일반 명사화 되고 있는 매니 코어
CPU 코어 자체의 성능 향상은 막히고 있다. 반도체 스케일링의 둔화, 명령어 레벨의 병렬성 "ILP (Instruction-Level Parallelism)"의 향상의 한계 (IPC 증가 한계), CPU 설계의 복잡화라는 것이 원인이 되고 있다. 이것은 거의 CPU 업계의 공통 인식되고 있어, 그에 따라 급격한 멀티 코어로의 커브를 틀었다.

CPU 코어 수의 추이
그리고 CPU는 멀티 코어를 넘는 "매니 코어 (Many-core)"로 향하고 있다. 즉, 수십 코어에서, 미래에는 100코어를 원칩에 올린다는 비전이, 연구 개발에서는 테마가 되고 있다. Intel은 2004년 정도부터 매니코어라고 말하기 시작했는데, 이제는 Intel 만의 용어가 아닌 일반 명사화되고 있다.
Intel의 Justin R. Rattner (저스틴 R 래트너) 씨 (Intel Senior Fellow, Director, Corporate Technology Group)는 8월 미국 스탠포드에서 개최된 고성능 칩 컨퍼런스 "HotChips 18"에서 매니코어 시대에 대한 Intel의 조치를 설명했다.

Intel의 CPU 구상
위는 Intel이 그린 매니 코어 시대의 CPU 구상 "Tera-Scale Computing (Many-core)"의 개념도다. Intel은 작년 (2005년) 이후, 이 구상의 연구 개발에 대해서 몇번이나 설명했는데 아직도 " 허수아비 (Strawman)"상태로 명확한 형태로는 되지 않았다. 이 그림도 어디까지나 컨셉을 나타내는 정도인 것이다.
그러나 컨셉도에서는, Intel이 어떤 방향성을 가지고 있는지눈, 어느 정도까지는 보인다. 먼저 Intel이 구상하는 베이직 매니 코어 하드웨어는 다음과 같은 모습이다.
Intel 아키텍처 CPU 코어의 배열
Intel의 Tera-Scale 컴퓨팅에서는, CPU 코어의 배열은 다수의 IA (Intel Architecture) CPU 코어를 늘어 놓은 구조가 보인다. Rattner 씨는 매니코어 시대의 IA 코어는, 현재 IA 코어의 풍부한 특징을 그대로 갖는다 설명을 이전부터 했다. 이 구상은 지금도 변함 없다.

Intel의 Justin R. Rattner (저스틴 R 래트너) 씨
그러나 CPU 코어 마이크로 아키텍처 (내부 아키텍처)를 헤테로지니어스 (Heterogeneous : 이종 혼합)하는지 어떨지는 뉘앙스가 바뀌고 있다. 1년 전에는 Rattner 씨는 매니코어 세대에서는, 명령 세트 (ISA)는 균일하게 유지하면서 마이크로 아키텍쳐 적으로는 다른 코어를 집적하는 것을 시사했다.
"우리는 호모지니어스 (동종) 명령어 세트 아키텍처 (ISA)에 포커스 하고 있다. 명령 세트 혼합 아키텍처는 이미 병렬 프로그램화를 위해 복잡한 상황이 되어있는 프로그램 측에 더 불필요한 복잡성을 추가해 버린다고 생각하고 있다. 다만 호모지니어스 (ISA) 프레임 워크에서 특수화 및 최적화를 해간다. 아마 단일 명령 세트 아키텍처의 믹스드 (이종 혼재) 프로세서 코어가 될 것이다 "
이 시점에서, Intel은 대형 싱글 스레드 성능이 높은 범용 코어와 작고 효율적인 코어를 혼합 할 생각을 한 것 같다. 그러나 현재는 이러한 설명은 톤 다운해서, 애매해졌다. IA CPU 코어는 균질의 마이크로 아키텍처가 될 가능성도 있다.
다만 매니코어 시대의 CPU 코어는, 같은 범용 코어라도 싱글코어 시대의 CPU 코어와는 다르다. 멀티코어에 최적화 된 아키텍처를 갖추는 것으로, 다수의 CPU 코어로 스케러블로 성능을 늘릴 수 있게 간다고 한다.
"이들 (매니코어의 코어)은 오늘의 멀티코어 아키텍처에서 보는 것과 같은 코어는 아니다. 몇 세대 앞의 코어로 되며, 멀티 스레드 오퍼레이션에 진정 최적화 된 코어가 된다는 것"이라고 Rattner 씨는 설명 한다.
