비용 증가로 실현하는 것. Intel의 설명에서는 PCI Express x16의 커넥터는 164핀에 길이 89mm로 현재의 AGP 커넥터와 크게 다르지 않다고 한다. 칩에 내장하는 인터페이스의 실리콘 비용도 AGP와 같은 수준이라고 한다.
여기에 Intel은 보드의 배선도 쉽게 되는 것을 강조한다. 현재 AGP는 병렬 버스이기 때문에 배선 길이를 맞추는 등장배선(같은 길이의 배선)이 필요하다. 따라서 큰 배선 면적을 차지한다. 또 타이밍 여유도 좁기 때문에 설계가 어렵다 (메인보드 메모리 배선을 보면 어느건 좀 덜 구불하게 가는데, 어느 선은 많이 구불구불 하게 되어 있죠. 각 핀의 거리가 있어서 실제 위치가 다른데, 메모리 컨트롤러와 연결되는 최종 길이를 같게 하기 위해서 그렇습니다. 신호를 한번 보내고 끝내는 거면, 어느 한 신호가 늦게 와도 다 들어오면 처리한다 식으로 할 수 있지만, 클럭마다 계속 신호가 들어가야 하는데, 그럴 수가 없죠. 클럭이 아주 느리면 약간의 타이밍 차이가 있어도 괜찮은데, 클럭이 높아질 수록 약간의 타이밍 차이로 인해서 결과가 다르게 나오거나, 에러가 날 수 있습니다. 그래서 병렬 버스는 선의 길이를 최대한 완벽하게 맞춰야 합니다. 병렬신호는 신호선이 여러개 있고 (가로로) 1 0 1 0 1 1 1 0 이렇게 8개 신호선에서 동시에 신호를 보내는 것이고, 직렬은 신호선 한개로 세로로 1 0 1 0 1 1 1 0 보내는 거죠. 같은 전송 속도가 되려면 직렬은 8배의 클럭으로 보내야 하죠. 대신 배선의 길이를 맞추거나 할 필요가 없구요. 그런데 클럭도 한계가 있고, 할 수 있다고 해도 보드 가격이 매우 높아지겠죠. 그러니까 그냥 단순 직렬이 아니라, 직렬을 1레인 2레인 4레인 8레인 16레인 이렇게 각각을 여러개 둬서 더욱 데이터 전송량을 늘린다는 겁니다.
사족으로 이러한 이유로 인텔은 메모리도 직렬화 시켜려고 했었죠. PC는 당장 어렵고, 그래서 우선 서버용 레지스터드 메모리부터 직렬화 하려고 했습니다. 어짜피 서버용 메모리에는 버퍼용 칩이 별도로 메모리 모듈에 달리는데, 그 버퍼용 칩에 직렬화 기능을 추가해서 만들자 라구요. 어짜피 1칩이 추가 되어야 하니까요. 그런데 별로 메모리 업체에게 지지를 못받고 잠깐 있다가 없어졌습니다. 예전 PC에 있는 (요즘도 간혹 몇몇 보드에 있기도 한) 시리얼 포트와 패러렐 포트를 생각해도 되죠. 패러렐 포트의 케이블 최대 길이보다 시리얼 포트의 최대 길이가 훨씬 길죠. 그래서 단거리 프린터 라던가 처럼 근처에 있고 고속을 요하는 장치는 패러렐로, 약간 느려도 장거리로 연결해야 하는 경우는 시리얼로 연결했죠. 느리게 전송하던 시리얼 포트와 패러렐 포트 사이에서도 이런데, 훨씬 고속인 병렬 버스가 있다면 각각의 배선 길이가 더욱 엄격해야 겠죠.) .
반면, PCI Express에서는 임베디드 클럭 방식의 직렬 연결이기 때문에, 각 신호선 쌍(상향과 하향) 사이의 (Clock) skew (타이밍 차이)를 신경 쓸 필요가 없다. 구불구불한 등장배선으로 보드의 면적을 먹어 버리는 문제도 없고, 아주 설계가 용이하다고 Intel은 말한다.
그러나 실제로는 그리 간단하지는 않다. PCI Express는 (상향 또는 하향 단방향에)2개의 신호선이 쌍이 되어 차동신호로 전송한다. 따라서 (단방향의 차동)신호선 쌍 사이에서 길이는 매우 엄격하게 맞출 필요가 있는 것이다.
[고전 2001.08.31] USB 2.0 컨트롤러 칩셋 및 모바일 펜티엄 4 2GHz를 공개
[고전 2001/03/02] Intel이 GHz급 차세대 고속 IO 버스의 개발 의향을 표명
[고전 2001.07.31] 이번 전쟁은 I/O 버스 전쟁이다 드디어 격돌 Hyper Transport 대 3GIO
[고전 2002년 4월 18일] PCI-SIG가 3GIO의 정식 명칭을 PCI Express 로 결정
[고전 2002.09.27] 밝혀진 차세대 직렬 버스 "PCI Express" 사양
[고전 1997.08.28] 차세대 MPU를 위한 포석 AGP
'벤치리뷰·뉴스·정보 > 고전 스페셜 정보' 카테고리의 다른 글
| [고전 2003.03.10] Fab에서 예측하는 향후 인텔 (0) | 2005.11.03 |
|---|---|
| [고전 2003.03.10] 하이퍼 쓰레딩 대응 게임 엔진이 등장 GDC 2003 (0) | 2005.11.03 |
| [고전 2003.02.27] Prescott,Tejas는 5GHz대, 65nm Nehalem은 10GHz이상 (0) | 2005.11.02 |
| [고전 2003.02.22] Intel 차세대 하이퍼 쓰레딩 (Hyper-Threading) 기술 공개 (0) | 2005.11.02 |
| [고전 2003.02.20] Pentium M 1.60GHz의 처리 능력 (0) | 2005.11.02 |
| [고전 2003.02.20] Intel 차세대 CPU Prescott의 정체를 밝혀 (0) | 2005.11.02 |
| [고전 2003/02/17] 100MHz 부터 3066MHz까지 65 CPU 벤치마크 (0) | 2005.11.02 |
| [고전 2002.11.14]Pentium 4 3.06GHz 빠른 리뷰 Hyper-Threading의 효과는 얼마나? (0) | 2005.10.11 |