통합 GPU 코어의 성능 범위는 1 세대 이전 중급까지
AMD가 "FUSION"프로세서 CPU에 통합하는 GPU 코어는 세 가지 요소에 의해 어느 정도 제한된다. 다이 사이즈 (반도체 본체의 면적)와 소비 전력, 그리고 메모리 대역폭이다. 이 세가지 제약 조건으로 FUSION에 통합 된 GPU 코어의 성능은 동 세대의 GPU의 메인 스트림 클래스로 억제된다. AMD는 FUSION을 모바일로 먼저 가져 오는 것을 제안하고 있는 것은 그 때문이다. 또한 FUSION이 등장한 후에도 이 제약으로 인해, 중급 이상의 성능형 비디오 카드는 AMD 플랫폼에서 살아남는 것이다.

AMD의 Phil Hester 씨
AMD의 Phil Hester (필 헤스터) 씨 (Senior Vice President & Chief Technology Officer (CTO))는 2006년 인터뷰에서 다음과 같이 설명했다.
"(FUSION에 통합 스트림 프로세싱 성능은) 결코 하이 엔드에는 가지 않을 것이다. 왜냐하면 하이 엔드 성능에 필요한 만큼의 실리콘은 (FUSION에서) 마련하지 못하기 때문이다. 소비 전력면에서도 하이엔드 통합은 어렵다. 그래서 앞으로도 Torrenza (토렌자) 형 시스템이 적합한 시스템으로 남는 것이라고 생각하고 있다.
(FUSION 의해) 매우 효율적이고 최적화되어 이전보다 뛰어난 그래픽 기능을 가진 기반 플랫폼이다. Torrenza 형 시스템은 거기에 플러스하여 보다 높은 수준의 기능 통합이 가능하게 된다. 즉, (CPU의) 실리콘에 (코 프로세서를) 통합함으로써 시장 기능을 널리 보급시킨다. 또한 그런 Torrenza 계열의 가속기에서 고급 기능을 추가 할 수 있다. 실리콘에 모두 통합하는 것이 아니라 Torrenza로 제공하는 것도 병존한다. Torrenza 형 가속기는 적어도 우리가 예상 할 수있는 만큼 향후 계속 병존하고 남는다고 생각하고있다 "
AMD의 CPU 제품의 다이 크기는 하이 엔드 데스크탑 CPU에서 200 제곱 mm 정도, 메인 스트림 CPU에서 120 ~ 150 제곱 mm, 저가 CPU에서 100 제곱 mm 전후 또는 그 이하. 따라서 FUSION 절반의 다이 (반도체 본체)를 GPU 코어에 할애해도 탑재 할 수있는 GPU 코어의 규모는 어느 정도 제한된다. GPU의 다이는 하이 엔드 GPU가 300 제곱 mm 이상, 미드 레인지 GPU에서 120 ~ 150 제곱 mm, 저가 GPU로 100 제곱 mm 전후 또는 그 이하. 따라서 45nm 프로세스 세대의 FUSION에 통합 GPU 코어는 65nm 세대 1 랭크 아래의 개별 GPU 정도의 규모다.
예를 들어, 45nm의 FUSION이 메인 스트림 CPU 정도의 다이 사이즈라면, 통합 GPU 코어는 65nm 세대의 미드 레인지 GPU 클래스. 밸류 CPU 정도의 다이 사이즈라면, GPU 코어는 65nm 세대의 저가 GPU 클래스가 된다. 즉, 실리콘 (= 다이)의 크기를 생각하면 저절로 FUSION에 통합 GPU 코어의 규모가 정해져 버린다.
따라서 동 세대 공정 기술로 제작되는 중급 이상의 GPU의 성능은 FUSION에서는 제공하지 못한다. 그래서 PCI Express 연결형 비디오 카드도 포함 Torrenza 형 가속기의 제공이 앞으로도 남게된다. AMD는 FUSION에서 제공하는 GPU / 스트림 프로세싱 기능은 기본적인 것으로 생각하고 있다. Torrenza를 통해 CPU에 연결하는 코 프로세서를 보충시키는 전략이 FUSION과 병존하는 것은 그 때문이다. AMD의 주목적은 범용 CPU 코어에 FUSION과 Torrenza의 2 가지 방법으로 보조 프로세서를 추가하여 특정 처리 성능을 효율적으로 업하는 것이다.