멀티 코어에 최적화 된 CPU 아키텍처의 확장으로
Rattner 씨는 아래의 그림에서 CPU 아키텍처의 개량에 의해서, 스케러블로 성능을 느는 것이 시뮬레이트 됐다고 설명했다.
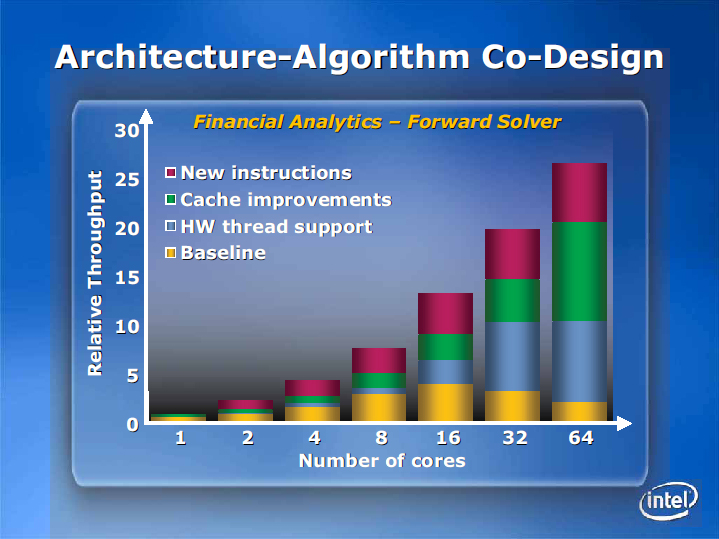
코어 수에 따른 성능 향상의 요인
그림의 가장 아래의 노란 기둥이 멀티 코어에 최적화되지 않은 CPU 코어의 경우. 이 경우는 시뮬레이션 한 재무 분석 소프트에서는 16코어를 정점으로 그 이상의 CPU 코어 수를 늘려도 성능은 올라가지 않는다. 오히려 동기화 오버헤드 등으로 성능은 반대로 떨어진다.
그런데 하드웨어 측이 명시적으로 스레드 지원을 하고, 스레드 스케줄링하면 파란 기둥처럼 32코어까지 스케러블로 성능이 올라가게 된다는 것이다. 또한 캐시의 동작을 응용 프로그램에 최적화 할 수 있도록 개선하면 64코어까지 확장성이 얻어진다. 그리고 새로운 명령 세트를 더하는 것으로, 스루풋은 한층 오른다고 Rattner 씨는 말했다.
Intel은 멀티코어화로의 CPU 아키텍처 최적화의 자세한 내용은 밝히지 않았지만, 이 그림이 나타내는 방향성은 명확하다. 그동안 CPU 아키텍처의 확장은, CPU 코어 자체의 성능 향상을 향해 왔다. 그러나 향후는 CPU 코어 단독이 아닌 멀티코어의 성능을 향상시킬 수 있는 아키텍처 개발이 초점이 된다. 코어 덩어리인 CPU 전체의 성능을 올리도록 아키텍처를 고안해 가게 될 것이다.
Intel이 이전의 Intel Developer Forum (IDF)에서 소개한 트랜잭션 메모리 (Transactional Memory)는 그 좋은 예이다. Transactional Memory는 다수의 CPU 코어가 공유 메모리에 액세스 할 때 효율적으로 액세스 할 수 있도록 한다. 복수의 CPU 코어에서 다른 스레드가 동일한 메모리 주소에 접근하면 메모리의 일관성을 유지할 수 없게 될 가능성이 있다. 따라서 기존에는 처리가 끝날 때까지 락하고, 다른 스레드에서의 액세스를 금지했다.
그러나 이 테크닉에는 확장성으로 성능을 늘릴 수 없다. 그래서 Transactional Memory에는, 필요한 데이터를 일단 가져와 트랜잭션 단위로 처리를 정리해 메모리에 전달 (Commit)하는 것으로 병렬로 처리하는 것을 가능하게 한다. 트랜잭션 간의 충돌을 감지하고 충돌한 경우에는 트랜잭션을 재시작 한다.
