IA-64의 성능 및 기능 강화를 서두르는 Intel
Intel은 "IA-64" 계열 프로세서의 고성능화를 서둘러야 한다. IA-32 아키텍처의 64bit 확장 "64bit Extension Technology (통칭 IA-32e = 후에 EM64T, intel64로 불리는)"의 발표로 64bit 어드레싱는 IA-32에 대한 장점을 잃었기 때문이다. 구현상의 논리적 / 물리적 주소 공간은 여전히 IA-64 쪽이 유리하지만 가장 확실한 차별화 포인트는 없게 되었다.
따라서 IA-64은 어느때 보다 아키텍처의 프로세싱 파워를 구해야 하는 상황이 되었다. 그래서인지 Intel은 IA-64 마이크로 아키텍처의 개혁에 박차를 가하고 있다.
IA-64의 향후 진화 방향은 명확하다.
멀티 코어 (Multi-Core)
SMT (Simultaneous Multithreading)?
동적 스케줄링
가상 머신 지원 기능
하드웨어 보안 기능
성능 / 소비 전력 향상 기술
이러한 요소가 아마 2006년의 "Tukwila (투킬라, 투퀼라) "세대까지 갖춘다. 즉, Intel의 클라이언트 CPU계 뿐만 아니라 아키텍처면에서 대폭적인 확장이 향후 몇년 동안 진행된다. Intel은 위에서 아래까지 전체 CPU 라인업에서 구조 개혁을 행하려 하는 것 같다.
TLP로 일직선으로 향하는 Itanium
우선 큰 흐름은 "스레드 수준 병렬 처리 (TLP : Thread-Level Parallelism)"의 강화이다. 향후 IA-64 프로세서는 하나의 CPU 칩에 여러 개의 CPU 코어를 납입하고, 또한 각 CPU 코어가 여러 스레드를 동시에 처리 가능한 메커니즘을 제공해 간다. 멀티 코어의 첫 번째 세대는 2005년 90nm 프로세스 세대 "Montecito (몬테시토)"가 된다. Montecito는 2개의 CPU 코어와 L3까지의 캐시를 내장한다. 그러나 예상과는 달리 각각의 CPU 코어가 독립적인 L3까지의 캐시를 탑재, 아비터로 그것을 조정한다.
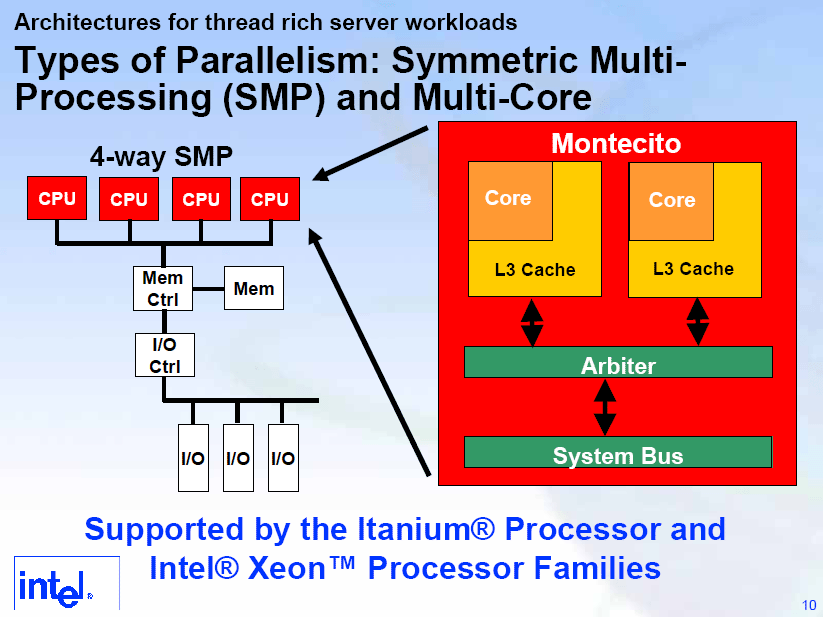

Montecito 아키텍처
(우측의 아이테니엄의 Coarse-Grain Multi-threading.