AMD의 die size 이행도 최신버전
메모리와 소비 전력이 FUSION 프로세서를 제한
FUSION에 있어서 실제 다이 크기 이상으로 벽이 되는 것은 소비 전력과 메모리이다. 프로세서 성능을 올리면 그만큼 소비 전력이 상승하고, 메모리 대역이 필요하다. 그러나 시스템 측에서 대응할 수 있는 전력에는 한계가 있고 일반 메모리로 실현 되는 대역에도 제약이있다. 따라서 FUSION 칩의 한계까지 성능을 끌어 올릴 수 없다.
"프로세서 설계의 관점에서 보면 전력과 메모리 대역이라는 두 가지의 균형을 잡는 것이 중요하다. 설계상 으로는 잠재적으로 TeraFLOPS의 성능을 달성하기 같은 급진적 프로세서 디자인 할 수 있다. 그러나 현실적인 전력 예산과 현실적인 메모리 구성으로 그것을 달성 할 수 없다. 밸런스 포인트를 생각하고 설계 할 필요가 있다.
특히 주류 PC 기술에 고정된 시도는 제약이 있다. 표준 칩 패키징 및 기판 기술, 그 시점에서 업계 표준 양산 메모리 기술. 이를 이용하려고 하면 자연스럽게 제약이 있게 된다. 그 제약 속에서 얼마나 공격적인 실행 유닛을 설계 할 수 있는가 하는 균형이 된다 "고 Hester 씨는 기본적인 자세를 설명한다.
즉, FUSION 프로세서도 PC 세계의 표준 기술 틀 내에서 제공 할 수 있도록 한다. 특수 냉각 시스템 및 특수 메모리를 사용하지 않아도 되도록 하는 것이다. FUSION에 통합 프로세서 코어군은 어디 까지나 그 제약 조건 내에서 설계하려는 자세를 가지고 있다.
이것은 실은 FUSION에 있어서 상상 이상으로 힘든 제약이다. 특히 메모리 제한은 어렵다. CPU에 GPU의 엄청난 부동 소수점 연산 능력을 추가 FUSION 에서는 엄청난 메모리 대역폭과 더 세분화 된 메모리 액세스가 필요하기 때문이다.
CPU와 GPU에서 크게 다른 메모리 방향의 기술
GPU 코어는 범용 CPU 코어보다 엄청난 메모리 대역폭을 필요로 하는데 요청하는 메모리 액세스 입도도 작은 경우가 있다. 또한 메모리 액세스 패턴도 달라, 메모리 액세스 지연 시간이 연산 코어에 미치는 영향도 다르다. 따라서 CPU와 GPU는 최적의 메모리 기술과 메모리 인터페이스 구성이 크게 다르다.
범용 CPU는 "일반 DRAM" 으로 일반적으로 불리는 메모리 업계 주류 DRAM 기술에 최적화되어 있다. 일반 DRAM 측도 범용 CPU에 최적화하여 설계해 왔다. 일반 DRAM은 모듈 단위로 증설을 최우선으로 생각하고 있다. 또한, 일반 DRAM에서는 메모리 대역폭뿐만 아니라 메모리 레이턴시도 중시하고 급진적으로 대역폭을 넓히는 방법은 취하지 않는다. 범용 CPU의 경우 구성이나 비용도 중요하기 때문에 메모리 업체가 협력하여 동일 규격의 메모리를 양산 하는 것이 중요하다.
반면 하이 엔드 GPU는 그래픽에 특화된 DRAM을 전제로 설계되어 왔다. 비디오 카드는 DRAM 메모리 보드에 직접 형성되고 모듈 형 메모리는 사용하지 않는다. 현재는 하이 엔드 GPU는 높은 전송 속도에 특화한 GDDR3 / 4 계 메모리를 채용하고 있다.