즉, 각 스레드는 기존과 같이 메모리 액세스 대기로 아이들이 되버리는 것이 아닌, 충돌까지 병렬로 동작 가능하다. 3월의 IDF에서 8스레드의 처리에서 Transactional Memory는 락 방식에 비해 압도적으로 유리하게 되는 것이 데모되었다. 충돌시의 리 스타트 오버헤드는 있지만, 전체에서는 확장으로 성능을 늘릴 수 있다는 것이다.
Intel은 IDF 때에는 소프트웨어 구현에 의한 Transactional Memory의 데모를 진행했지만, 최종 목표는 물론 하드웨어 구현에 있다. 소프트웨어 Transactional Memory는 40 ~ 100%의 오버 헤드를 만들기 때문이다. Transactional Memory는 Sun Microsystems도 연구하고 있으며, HotChips에서는 Intel과 Sun에서 Transactional Memory 튜토리얼이 진행됐다. Transactional Memory는 매니코어 시대의 트렌드 기술이 될 것 같다.
AMD의 코 프로세서에 비슷한 고정 기능 유닛
Intel은 매니코어 시대에는 범용 CPU 코어의 아키텍처를 매니코어를 향해 최적화 할뿐만 아니라 다양한 새로운 아키텍처를 더해 간다. Rattner 씨는 현재 보이는 매니코어 시대의 CPU 설계의 큰 과제로서 다음의 4 가지를 꼽았다.
Complex memory hierarchy
Cophisticated on-die fabrics
Explicit thread support
Fixed function acceleration

CPU 설계의 4가지 과제
여기에서 눈길을 끄는 것은 "고정 기능 유닛군 (Fixed Function Units)" 이라고 부르는 범용 CPU 코어와는 다른 유닛의 혼합 적재다. 고정 기능 유닛은 특정 처리에 특화된 하드웨어 로직으로 여기에 컴퓨팅 태스크를 작업을 배분한다. "그래픽, 미디어, 보안, 그리고 어쩌면 더 큰 네트워크 프로토콜 프로세싱 요소도 들어 올 것이다" 라고 Rattner 씨는 설명한다.
고정 기능 유닛은 AMD의 코 프로세서 구상 "Torrenza (토렌자)"에 꽤 가까운 이미지다. AMD도 미디어 프로세싱, 그래픽, 네트워크 시스템, 보안 등의 코프로세서를 Torrenza 구상의 속으로 꼽았다. 또한 고정 기능을 올리는 이유도 Intel과 AMD 모두 공통이다. 그것은 성능 / 전력 효율의 향상이다.
"우리는 특정 기능에 대해서는, 성능 / 전력면에서 생각하면, 하드웨어로 직접 실행하는 구현이 가장 적합하다고 깨달았다"고 Rattner 씨는 6월 Tera-Scale Computing의 텔레 컨퍼런스에서 설명했다.
일반적으로 프로그램성이 높은 범용 코어는 특정 워크로드에 특화된 고정 기능 유닛보다 처리 효율이 나쁘다. 그래서 범용 CPU 코어에서 비효율적인 처리는 전용 유닛으로 처리함으로써 CPU 전체의 성능 / 전력을 올려간다는 발상이다.
그러나 Rattner 씨는 6월의 시점에서는, AMD는 1 ~ 3년 정도 더 가까운 기간에 대해 구상하고, 그에 비해 Intel은 5년 이상 앞으로 더 장기적인 비전을 그리고 있다고 설명했다.

미래의 멀티 코어 아키텍처
파티셔닝과 밀접하게 얽힌 on-Die Fabric
Intel의 매니코어에, 주변 인터커넥트와 소프트웨어 컨테이너 (Container)를 더한 것이 아래의 차트이다.