각 스레드가 동시에 프로세서 자원을 공유하며 한번에 2개의 쓰레드를 실행가능한 하이퍼쓰레딩과 다르게, 아이테니엄의 경우는 한번에 1개의 쓰레드만 실행 가능.
물론 기존의 단일 쓰레드 CPU하고도 다른 겁니다. 아이테니엄식의 멀티
쓰레딩은 단일 쓰레드 CPU와는 다르게 2개의 쓰레드 상태를 유지할 수 있습니다.
즉 2개의 쓰레드를 실행할때 빠른 쓰레드 전환이 가능.이것만으로도 성능 증가.
개인용 프로세서라면 덜 이익일 수 있겠지만, 서버용 이라면 나름 효과가 있겠죠.
또 IA-64 코어는 애초에 최대 명령을 채우는 쪽으로 컴파일 되어서 오기 때문에, SMT를 써도 상대적으로 성능 증가가 적을 수 있다는 (또는 없는) 점 입니다. 단순히 다른 명령을 쓰는 CPU가 아니라, x86과 명령을 채우는 형태가 다릅니다.
x86이나 기타 다른 CISC CPU들은 각각의 명령이 독립적으로 들어오고 그걸 내부에서 스케쥴링 해서 동시에 실행 할 수 있도록 해서 동시에 실행하지만, IA-64 계열은 컴파일 단계부터 최대 실행가능한 명령 묶음 형태로 들어오고 내부에서 실행한다 이럼 개념 입니다. 이런 형태라면 SMT가 상대적으로 큰 성능 향상이 없을 수 있을테고, 그러면 동시 멀티스레딩이 (SMT 하이퍼스레딩) 아닌 비동시 멀티 스레딩 쪽이 현실적으로 더 타당할 수 있겠죠. 애초에 IA-64는 x86같은 프론트 엔드가 비대한 것을 줄이고 그것을 전부 실행자원으로 할애해서 최대 실행 능력을 키우고, x86의 프론트 엔드가 해야할 것들은 컴파일러 차원에서 해결해서 같은 자원대비 최강의 실행 능력을 부여한다 이런 개념 입니다. 서버나 슈퍼컴퓨터 용도가 목적인 CPU에서나 가능한 방법 입니다. 데스크탑 처럼 각각의 CPU사양이 다 다르고, 특별히 1개의 CPU에 대해서 최적화 하지도 못하는 용도의 CPU로는 부적합 하다고 봐야죠.
x86은 내부 스케쥴링을 하기 때문에 어떤 CPU에 덜 최적화로 묶이죠. 쉽게 말해서 더큰 IPC를 가진 CPU에 최적화를 해도 그전 CPU도 전부 성능이 잘 오르죠.)
하이퍼쓰레딩은 아예 동시에 실행을 하기에 더 성능이 증가 되구요.
물론 방식 자체에 대한 설명 (실제 CPU 성능이 아닌)입니다.
아이테니엄이나, 1쓰레드 CPU라고 해도
코어의 성능 자체가 월등히 좋으면.. 2코어든 하이퍼쓰레딩이든 뭐가 와도
더 좋을 수도 있는거니까요.
극단적으로 설명하면, 지금 하스웰 1코어가 486CPU 2코어 보다 동클럭이라도 훨씬 성능이 좋죠.)
또한 Montecito는 "Coarse-Grain Multi-threading"를 지원하는 하드웨어를 구현하는 것 같다. Hyper-Threading 등의 "동시 멀티 쓰레딩 (Simultaneous Multithreading : SMT)" 기술은 여러 스레드의 명령을 혼재시켜 실행시키는 것이 가능하다. 그러나 Coarse-Grain Multi-threading 에서는 여러 스레드에서 단순히 파이프 라인의 시분할을 할 뿐이다. Montecito는 2스레드를 특정 스위칭 이벤트에 전환 처리를 하드웨어로 행하는 것 같다. 두 스레드는 독립적인 아키텍처럴 스테이트를 유지하기 때문에 외관상 2개의 논리 프로세서로 보인다. IDF에서 이번 일정 관계로 참석하지 못한 세션에서 이 아키텍처의 설명도 진행됐다.