범용 CPU의 경우 칩의 가장자리 길이 등의 제약으로 통합 메모리 인터페이스 폭은 128bit까지 머문다. 즉, DDR2 / 3 계에서는 현재의 듀얼 채널 이상의 메모리 인터페이스를 통합하는 것은 현실적이지 않다. 반면, 범용 CPU에서는 메모리 액세스 크기는 문제가 아니다. AMD의 경우 현재는 128bit 단위로 DRAM 컨트롤러를 제어하고 있다. 다음 "Barcelona (바르셀로나)"에서 64bit 단위로 제어하는 2 개의 DRAM 컨트롤러를 갖추게된다. 그러나 그 이상 DRAM 제어를 세분화 할 수 없다.
반면 중급 이상의 GPU는 메모리 인터페이스 폭이 256bit로 넓게 취하고 있다. 인터페이스 폭을 넓게 취하는 것으로, 광대역 화를 꾀하고 있다. 동시에, 메모리 인터페이스를 분할하여 제어하는 것으로, 메모리 액세스 크기를 작게하고 있다. ATI Radeon X1000 (R5xx) 계의 경우, DRAM 컨트롤러는 32bit 폭의 단위로 제어되고 있다.
부족한 메모리 대역폭과 큰 메모리 액세스 크기
이처럼 메모리 방향이 크게 다른 프로세서 코어끼리 같은 칩에 싣고 메모리를 공유하는 경우에는 여러 가지 문제와 제약이 생긴다. 우선 가장 큰 문제가 되는 것은 메모리 대역폭이다. 하이 엔드 GPU는 프로그래머블 코어만 300 ~ 500GFLOPS의 연산 성능, 메모리 대역은 30 ~ 50GB/sec 클래스이다. 10GFLOPS 당 약 1GB/sec의 메모리 대역폭을 필요로 하는 계산이 된다.
그런데 PC 용 DDR 계 메모리는 2008 ~ 2009 년의 단계에서 최고에서도 DDR3-1600 듀얼 채널 메모리이다. 메모리 대역폭은 피크에서 25.6GB/sec이기 때문에 성능으로 균형이 잡히는 것은 200 ~ 300GFLOPS 가 된다. GPU 코어의 경우 캐시가 효과가 없는 처리가 많기 때문에 CPU 코어 처럼 캐시 양을 늘려 충당하기 어렵다. 메모리의 제약으로 FUSION의 GPU 코어의 성능은 제한된다.
DDR3 메모리를 사용하는 경우 또 다른 문제는 메모리 액세스 입도이다. 공정 기술이 미세화해도 DRAM 메모리 셀의 속도는 거의 오르지 않는다. 따라서 DRAM 칩은 메모리 셀에서 읽을 데이터의 단위를 크게하는 것으로 고속화를 도모하고 있다. 이것은 "프리 페치 (Prefetch)"라고 불린다. 예를 들면, "프리 페치 4"의 DDR2는 메모리 셀에서 4n 개의 데이터를 1 클럭마다 읽기, 4 배 빠른 속도로 인터페이스 칩 외부에 출력하고 있다.
프리 페치 기술 덕분에, DRAM은 메모리 셀 속도의 제약에도 불구 배속화를 계속할 수 있었다. 그러나 반면에, 메모리 액세스 크기는 세대마다 두배가 되고 있다. 이것은 메모리 셀에서 한 번에 읽을 데이터의 양이 배로 증가하고 있기 때문이다. 예를 들어, 64bit 폭의 메모리 모듈 당 액세스 입도는 DDR2가 32bytes 프리 페치 8 , DDR3는 64bytes가된다.
범용 CPU 코어의 경우 메모리는 L2 캐시 라인 단위로 액세스하는 64bytes에도 문제가 생기지 않는다. 그런데 GPU 코어의 경우 256bits (32bytes) 정도의 단위로 데이터에 접근하는 경우가 상당히 발생한다. 따라서 DDR3 메모리 모듈은 액세스 크기가 너무 낭비가 발생할 수 있다. 즉, 64bit 폭으로 메모리 액세스를 행해도 그 중 절반 밖에 사용하지 않는 상황이 나온다. 그렇게 되면 실효 메모리 대역이 줄어 버린다.
GPU 코어는 CPU 코어와 달리 메모리 대역폭 집중이므로 이 낭비에 의해 성능이 제한되어 버린다. 이 문제는 FUSION 뿐만 아니라 그래픽 통합 칩셋도 마찬가지다. 그리고 CPU와 칩셋에 통합된 GPU 코어의 성능이 향상되어 메모리 요구가 증가함에 따라 문제가 중요하게 된다. FUSION 시대에는 큰 벽이 될 것이다.