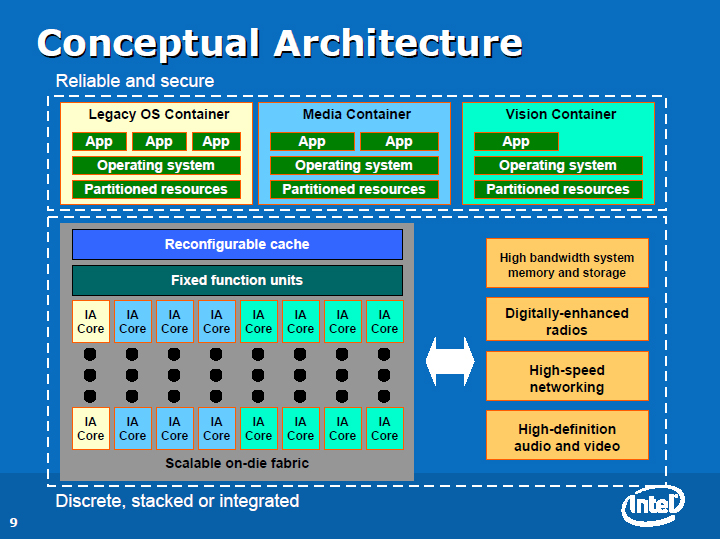
컨테이너화 된 아키텍처
Intel은 매니코어를 기본적으로 파티셔닝해서 쓰는 것을 생각하고, 소프트웨어 층도 거기에 대응하고 컨테이너화 하는 것을 구상하고 있다. 바꾸 말하면, 복수의 가상 머신 (소프트웨어 파티션)이 다수의 코어 군에서 달리는 것을 전제로 하고 있는 것이다.
현재의 가상 머신은 그 하층의 하드웨어와 연계하지 않는다. 그러나 매니코어 시대에는 1개의 가상 머신을 1개 또는 복수의 CPU 코어 군으로 구성된 하드웨어 파티션에 명시적으로 할당 되도록 된다고 한다. 위의 컨테이너 소프트웨어가, 같은 색의 IA 코어 군의 위에서 달리는 이미지다. 그리고 컨테이너 단위로 태스크를 전문화하는 것을 Intel은 생각하고 있는 것 같다.
"이 그림에서는 몇 가지 코어가, 레거시 OS와 레거시 응용 프로그램을 돌리기 위해 할당되어있다. 다른 컨테이너는 미디어 프로세싱에 특화 될지도 모른다. 또 다른 컨테이너는 데이터 검색 및 인덱스에 특화 될지도 모른다. 그림 안의 컨테이너는 3개 뿐이지만, 더 많은 파티션을 만들 수 있다 "(Rattner 씨)
파티셔닝은 매니코어 CPU의 기본적인 아키텍처에 크게 관여하고 있다.
매니 코어의 컨셉에는, 각 IA CPU 코어와 고정 기능 유닛, 메모리 인터페이스 등은 코어 간의 고속 인터커넥트인 on-Die Fabric (온다이 패브릭 : ODF)"으로 잇는다. 이 on-Die Fabric이 파티션화된 소프트웨어 컨테이너와 연계하는 것으로 보인다.
캐시는 재구성가능으로
Rattner 씨는 이전 on-Die Fabric 대해서, 코어끼리를 잇는 유연한 온다이 네트워크가 된다고하는 설명을 했다. 접속이나 절단을 자유롭게 하여, 코어를 유연하게 네트워크화 할 수 있다고 하는 의미이다.
예를 들어, 일관성을 취할 필요가 있는 코어군의 블록은, 일관된 버스에 잇고, 그 이외의 코어군과 아이솔레이트 (격리)하는 등 구성을 자유롭게 가능하게 된다는 것이다. 이것은 가상 머신을 CPU 코어 군에 할당해서, 메모리 일관성의 유지는 그 안에 한정하는 등 구성을 상정하고 있기 때문이다.
"지금의 가상 환경에서는 일관성의 제한은 없다. 왜냐하면 하층의 하드웨어는 가상 머신에 대해서 아무것도 모르기 때문이다. 그러나 미래는 가상 파티션 및 물리적 파티션 사이에서 어떤 종의 연계가 필요하게 된다고 생각한다. CPU 코어를 네트워크화 해서, 가상 파티션에 대응하고, 특정 CPU 코어군을 물리적으로 바운드 한다. 가상 파티션의 외측과는 일관성을 유지할 필요가 없다. 일관성의 유지는 CPU 코어 네트워크에 안에서, 바운드 된 코어군의 안 정도로 멈추는 것이 가능하다."라고 Rattner 씨는 2004년의 인터뷰에서 말했다.
Intel의 매니 코어 구상에서는 계층적 캐시 메모리를 상정하고 있다. 6월 전화 회의에서는, 이 캐시 메모리는 재구성 가능하게 된다고 설명했다.