Coarse-Grain Multi-threading에 쓰는 입도 거친 멀티 스레딩의 경우, SMT처럼 효율적인 자원 사용은 할 수 없다. 그러나 메모리 액세스 지연 시간의 은폐 등에 효과가 있을 것이다.
Intel은 Montecito에서 SMT를 도입하지 않는 것은 IA-64 프로세서는 명령 수준의 동적 스케줄링 메커니즘을 (CPU내부에서 명령 병렬화, IA-64는 컴파일러에서 정렬 병렬화. 물론 x86도 어떤 컴파일러로 컴파일 했냐에 따라서 (GCC 같은걸로 하냐, MS 컴파일러로 하냐, 인텔 컴파일러로 하냐 등. 인텔 컴파일러로 컴파일 된 소프트가 현재는 최고) 완성된 소프트웨어의 성능이 달라집니다.) 갖추지 않았기 때문이다. 처음부터 동적 명령 스케줄링을 갖춘 Pentium 4계 CPU는 SMT를 비교적 쉽게 구현할 수 있지만, IA-64는 SMT를 구현하려고 하면 동적 스케줄링도 필요하게 된다.
따라서 Intel은 차세대 IA-64 아키텍처는 SMT 및 동적 스케줄링을 같은 타이밍에 투입한다고 추측된다.
IA-32처럼 동적 스케줄링을 실장

Intel Michael J. Fister 씨
Montecito까지의 IA-64 계열 CPU는 모두 Itanium 2 (McKinley : 매킨리) 아키텍처의 흐름을 잇는다. 그러나 2006년에는 완전히 새로운 아키텍처의 차세대 IA-64 프로세서가 투입된다. 이것이 65nm 공정 버전의 Tukwila다. Tukwila는 최근까지 "Tanglewood (탱글우드)"라고 했던 CPU와 똑같은 것이다. 단순한 코드명 변경에 지나지 않는다고 한다.
Intel은 현재 Tukwila 대해 2개보다 많은 수의 CPU 코어를 내장하는 멀티 코어 밖에 밝히고 있지 않다. 그러나 이 세대는 SMT 및 동적 스케줄링을 모두 구현하는 것으로 추측된다. 그것에 대해 Intel 엔터프라이즈계 제품 부문을 총괄하는 Michael J. Fister (마이클 J 피스터) 씨 (Senior Vice President & General Manager)는 다음과 같이 대답했다.
[Q] "Intel 연구원이 발표한 연구 논문을 읽으면, SMT 및 동적 스케줄링을 IA-64 프로세서에 실장하면 성능이 큰폭으로 향상된다 말했다. Intel은 이미 Hyper-Threading을 IA-64 가져오는 것을 밝히고 있는데, 동적 스케줄링은 언제 도입 하는가?"
[Fister 씨] "좋은 질문이지만, 지금은 대답 할 수 없다. 왜냐하면 너무 많은 비밀을 말하면, 그(Intel 홍보담당자)가 나를 죽일 것이기 때문이다 (웃음). 아직 몇년은 죽고 싶지 않다 (웃음).
그러나 그것(동적 스케줄링)이 향후 제공되는 아키텍처의 조각이 될 것은 확실하다. 문제는 (CPU를 설계 할 때) 간단한 코어가 좋은 것인지, 더 복잡한 코어가 좋은 것인지 라는 점에 있다. 더 크고 복잡한 코어를 하나(CPU)에 올리는 것이 좋은 것인지, 아니면 더 간단한 코어를 더 올린 것이 좋을지는 흥미로운 기술 논의이다.