업계를 말려 들게 한 메모리 개혁이 필요
명백한 것은 FUSION 시대가 되면, 일반 DRAM 아키텍처를 근본적으로 바꾸어 갈 필요가 있다는 것이다. 메모리 쪽을 FUSION 형의 프로세서에 맞게 바꾸어 가지 않으면 미래의 FUSION 프로세서의 성능은 한계점에 도달해 버린다.
이러한 문제를 해결할 수 메모리 기술도 있다. DDR2 메모리의 4배의 핀 당 전송 속도를 가진 Rambus의 "XDR DRAM '패밀리가 그 것이다. XDR2 DRAM되면 "Micro-Threading"를 통해 액세스 입도를 실질적으로 줄일 수있다. 즉, 미래에 걸쳐 광대역 화를 계속해서 액세스 입도를 유지할 수있다. 따라서 XDR DRAM은 Cell Broadband Engine (Cell BE)에 채용 된 것에서 알수 있듯이 스트림 프로세서를 통합한 CPU에 적합한 메모리 기술이다.
하지만 XDR DRAM은 전체 DRAM 벤더가 제공하는 메모리가 아니라 제조하고 있는 것은 3개 회사만. Rambus와 JEDEC (미국의 전자 공업회 EIA의 하부 조직으로 반도체의 표준화 단체)의 관계는 별로 협력하지 않기 때문에 이 기술이 메인 스트림으로 갈 가능성은 낮다.
이러한 사정으로 인해, 메모리는 FUSION 형 CPU에 있어서 가장 큰 걸림돌이 될 것 같다. 그리고 이 문제의 해결책은 AMD 단독으로는 불가능하고, DRAM 벤더 등 업계를 끌어 들여 변화 시킬 필요가 있다. 문제는 AMD에 그만큼 업계를 견인하는 힘이 있는가?? 표준화 단체 내에서는 Intel의 힘은 여전히 강하다.
무엇보다, Intel도 현재 GPU 코어를 통합한 CPU 제품의 도입을 검토하고 있다. 여러 업계 관계자에 따르면, Intel은 AMD의 FUSION에 대항 할 수있는 시기에 CPU와 GPU의 통합 제품을 출시 할 예정이라고 한다. 이것이 진정으로 통합 프로세서인지, 아니면 단순히 CPU와 그래픽 통합 칩셋 2 개의 다이 (반도체 본체)를 1 패키지에 담은 제품 여부는 아직 모른다. 그러나 Intel도 FUSION 대항을 진지하게 생각하고 있는 것 같다.

FUSION 프로세서 상정 그림
페타 스케일의 HPC 시스템도 시야에 넣는 AMD
AMD는 FUSION 형 GPU 통합 프로세서를 클라이언트 공간에만 한정하여 생각하는 것은 아니다. 서버 에서도 GPU 코어를 활용하는 방향에 있다. 현재 AMD는 GPU 카드를 스트림 프로세싱의 가속기로 제공하고 있지만, GPU 코어를 CPU에 통합 할 수 있게되면, 더 통합 된 형태로 "고성능 컴퓨팅 (HPC)"을 위해 스트림 컴퓨팅 능력을 제공 할 수 있게 된다.
"GPU의 명령어 세트 및 시스템 트레이드 오프 등을 명확히 한다면, GPU의 기능 방식으로 일반화 할 수 있게 된다. 그러면 (GPU 코어는) 저가에 높은 볼륨의 표준 부품의 빌딩 블록으로 CPU 디자인에서 유효화 된다. 하이 엔드 과학 기술 머신까지 사용할 수 있는 확장 가능한 빌딩 블록의 일종이 될 것이다.