"캐시는 특정 캐시 행동에 사용할 수 있도록 프로그램이 가능하게 된다. 프로그램의 특정 데이터 액세스 수법에 적합하도록 하는 것이 가능하다고 말할 수 있다. 예를 들면, 전통적인 캐시를 매우 효율적인 스트림 버퍼로 바꾸는 것도 가능해진다 것이다"
어플리케이션의 유형에 따라서, 유효한 캐시의 조직과 관리 방식도 달라진다. 예를 들어, 스트림 형의 데이터 처리의 경우에는, 전통적인 범용 CPU의 캐시 계층은 방해가 된다. 단순한 데이터를 앞서 읽는 버퍼가 가장 효과적이다. Rattner 씨의 발언은 캐시 관리 테크닉 자체를 프로그래밍 가능하게 해서, 스트림 유형의 응용 프로그램 등에도 최적화 할 수 있도록 하는 것을 시사하고 있다.
대대적인 Intel의 Tera-Scale 구상
Intel의 매니코어, 즉 Tera-Scale Computing 구상은, 아직 대략적인 윤곽 단계이지만, 방향성 만은 보인다. 범용 코어는 멀티 코어에 최적화 된 아키텍처 확장을 하고, 특정 용도의 고정 기능 유닛을 갖추고, 각 유닛을 자유롭게 네트워크화 하는 on-Die Fabric을 올리고, 재구성 가능하게 편성 가능한 캐시를 탑재한다. 꽤 대대적인 것을 Intel은 구상하고 있는 것 같다.
이만큼의 기능을 올리면 Intel의 매니 코어는 꽤 커지게 될것 같지만, 그렇지는 않다고 한다.
"다이 사이즈 (반도체 본체의 면적)는 (현재의 CPU와) 같은 정도가 될 것이다. 우리는 매우 큰 다이에 대해서 말하고 있는 것이 아니라, 매우 익숙한 크기를 생각하고 있다"고 Rattner 씨는 말한다.
물론, 이것은 Intel의 매니 코어가 5년 이상 앞을 생각하고 있기 때문으로, 공정 기술의 미세화의 혜택으로, 더 많이 다이에 실리게 된다. 즉, Intel의 매니코어는, 그만큼 최고점을 보고있다. 맞서는 AMD는 더 가까운 시기에 GPU 코어의 통합으로 내딛으로 한다. 이 차이가 어떻게 진행될지, 아직 보이지 않는다. 물론, Intel은 매니코어의 전에, 급진적 아키텍처를 발표 할 가능성도 있다.
2006년 9월 12일 기사
[분석정보] 메인 테마는 "신 아키텍처" ~ 매니코어의 메모리 기술을 공개
[분석정보] Intel, 기간 서버용 CPU 신제품 Xeon E7 v3발표
[분석정보] TSX 대응으로 약 6배로 성능 향상된 Xeon E7 v3
[분석정보] Intel 2 소켓용 Broadwell 프로세서 "Xeon E5 v4"
[분석정보] 인텔 최대 18코어 Haswell-EP Xeon E5-2600 v3
[분석정보] 전환기를 맞이한 2014년 인텔의 서버 프로세서
[분석정보] 고기능 고성능 + 에너지 절약 저비용을 양립시키는 Intel의 대처
[고전 2005.11.10] 보이는 인텔의 5~10년 후 CPU 아키텍처
[분석정보] 인텔이 추진하는 32코어 CPU Larrabee
'벤치리뷰·뉴스·정보 > 아키텍처·정보분석' 카테고리의 다른 글
| [분석정보] 미래를 지향하는 Intel의 연구 (0) | 2006.09.29 |
|---|---|
| [분석정보] 연내에 투입되어 45nm에서 보급을 노리는 Inte의 쿼드코어 (0) | 2006.09.29 |
| [분석정보] 오텔리니 CEO 기조 연설 쿼드 코어의 Core 2 Extreme 은 11월에 등장 (0) | 2006.09.28 |
| [분석정보] 래트너 CTO 기조 강연 보고서 차세대 데이터 센터 기술을 소개 (0) | 2006.09.28 |
| [분석정보] 심플 코어로 향하는 차세대 CPU 아키텍처 (0) | 2006.08.21 |
| [분석정보] 결정된 헤테로지니어스 멀티코어에 대한 기류 (0) | 2006.08.18 |
| [분석정보] AMD와 ATI 프로세서는 하나로 융합한다 (0) | 2006.07.25 |
| [아키텍처] Core Microarchitecture 속도의 비밀은 CISC의 아름다움 (0) | 2006.06.26 |