쉽게 말해 구멍 파는 일을하는 때 몸이 크고 힘이 센 사람을 혼자 고용 굴착하는 것과 그렇게 강하지는 않은 사람을 많이 고용하고 굴착하는 것과 어느 쪽이 효율이 좋은 것인가? 이를 신중하게 생각할 필요가 있다.
사실, 이것이 우리가 Tukwila에 몇개의 코어를 다이(반도체 본체)에 싣고 있는지 밝히지 않는 이유로 있다. 왜냐하면 (코어 수를 밝히면) Tukwila 코어가 어느정도의 크기에 어느정도 강한지 알수 있기 때문이다. "
즉, 동적 스케줄링 및 SMT는 어느 시점에서 가지고 오지만, 거기에는 장단점이 있다. 이러한 기능을 구현함으로써 CPU 코어가 커지는 경우 1CPU에 탑재 할 수 있는 CPU 코어 수가 줄어 반대로 성능에 불리하게 되어 버리는 것이다. 즉 Tukwila가 대단히 많은 CPU 코어 (8개 라든지)를 탑재하고 있다면, 각 CPU 코어의 확장은 최소한인 것이고, Tukwila가 적덩한 수의 CPU 코어(4개 라든지)만 탑재하지 않았다면 SMT 및 동적 스케줄링을 탑재하고 있는 것으로 생각된다. (마치 AMD 8코어 데스크탑과 인텔 4코어(8쓰레드) 데스크탑 비교와 비슷하죠.)
정적 컴파일로 최대한의 스케줄링을 행하는 IA-64에서 동적 스케줄링이 더해지는 것은 이상하게 들릴지도 모른다. 그러나 어느 Intel 관계자는 동적 스케줄링은 IA-64의 당연한 발전이라고 말한다. "IA-32가 시리얼인 명령 실행에서 동적 스케줄링으로 진화해 간대로, IA-64도 동적 스케줄링으로 향한다. 그렇지 않으면 코어의 성능 향상은 어렵기 때문이다." (어느정도의 명령 병렬화 까지는 컴파일러로 대응이 가능하겠지만, 그 이상은 컴파일러가 대응이 불가능 하겠죠. x86의 경우도 컴파일러의 약간의 도움과 CPU내부의 스케쥴링을 통해서도 최대 IPC만큼의 명령 병렬화를 항상 다 못하죠. 최대치까지 동시에 실행하는 경우도 있지만, 대부분은 최대치 까지 동시에 실행을 못하죠. 그러니까 하이퍼스레딩을 통해서 2개의 스레드를 1코어에서 돌려도 성능 증가가 있죠. 최대치로 실행하지 못하는 부분을 2번째 스레드를 동시에 실행하면, 항상 CPU 코어가 가진 최대치 까지 사용이 가능하죠).
그러나 IA-64에 구현되는 스케줄링 하드는 IA-32과는 다른 내용이 될 것이다.
가상 머신 기술도 실장
Intel은 IA-64 프로세서에 가상 머신 지원 하드웨어를 실장한다. IA-64의 가상 머신화도 IA-32의 가상 머신 기술 "Vanderpool (밴더풀 인텔 VT-x)"과 같이 새로운 특권 수준을 만드는 것을 기반으로 실현하는 것으로 보인다. 그러나 IA-64에서 가상 머신은 IA-32의 Vanderpool 보다 강력하고 다기능이 된다고 한다. 그것은 가상 머신화는 서버 측에서 더 필요로 하기 때문이다. IBM이 메인 프레임 시리즈에서 도입하고 있는것 같은 고도의 가상 머신 기술을 가져온다 말한다. 이를 통해 가상 머신의 효율성과 신뢰성을 크게 향상시킨다.
또한 서버 쪽에서도 Intel은 자사에서 버츄얼 머신 매니저 (VMM : Virtual Machine Manager) 소프트웨어를 제공 할 생각은 없다. VMM 내용은 Intel은 중립 입장을 관철한다. Intel은 완전히 하드를 가상화하는 "하이퍼 바이저" 소프트웨어 포함으로 CPU를 제공 OS 벤더가 그 위에 OS를 달리게 하는 선택 사항도 있지만, 그것은 지금은 생각하고 있지 않다고 한다.