오늘의 GPU를 보면, 피크 성능은 500GFLOPS에서 1TFLOPS 사이에 있다. 또한 클러스터 결합으로, 수천 노드의 거대한 과학 기술 시스템이 오늘날 현실이 되고 있다. 그래서 길을 잘 만들면 비교적 쉽게 저가 페타 플롭급 시스템을 만들 수 있다. 우리는 (GPU 코어) 클라이언트 영역에 도움이 될뿐만 아니라 대형 과학 기술 컴퓨팅 분야에서도 매우 효과적인 빌딩 블록이 될 것이라고 생각하고 있다 "
즉, 가까운 미래 AMD는 500GFLOPS ~ 1TFLOPS의 부동 소수점 연산 능력을 가진 GPU 코어를 CPU의 빌딩 블록으로 사용할 수 있게 된다. 그러면 FUSION 형의 프로세서를 1,000 노드 결합 시키면 PetaFLOPS 클래스 컴퓨터도 가능하게 된다. 게다가 클라이언트용 FUSION을 이 PetaFLOPS 시스템으로 전용하면 AMD가 어떤 100 만개 양산하는 프로세서를 사용하면 비용도 싸고, 인터페이스 및 주변 로직도 성숙한 플랫폼을 제공 할 수있다. 그래서 페타 스케일 시스템이 비교적 저렴한 비용으로 쉽게 구현할 수 있다는 것이다.
배정도 연산은 GPU 기반 HPC 벽
그러나 현재의 GPU의 연산 코어는 단정밀도(32bit 연산) 부동 소수점 연산 엔진으로 HPC 애플리케이션이 많이 요구하는 배정밀도(64bit 연산. CPU는 호랑이 담배피던 시절부터 가능. 더욱 빠르게 여러개의 연산을 한번에 연산하는 SIMD 명령으로는 펜티엄3 SSE에서 32비트 단정밀도 4Flops 연산, 펜티엄4 SSE2에서 64비트 배정밀도 2Flops 연산 가능. AVX 지원 하스웰은 32비트 8Flops, 64비트 4Flops 연산 가능.) 이상의 연산에는 대응할 수 없다. 따라서 최대한 HPC 분야를 커버 할 수있는 것은 아니다. Hester 씨도 이 점은 인정하고 있다.
"분명히, 현재는 배정밀도를 지원할 수 없으며, 단정밀도 연산도 현재로서는 IEEE 규격이 없다.하지만 완전히 풀 IEEE 규격 배정도 연산 유닛을 구현하게 되면, 상당한 실리콘 자리가 필요하다. 따라서 어떤 구현이 적절한 지에 대해 큰 논쟁이 있다. 정답은 아마도 오늘날의 GPU와 완벽한 하이 엔드 과학 기술 머신 간의 중간 어딘가에 것이다. 어떤 클래스 ( 작업)까지 만족시킬 방법을 궁리 할 필요가 있다 "
GPU 코어는 연산 정밀도를 그래픽에 필요한 단정도로 억제해 연산 유닛을 단순화 하여 탑재 할 수 있는 유닛 수를 늘리고 있다. 따라서 GPU 코어가 지원하는 연산 정밀도를 높이면 연산 성능이 저하되어 버린다. GPU 코어를 HPC에 전용하는 경우에는 이 점이 큰 벽이된다. FUSION 세대의 현실적인 해결책은 단정밀도 연산을 IEEE 준수에 접근 배정 밀도는 당분간 보류하는 기준이라고 추측된다. 배정밀도 내용은 다른 솔루션도 있기 때문이다.
"우리는 Torrenza 가 있다. 정말 진지한 과학 기술 컴퓨팅 기능은 Torrenza로 볼 수있다. 아마 Torrenza 형 가속기에서 배정밀도가 필요한 워크로드 처리 할 수있는 것"(Hester 씨)
실제로, 현재도 배정밀도 부동 소수점 연산 가속기는 AMD 플랫폼에 제공되고 있다. 이러한 솔루션이 Torrenza에서 추진되고 가속이 더 저렴한 비용으로 광범위하게 제공되도록 하고, 소프트웨어 인터페이스도 성숙해 간다는 것이 AMD가 그리는 그림 일 것이다. 미래에는 그것이 AMD 프로세서 빌딩 블록으로 채워 갈 가능성도 있다.
"서버 공간도 클라이언트와 동일한 것이다. 만약 특정 기능이 퍼포먼스 / 소비 전력 측면에서 CPU에 통합해도 이치에 부합이 되면 통합하지 않을 이유는 없다"(Hester 씨)
그러나 HPC는 전체 볼륨으로 작기 때문에, HPC 전용의 기능을 통합한 프로세서가 맞는지 모르겠다.