CPU의 가상 머신 지원과 하드웨어 보안 (파티션)은, 베이스는 동일한 메커니즘을 사용한다고 추측된다. 따라서 가상 머신이 구현될 때 하드웨어 보안 기능도 구현 될 것이다. 이 두 기능은 Montecito의 기능 목록에 들어 있지 않기 때문에 Tukwila 세대가 될 것으로 추측된다.
또한 Intel은 Montecito에서 확장판 SpeedStep (Geyserville-2)와 같은 주파수 및 전압 스케일링을 구현한다. 또한 소비 전력을 먹지 않는 소프트웨어 실행시에는 주파수를 높이는 새로운 기술 "Foxton (폭스톤) '도 실장한다. 이러한 경향은 데스크톱 CPU에서도 공통이다.
덧붙여서, Itanium 2 제품군의 현재의 TDP 범위는 고성능 서버는 130W, DP 클래스는 99W, 저전력 DP는 62W. 이전에는 거창하게 느껴졌던 이 소비 전력도 지금은 Intel의 데스크탑 CPU가 따라왔기 때문에 그리 높게 느껴지지 않는다. "Prescott (프레스캇)"의 LGA775 세대에서는 TDP는 115W로 2005 년의 데스크탑 CPU "Tejas (테자스)"에서는 TDP는 125W에 도달해 버리기 때문이다.
따라서 Intel은 현재도 성능 / 소비 전력은 Itanium 2가 유리하다고 설명하고 있다. 이 밖에 Montecito 캐시 오류 검사 메커니즘 "PELLSTON (펠스톤)" 기술도 갖추고 있다.

Intel 서버 / 워크 스테이션 용 CPU 로드맵
IA-32e는 에뮬레이션 지원
Intel은 IA-64 및 IA-32 호환성 확보에 대해서도 새로운 접근을 시작했다. 현재 IA-64 계열 CPU는 IA-32 디코더 / 스케줄링 하드웨어도 갖추고 있다. 그러나 1월부터는 IA-64에서의 IA-32 에뮬레이션 레이어 "IA-32EL"의 제공도 시작했다. 그리고 Intel은 IA-32EL을 확장해 IA-32e에도 대응 할 생각이다.
Fister 씨는 IDF의 키 노트 연설 후 QA 세션에서 IA-64에서 IA-32e 지원에 대한 질문에 대한 답했다. "우리는 EL 소프트에 자신감을 가지고 있다. Itanium의 클럭이 올라가면 EL도 빨라진다." "미래에 (Itanium의) 하드웨어를 변경할 생각은 없다 "고 말했다.
즉, IA-64 프로세서는 IA-32e 지원을 하드웨어로 구현하는 것이 아니라 IA-32EL에서 소프트웨어로 구현하는 것 같다. 그리고 IA-64 계열이 향후 클럭이 향상되면 EL에서 IA-32 / IA-32e의 성능 향상도 실현될 것이다. 다른 Intel 관계자도 "IA-32EL의 중요한 목적 중 하나는 IA-32e의 지원에 있다"고 증언한다.
Itanium (VLIW) + IA-32EL (변환계층)은 마치 Transmeta 아키텍처다. 그러나 Intel은 IA-32EL 공격적인 스케줄링을 행하여, IA-32 / 32e의 성능을 추구할 의도는 없는 것 같다. 그렇긴 하지만, Tukwila 세대에서 동적 스케줄링이 들어가면 명령 레벨의 스케줄링이 가능하므로 IA-32EL 공격적인 스케쥴링을 하지 않아도 성능이 향상 될지도 모른다. 또한 Tukwila 이후 IA-64 프로세서는 맹장으로 있는(에뮬레이션 레이어로 인해서 쓸모 없이 있게 되는, 우리도 맹장을 필요없다 하는 일이 없다고도 하죠. 이런 상황에서는 계륵이나 잉여라고 하거나 아니면 요즘은 무쓸모로 표현하거나요, 일본은 맹장이라고 하나 봐요.) IA-32 프론트 엔드도 없어 질지도 모른다.
이렇게 대충 살펴보면, 실로 방대한 기술 부분이 향후 IA-64 프로세서에 박혀가는 것을 알 수 있다. IA-32뿐만 아니라 IA-64도 아키텍처 확장 폭풍으로 돌입해 가게 된다.
2004년 3월 5일 기사 입니다.
[분석정보] intel의 듀얼 코어 CPU 1번타자 Montecito
[정보분석] Penryn의 1.5 배 CPU 코어를 가지는 차세대 CPU "Nehalem"
[고전 2002.09.12] Hyper-Threading Technology를 지원하는 HTT Pentium 4 3.06GHz
[분석정보] AMD의 차세대 CPU Bulldozer의 클러스터 기반 멀티 스레딩
[고전 2001.08.29] IDF에서 보이는 새로운 방향 IA-32의 장래를 담당하는 하이퍼 쓰레딩
[분석정보] 아이테니엄(Itanium)을 둘러싼 불안과 기대
[분석정보] 드디어 베일을 벗은 Transmeta의 비밀 병기 Efficeon
[고전 2001.02.07] 인텔 폴락의 법칙이 등장 Intel 겔싱어 CTO의 ISSCC 강연
[분석정보] Many-Core CPU로 향하는 Intel. CTO Gelsinger 인터뷰 1/2부
[아키텍처] 폴락의 법칙에 찢어지고 취소된 테자스(Tejas)
[정보분석] 암달의 법칙(Amdahl's law)을 둘러싼 Intel과 AMD의 싸움
[분석정보](암달의 법칙) 2010년대 100 코어 CPU 시대를 향해서 달리는 CPU 제조사
[분석정보] iAMT, Montecito등 신기술이 공개된 IDF
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 1/2
[분석정보] CPU 고속화의 기본 수단 파이프라인 처리의 기본 2/2
[분석정보] 슈퍼 스칼라에 의한 고속화와 x86의 문제점은
[분석정보] 명령의 실행 순서를 바꿔 고속화 하는 아웃 오브 오더
[분석정보] x86을 고속화하는 조커기술 명령변환 구조
[분석정보] CPU와 메모리의 속도 차이를 해소하는 캐시의 기초지식
[분석정보] 캐쉬 구현 방식으로 보는 AMD와 인텔이 처한 상황
[고전 1997.10.31] Intel과 DEC 전격 제휴 MPU의 판도가 바뀐다
'벤치리뷰·뉴스·정보 > 고전 스페셜 정보' 카테고리의 다른 글
| [고전 2004.06.03] Intel 915에서 AGP에 대응하는 제품이 전시, ATI의 미발표 노스 브리지도 (0) | 2005.12.06 |
|---|---|
| [고전 2004.06.02] Socket 754/939 듀얼 소켓 사양의 제품이 전시 (0) | 2005.12.06 |
| [고전 2004.06.01] AMD Socket 939 대응 Athlon 64 FX, Athlon 64를 발표 (0) | 2005.12.06 |
| [고전 2004.05.18] 멀티 코어에서 새로운 가치관을 제안한 Intel 로우엔드도 EM64T를 지원 (0) | 2005.12.05 |
| [고전 2003.11.21] 939핀 플랫폼과 90nm 공정 도입을 서두르는 AMD (0) | 2005.11.11 |
| [고전 2003.11.07] AMD, CPU 로드맵을 업데이트 (0) | 2005.11.11 |
| [고전 2003.10.18] 모든 CPU는 멀티 스레드로, 명확하게 된 CPU의 방향 (0) | 2005.11.10 |
| [고전 2003.10.15] 드디어 베일을 벗은 Transmeta의 비밀 병기 Efficeon (0) | 2005.11.10 |