명확한 것은 AMD의 FUSION 전략은 단순히 CPU에 그래픽을 플러스하는 것이 아니라, HPC 영역까지 포함한 광대한 솔루션의 제공을 상정하고 있다는 것이다.
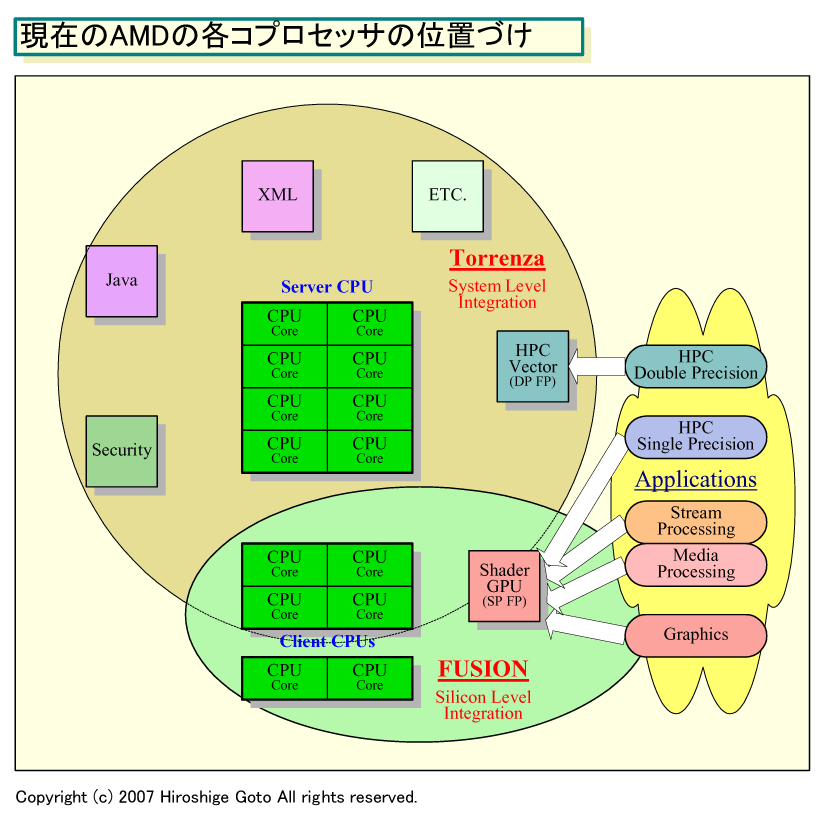
각 보조 프로세서의 위치
2007년 1월 31일 기사 입니다.
[분석정보] 하스웰 eDRAM에 JEDEC 차세대 DRAM으로 대항하는 AMD의 메모리 전략
[분석정보] Intel의 CPU "Haswell"용 DRAM 기술
[분석정보] 정체를 보인 Haswell의 eDRAM 솔루션
[아키텍처] Intel의 차기 CPU 하스웰(Haswell) eDRAM의 수수께끼
[분석정보] AMD가 발표한 메인 스트림 APU Llano의 아키텍처
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] Intel, 45nm공정의 차기 CPU Penryn 자세히 공개 (0) | 2007.03.29 |
|---|---|
| [분석정보] CeBIT에서 보는 UMPC의 현재와 미래 (0) | 2007.03.20 |
| [분석정보] Intel TDP 3W x86 CPU 출하 Intel Turbo Memory도 시현 (0) | 2007.03.16 |
| [분석정보] Intel CPU의 미래가 보이는 80코어 TFLOPS 칩 (0) | 2007.02.15 |
| [분석정보] 인텔 45nm 공정 차세대 CPU Penryn(펜린) High-k 메탈게이트 성공. (0) | 2007.01.29 |
| [분석정보] Intel 또 하나의 차세대 CPU LPP (0) | 2006.10.23 |
| [분석정보] 대폭 강화된 AMD의 쿼드 코어 Barcelona (0) | 2006.10.16 |
| [분석정보] AMD가 쿼드 코어 CPU Barcelona의 상세를 발표 (0) | 2006.10.13 |